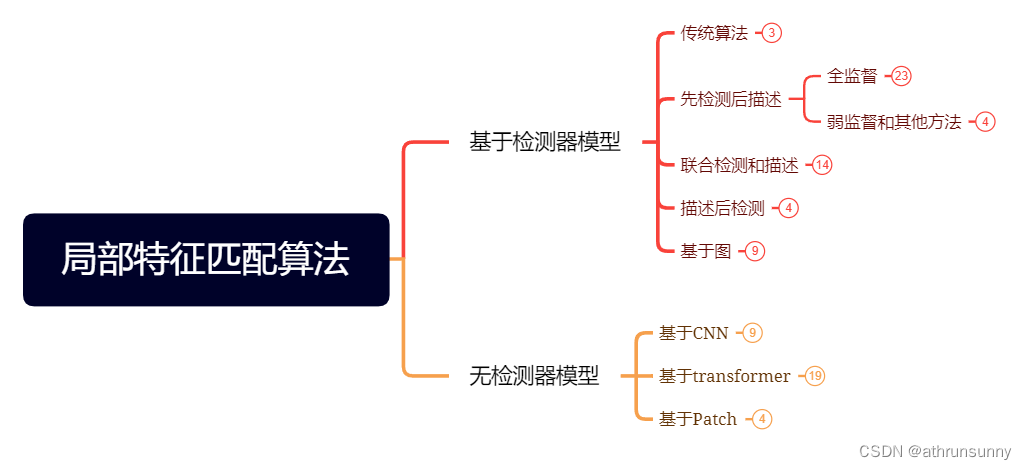
一、引言
论文: OmniGlue: Generalizable Feature Matching with Foundation Model Guidance
作者: Google Research
代码: OmniGlue
注意: 该方法使用SuperPoint和DINOv2获取关键点、描述符、特征图,在学习该方法前建议掌握关键点检测方法SuperPoint和自监督学习方法DINO、iBOT。
特点: 使用冻结的SuperPoint和经DINOv2预训练的ViT-B/16获取关键点、描述符、特征图;以特征图为指导构建图像内、图像间的连接图;以连接图为依据进行mask并依次执行自注意力、交叉注意力来优化描述符;对优化后的描述符计算两两之间的相似度确认特征匹配。
二、框架
OmniGlue的整体流程包括如下四个部分:

2.1 提取关键点、描述符、特征图
该部分流程图如下:

可见,对于两张同物体不同视角的待匹配图片 I A I_A IA和 I B I_B IB,OmniGlue使用冻结的SuperPoint和经DINOv2预训练的ViT-B/16提取关键点、描述符、特征图。
SuperPoint被用来提取关键点和描述符,详情请参考我之前的博客SuperPoint。
关键点以归一化的坐标形式呈现,即 ( x , y ) (x,y) (x,y)。 待匹配的两张图片中所提取的关键点坐标集被分别定义为 A = { A 1 , A 2 , ⋯ , A N } \mathbf{A}=\{A_1,A_2,\cdots,A_N\} A={A1,A2,⋯,AN}和 B = { B 1 , B 2 , ⋯ , B M } \mathbf{B}=\{B_1,B_2,\cdots,B_M\} B={B1,B2,⋯,BM}, N N N和 M M M通常不等。归一化的关键点坐标经过位置编码形成坐标向量,再经过一个 MLP \text{MLP} MLP形成位置特征,定义为 p ∈ R C \mathbf{p}\in\mathbb{R}^C p∈RC。
描述符是从两张图片经SuperPoint得到的预测特征图中按照关键点坐标抽取出的特征。 可以直接定义为 d ∈ R C \mathbf{d}\in\mathbb{R}^C d∈RC。
经DINOv2预训练的ViT-B/16被用来提取特征图,DINOv2是一种自监督学习预训练方法,是在DINO和iBOT的改进,详情请参考我之前的博客DINO和iBOT。ViT是经典的视觉backbone,详情也可参考我之前的博客ViT-B/16。
所提取的特征图同样按照关键点坐标抽取出特征,我们称其为DINO特征,定义为 g ∈ R C ′ \mathbf{g}\in\mathbb{R}^{C^{\prime}} g∈RC′。可见ViT和SuperPoint输出的特征维度可以不同。
于是,两张待匹配的图片 I A I_A IA和 I B I_B IB经上述操作得到关键点坐标 A \mathbf{A} A和 B \mathbf{B} B、位置特征 p A \mathbf{p}^A pA和 p B \mathbf{p}^B pB、描述符 d A \mathbf{d}^A dA和 d B \mathbf{d}^B dB、DINO特征 g A \mathbf{g}^A gA和 g B \mathbf{g}^B gB,分别有 N N N和 M M M个。
2.2 构建图像内、图像间的连接关系图
该部分流程图如下:

