最近对Re-ID比较感兴趣,读了一篇关于Re-ID的文章,作为自己学习的一个记录,有说的不正确的地方欢迎大家指正,也希望大家一起共同学习共同进步!!!
github:https://github.com/zhangguiwei610/PHA
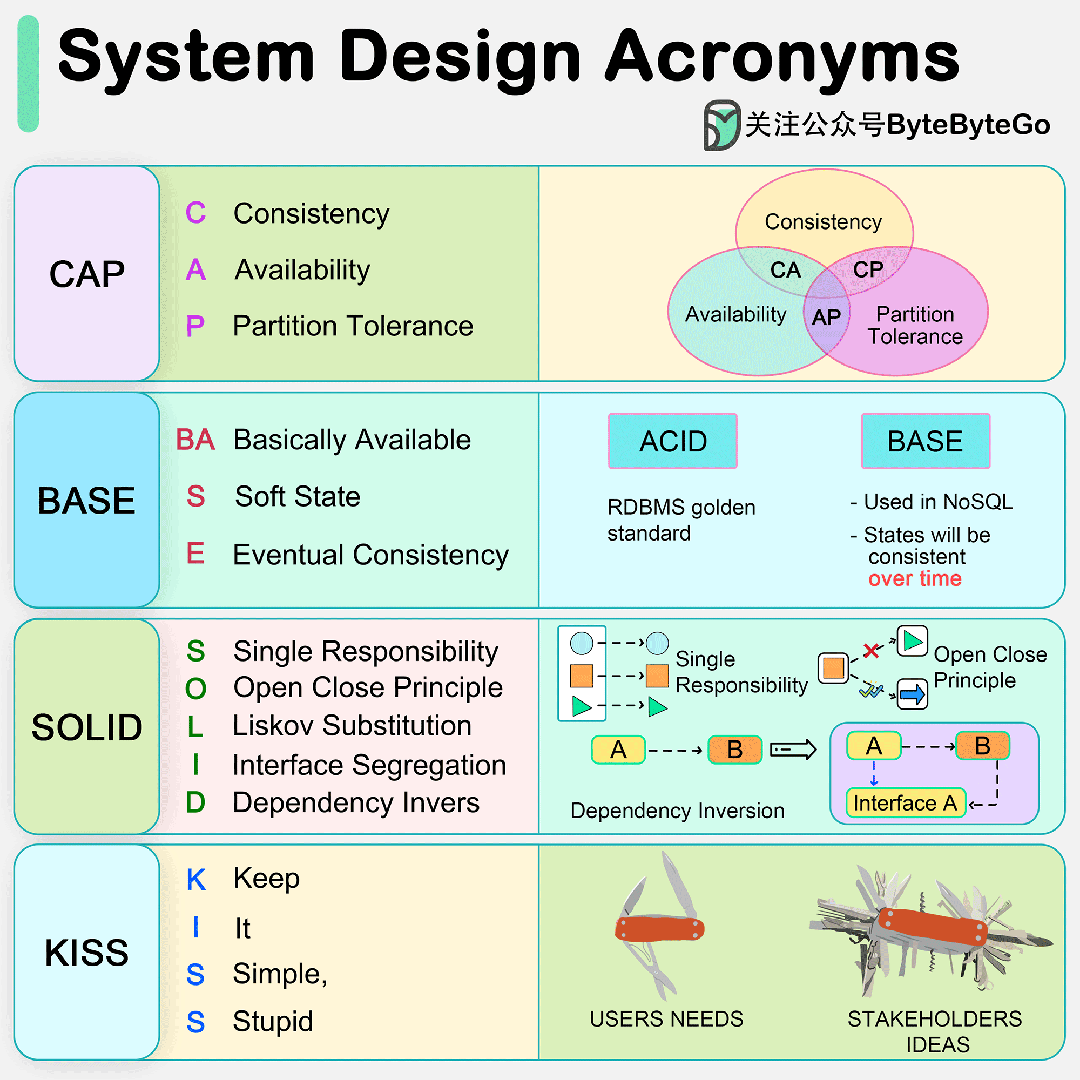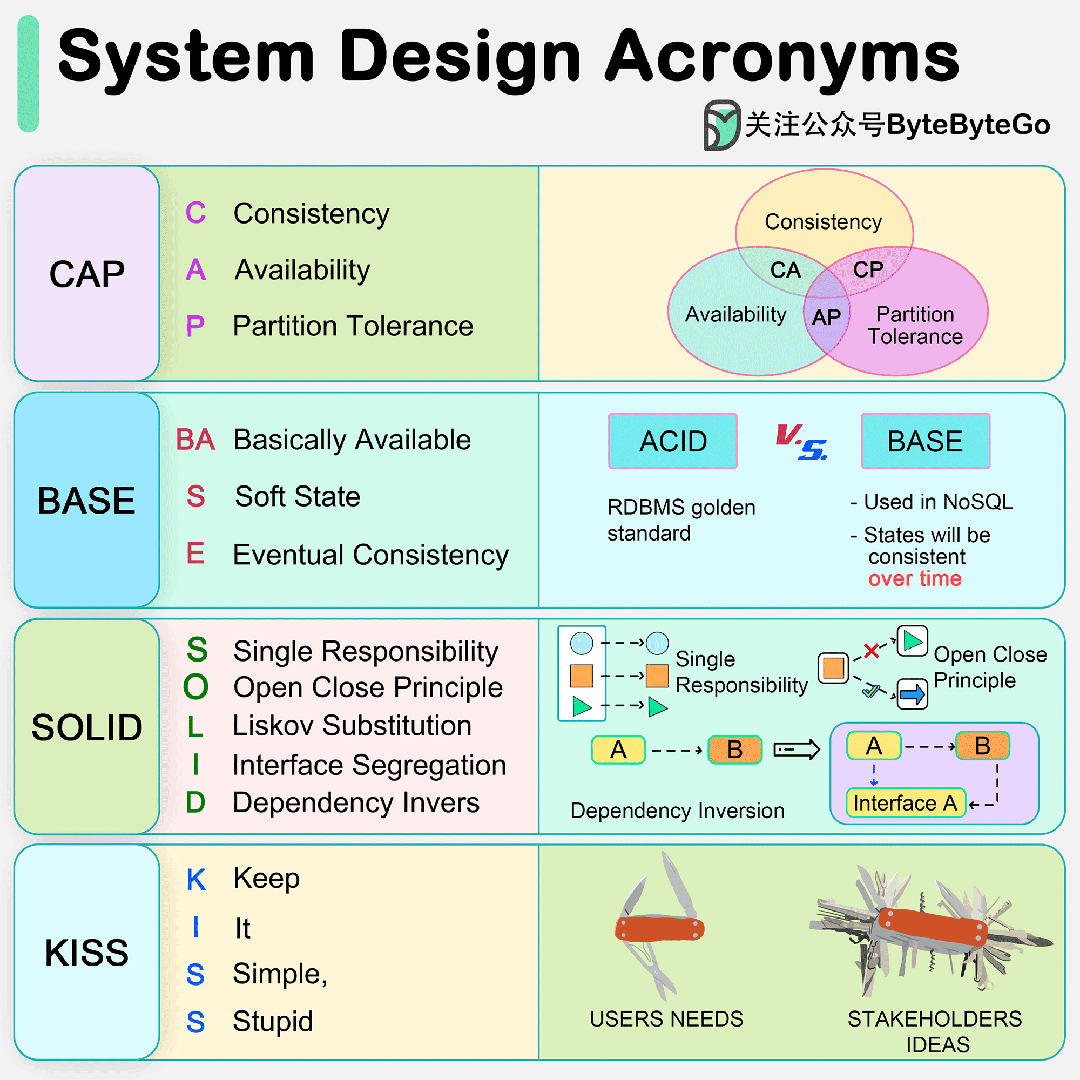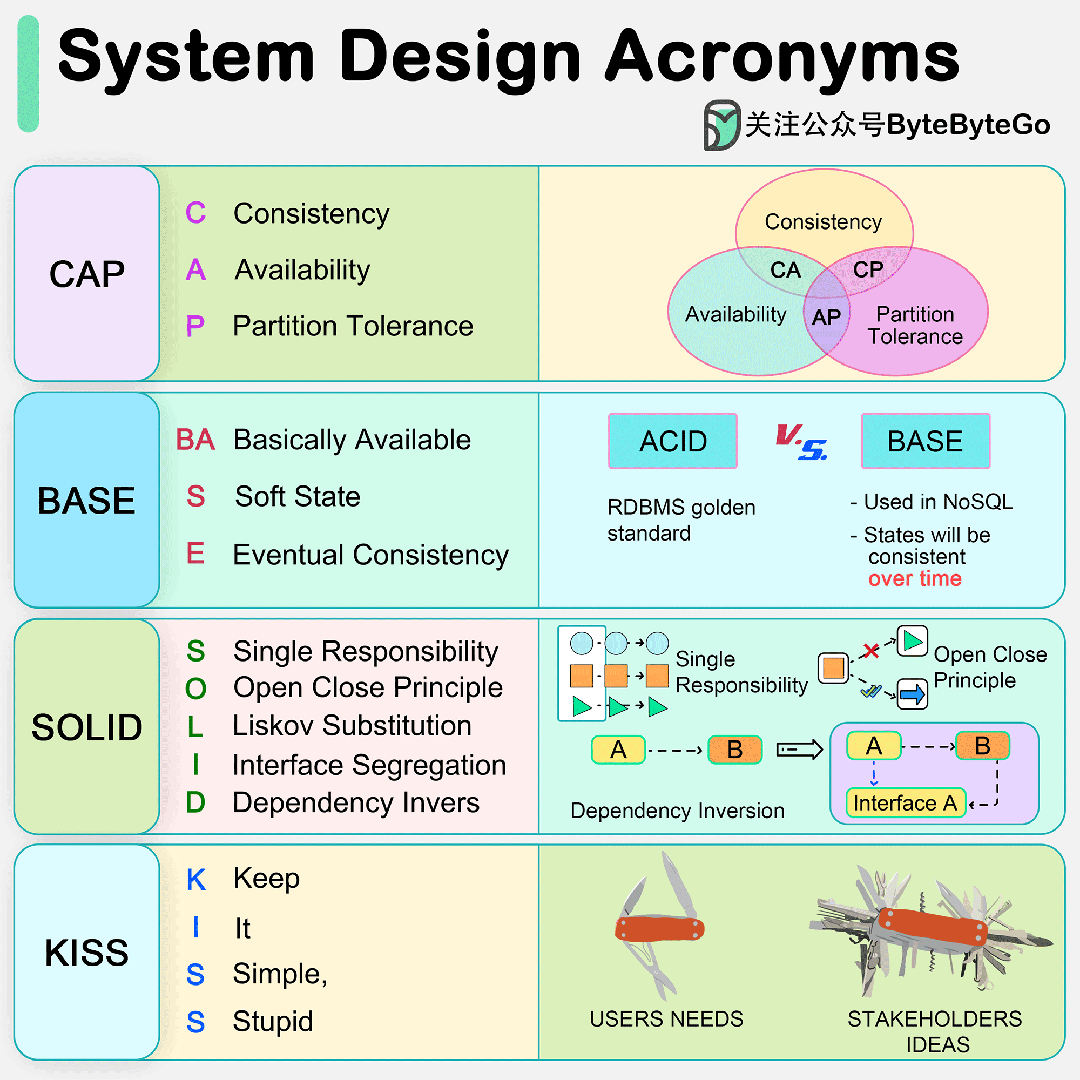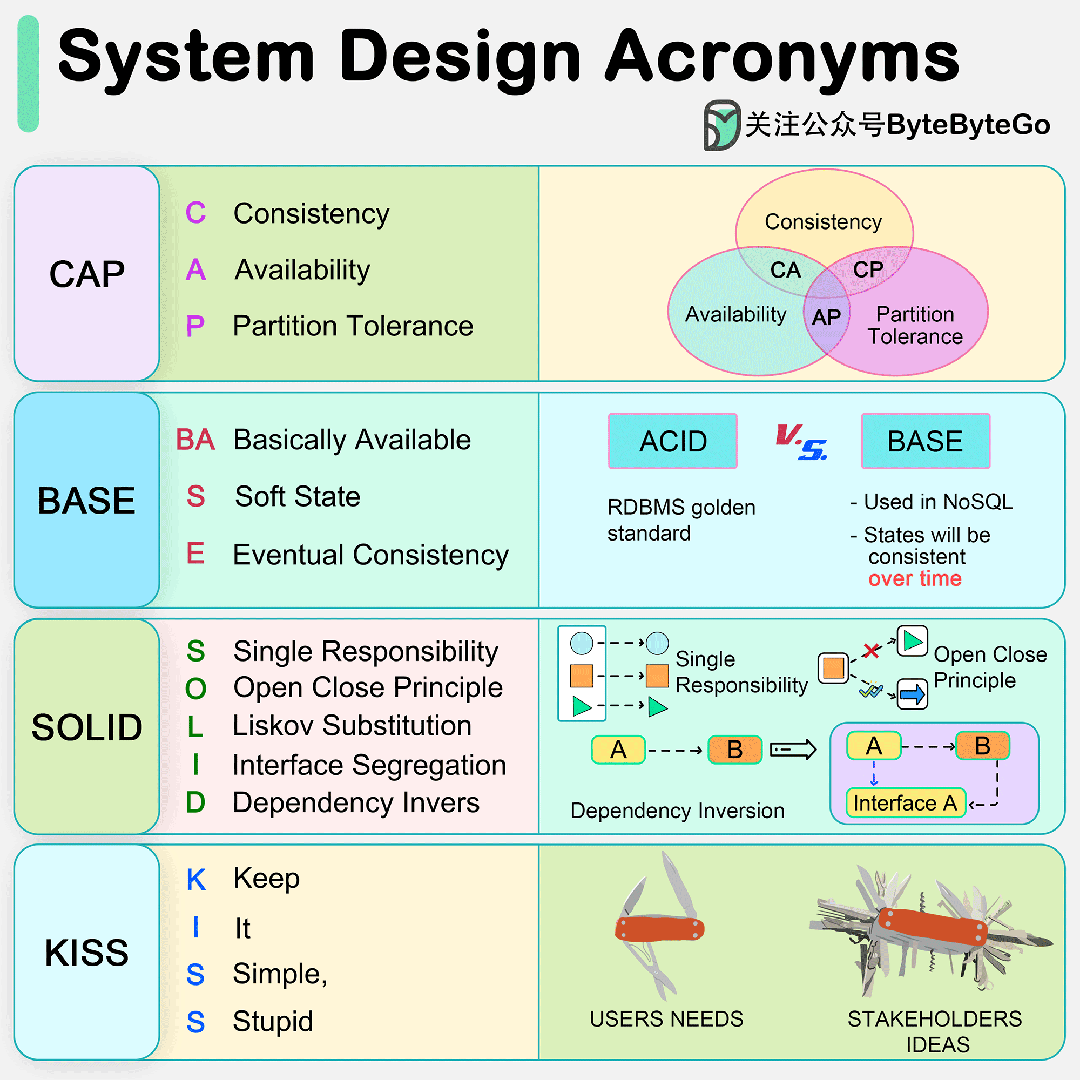
1. Abstract
挖坑(提出问题):自从这个VIT应用在reid领域,效果显著,比CNN要好,但是呢在High-frequency信息呢CNN的效果是优与VIT的,比如这个衣服的纹理细节,因为这个VIT 的Self-Attention机制会利用low-frequency信息把High-frequency信息“稀释”掉。由于这个纹理细节对于reid来说十分重要,所以不能没有High-frequency,就想西方不能失去耶路撒冷(这句不是作者说的,是我说的~)
填坑(解决问题):提出了一个网络叫做PHA,这个网络有两个好处:
首先,提高High-frequency信息表达能力,其次,防止low-frequency信息把High-frequency信息“稀释”掉。同时呢这个PHA在训练时候使用在inference阶段就无须使用。
2. Introduction
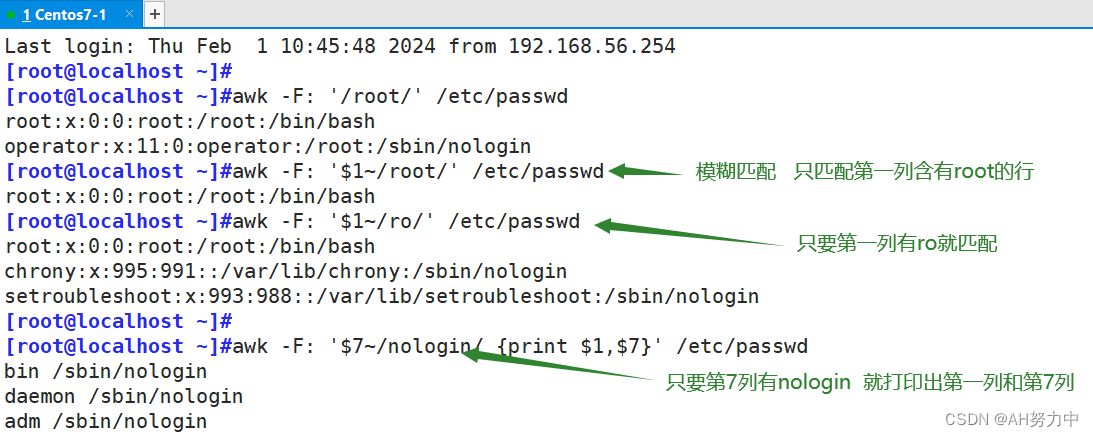
为了说明上述问题,作者把输入图像进行了图像离散小波变换(Discrete Wavelet Transform)【图像处理】图像离散小波变换(Discrete Wavelet Transform)及python代码实现-CSDN博客
将图像转换为 low-frequenc图像和High-frequency图像,同时在resnet和TransReid上实验结果如下图所示

实验结果证明了两件事:
(1)图片的纹理细节信息对于REID任务来说是至关重要的(a)(b)对比