可见,SuperPoint的描述符被用来构建两张图像内的连接关系图和两张图像间的连接关系图。其中图像间的关系连接图是以DINO特征为指导构建的。
两个描述符是否有连接影响的是后面更新描述符时注意力机制的执行过程,无连接时输入注意力模块中的mask对应值应该为1,从而阻挡信息的传递。
图像内的关系连接图其实就是图片中SuperPoint的所有描述符两两相连,连接是双向的。 于是,可以形成两张图像内的关系连接图,定义为 G A \mathbf{G}_A GA和 G B \mathbf{G}_B GB。
图像间的关系连接图表达的是两张图片间描述符的连接关系,连接是单向的。 下图为图 I A I_A IA中关键点 A i A_i Ai处的描述符 d i A \mathbf{d}_i^A diA和 I B I_B IB中所有描述符的连接关系:

可见,经过修剪后图 I B I_B IB中只有半数的描述符会保留与描述符 d i A \mathbf{d}_i^A diA的连接关系。
修剪是以DINO特征相似度为指导进行的。 例如,对于图 I A I_A IA中关键点 A i A_i Ai来说,该处的DINO特征为 g i A \mathbf{g}_i^A giA, g i A \mathbf{g}_i^A giA会与图 I B I_B IB中所有DINO特征 g B \mathbf{g}^B gB计算相似度,相似度排名在前50%的DINO特征所对应的描述符会保留与 d i A \mathbf{d}_i^A diA的连接,该连接记作 G B → A i \mathbf{G}_{B\rightarrow A_i} GB→Ai。
⚠️ DINO特征仅用作相似度计算,并不参与后续其它过程。
图 I A I_A IA和图 I B I_B IB中所有描述符 d A \mathbf{d}^A dA和 d B \mathbf{d}^B dB均经过上述修剪过程即可形成完整的图像间的关系连接图,即 G B → A \mathbf{G}_{B\rightarrow A} GB→A和 G A → B \mathbf{G}_{A\rightarrow B} GA→B。
2.3 描述符更新
该部分流程图如下:

可见,更新过程主要是 N N N次双分支的自注意力与交叉注意力的堆叠。两个分支中注意力模块的权重共享。
G A \mathbf{G}_A GA和 G B \mathbf{G}_B GB首先各自经过自注意力,然后分别送入交叉注意力(每个交叉注意力的输入都有两个,即 G A \mathbf{G}_A GA和 G B \mathbf{G}_B GB经自注意力后的输出)。自注意力与交叉注意力的详情请参考我之前的博客注意力机制。
下式为OmniGlue所使用的注意力公式,以 G B → A i \mathbf{G}_{B\rightarrow A_i} GB→Ai为例:

其中,
(5)与标准的注意力公式一样,都是对 V V V进行一次全连接映射,不过这里被映射的只有 G B → A i \mathbf{G}_{B\rightarrow A_i} GB→Ai中保留的描述符;
(3)-(4)分别表示对 Q Q Q和 K K K的全连接映射, Q Q Q是 d i A \mathbf{d}_i^A diA, K K K与 V V V一样,不过映射前 Q Q Q和 K K K都加上了位置特征(关键点坐标经位置编码和MLP映射后所得)。
(2)与标准的注意力公式一样,根据 Q Q Q和 K K K的相似度加权 V V V。
(1)通过(2)得到新的描述符 Δ d i A \Delta\mathbf{d}_i^A ΔdiA, Δ d i A \Delta\mathbf{d}_i^A ΔdiA与输入的 d i A \mathbf{d}_i^A diA拼接在一起后经MLP映射回原长度再与 d i A \mathbf{d}_i^A diA相加得到最新的描述符。
Δ d i A \Delta\mathbf{d}_i^A ΔdiA的注意力计算过程如下图所示:

可见,该部分就是堆叠自注意力和交叉注意力来更新描述符。
⚠️ 自注意力是对图内所有描述符进行计算,但交叉注意力计算时会输入mask,仅对2.2节中保留的描述符进行交互计算。
2.4 描述符匹配
该部分流程图如下:

可见,匹配过程会根据相似度最终确定相互匹配的关键点,输出相互匹配的关键点坐标和相似度。
更新后的描述符两两之间计算相似度,然后取出同时为最佳匹配的结果作为最终输出。计算相似度之前需要将描述符归一化。
最佳匹配的确定过程如下:

表格为图片 I A I_A IA和 I B I_B IB中描述符两两之间的相似度矩阵,分别取行列的最大单元,如果该单元同时为所在行和列的最大值,则它所对应的两个描述符是最佳匹配,对应的关键点应该被匹配,对应的值为匹配置信度。