(2)在High-frequency图片中,resnet优于transreid(c)
3. Method
3.1 Self-Attention对frequency的影响分析
作者为了分析frequency对自注意力的影响,作了一系列操作:
a. 利用DHWT对图像进行转换,生成四个级别图片
![]()
将![]() 视为low-frequency信息,所以舍去
视为low-frequency信息,所以舍去
b. cat操作,这样结果就是带有高频信息的图片
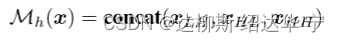
c. 对b的结果进行downsampling and flattening和l2范数操作,并将前top-k的结果放到一个集合代表高频信息
d. 这样原来的(q*k)*v就分成了两部分:转化后的z分成两两部分,前半部分代表高频信息,后半部分代表低频信息。

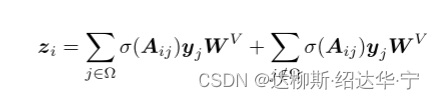
e. 经过上述操作的p再添加class信息和position emveddings进入VIT的encoder
f. 作者设计了一个函数用于判断高频信息和低频信息经encoder后提取特征的相似性
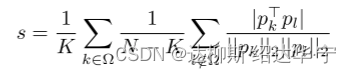
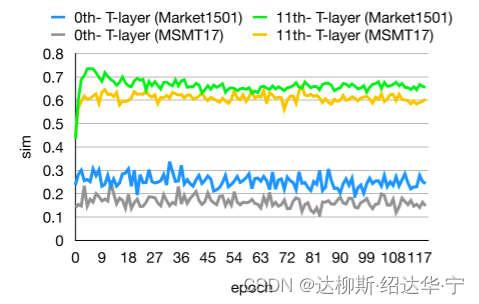
h. 结果如图所示,下图结果证明,随着encoder层数的加深,高频信息和低频信息相似度逐渐增加,也就是证明,由于注意力的存在,低频信息在不断影响高频信息,最后两者变得相似(正所谓成也萧何,败也萧何,自注意力的成功就在于此)
作者经过上述实验证明了自注意力会使高频信息被低频信息稀释
3.2. Patch-wise High-frequency Augmentation
为了解决这个问题,作者设计了如下网络
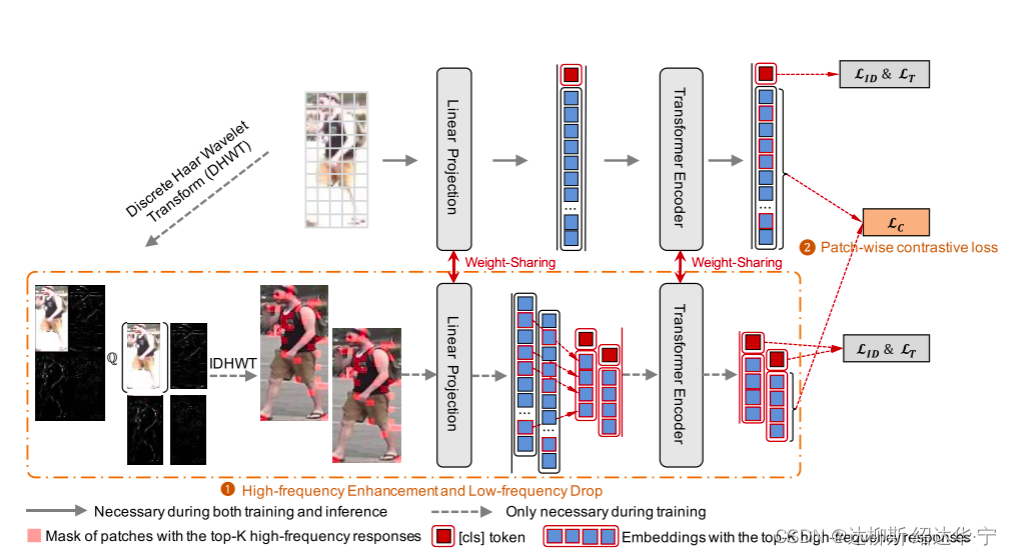
网络主要包含两个模块:(1)High-frequency enhancement and low-frequency drop(高频增强,低频舍弃)(2)a novel patch-wise contrastive loss(patch-wise对比损失)
(1)High-frequency enhancement and low-frequency drop(高频增强,低频舍弃)
我们依旧是采用上文的方法按步骤分析:
a.首先使利用DWHT将图片分解,得到如同上文4个级别图片
b. 利用下图公式,对低频特征进行drop

c. 再将去除低频的图片进行复原,复原后的图像肉眼观看没有差异但对VIT来说是十分重要的

d.和传统VIT相同的操作得到带有class token 和position embeddings的向量y
![]()
e. 对y进行采样,利用上文中的方法筛选出带有高频信息的y 进入encode,输出如下:

f. 另外不对y进行处理,直接进入encode
![]()
g. 对e和f生成的p_class和p_h_class一个代表全局信息,一个代表高频增强全局信息二者作ID loss
和triplet loss
最终训练的模型专注于高频信息,增强了对高频信息的提取能力
(2)a novel patch-wise contrastive loss(patch-wise对比损失)
为了防止随着encode 层数加深导致的高频信息消失,作者设计了像素级对比损失
在完成上文中的a-f步骤后,得到的![]() 和
和![]() 分别代表全局信息和高频增强信息,作者的目标是拉近相同id中的全局信息中属于高频的信息和高频增强信息的距离,并拉远不同ID信息的距离
分别代表全局信息和高频增强信息,作者的目标是拉近相同id中的全局信息中属于高频的信息和高频增强信息的距离,并拉远不同ID信息的距离
作者是如何做到的呢?请听我细细道来
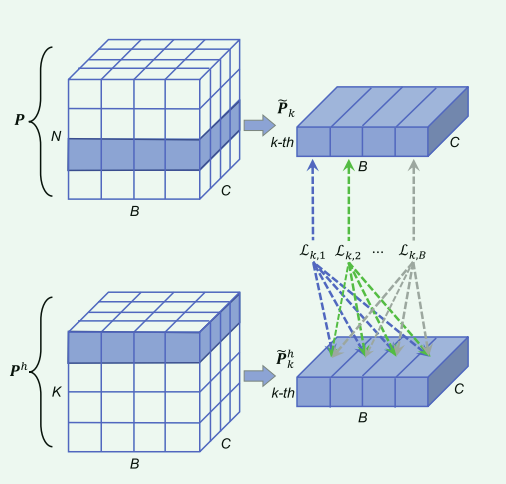
正如上图所示,两个立方体分别代表 ![]() 和
和![]() ,两者的区别就是N和K 维度不同,因为一个是全局信息(包含高频信息和低频信息),一个是高频信息。接下来找到他们对应的第k维度,也就是代表对应高频信息,对他么去做对比损失。(损失函数下文中解释)
,两者的区别就是N和K 维度不同,因为一个是全局信息(包含高频信息和低频信息),一个是高频信息。接下来找到他们对应的第k维度,也就是代表对应高频信息,对他么去做对比损失。(损失函数下文中解释)
首先经Batch分成多个mini-batch,如上图分成了4个,在不同mini-batch中去做损失,这样就有了相同ID和不同ID 的对比。
损失函数
这个损失函数如下图所示,这个损失函数求出了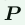 和
和 的相似度(或者说是距离)结果记为
的相似度(或者说是距离)结果记为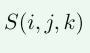
再分别计算二者具有相同ID的和不同ID的并使相同ID拉近,不同ID拉远
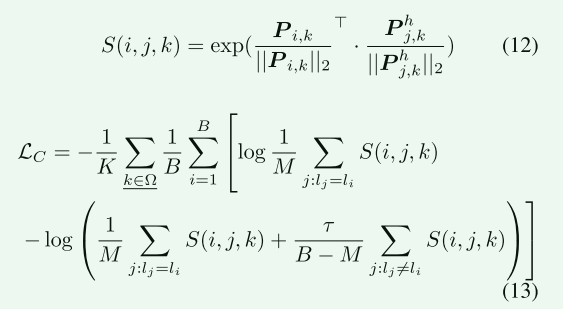
最后作者强调:提出的PHA方法仅在训练期间是必要的,可以在推理期间丢弃,而不会带来额外的复杂性。
至此,网络结构的大体部分已经解读完毕
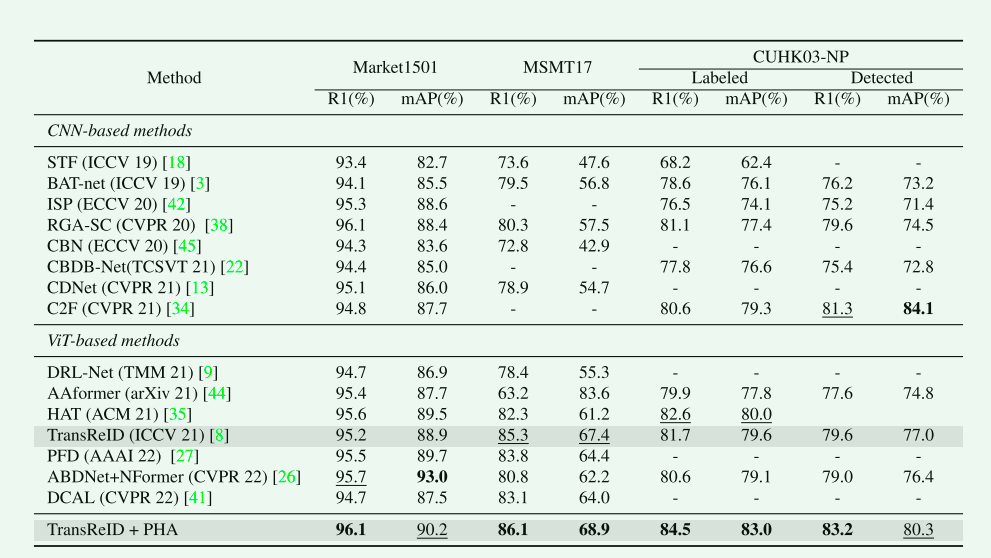
4. Experiments