目录
2.下载Spark并确保hadoop用户对Spark目录有操作权限
一、版本信息
虚拟机产品:VMware® Workstation 17 Pro 虚拟机版本:17.0.0 build-20800274
ISO映像文件:ubuntukylin-22.04-pro-amd64.iso
Hadoop版本:Hadoop 3.1.3
JDK版本:Java JDK 1.8
Spark版本:Spark 3.2.0
Kafka版本:kafka_2.11-0.10.1.0
前面的2.11就是该Kafka所支持的Scala版本号,后面的0.10.1.0是Kafka自身的版本号
这里有我放的百度网盘下载链接,读者可以自行下载:
链接:https://pan.baidu.com/s/121zVsgc4muSt9rgCWnJZmw
提取码:wkk6
也可去Kafka官网进行下载:Apache Kafka
注意:其中的ISO映像文件为ubuntukylin-16.04.7版本的而不是22.04版本,22.04版本内存过大无法上传,见谅!!!
附上Ubuntu Kylin(优麒麟)官网下载:优麒麟 (ubuntukylin.com) 读者可以前去官网下载ISO映像文件
现附上相关资料,读者可通过这些资料来查看自己的Spark与其他组件(例如JDK,Hadoop,Yarn,Hive,Kafka等)的兼容版本、Spark Streaming + Kafka 集成指南、Kafka清华源镜像下载地址等:
1. 查看Spark与Hadoop等其他组件的兼容版本
2. Github中Spark开源项目地址
apache/spark: Apache Spark - A unified analytics engine for large-scale data processing (github.com)![]() https://github.com/apache/spark3. Spark Streaming + Kafka 集成指南
https://github.com/apache/spark3. Spark Streaming + Kafka 集成指南
Index of /apache/kafka (tsinghua.edu.cn)![]() https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/
https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/
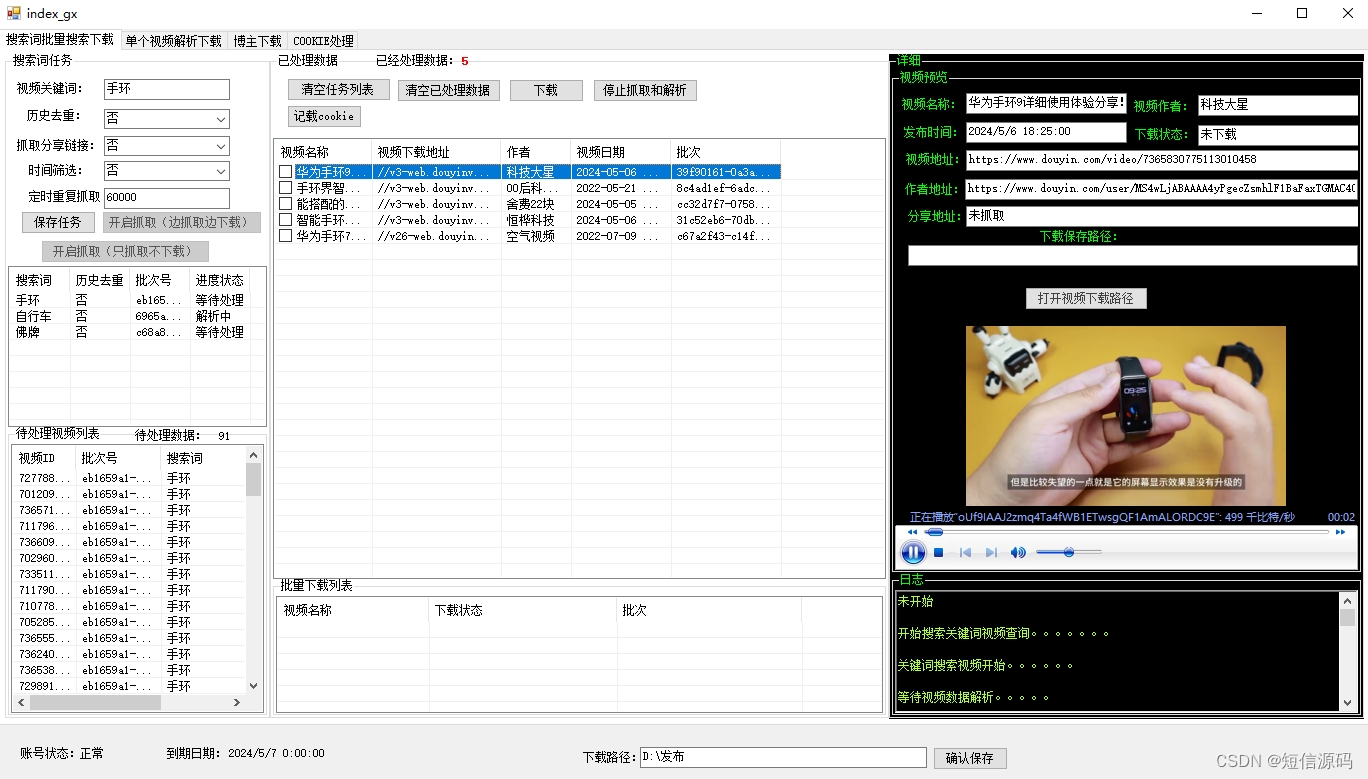
二、安装Kafka
1.将Kafka安装包移到下载目录中
将物理机上下载的Kafka安装包拖拽到读者虚拟机Ubuntu系统家目录中的下载目录中(安装包内已经附带zookeeper,不需要额外安装zookeeper):

2.下载Spark并确保hadoop用户对Spark目录有操作权限
sudo tar -zxf ~/下载/kafka_2.11-0.10.1.0.tgz -C /usr/local
cd /usr/local
sudo mv kafka_2.11-0.10.1.0/ ./kafka
sudo chown -R hadoop ./kafka # 此处的 hadoop 为你的用户名sudo tar -zxf ~/下载/kafka_2.11-0.10.1.0.tgz -C /usr/local:
- 使用
sudo权限解压缩并解包 Kafka 压缩包文件kafka_2.11-0.10.1.0.tgz -zxf参数表示使用 gzip 解压缩,并且是解包操作~/下载/kafka_2.11-0.10.1.0.tgz是 Kafka 压缩包的路径-C /usr/local指定了解压缩后的文件应该放置的目标路径为/usr/local
cd /usr/local:
- 切换当前工作目录到
/usr/local
sudo mv kafka_2.11-0.10.1.0/ ./kafka:
- 使用
sudo权限将 Kafka 解压后的文件夹kafka_2.11-0.10.1.0重命名为kafka ./kafka意味着将文件夹移动到当前目录下,也就是/usr/local目录
sudo chown -R hadoop ./kafka:
- 使用
sudo权限递归地更改kafka文件夹及其所有子文件和子文件夹的所有者为hadoop用户 -R参数表示递归地更改权限

至此,Kafka安装完成,下面在Ubuntu系统环境下测试简单的实例
三、启动Kafka并测试Kafka是否正常工作
1.启动Kafka
打开第一个终端,输入下面命令启动Zookeeper服务:
cd /usr/local/kafka
./bin/zookeeper-server-start.sh config/zookeeper.properties千万不要关闭这个终端窗口,一旦关闭,Zookeeper服务就停止了(Kafka工作运行完毕后不再使用时再关闭)

打开第二个终端,然后输入下面命令启动Kafka服务:
cd /usr/local/kafka
bin/kafka-server-start.sh config/server.properties千万不要关闭这个终端窗口,一旦关闭,Kafka服务就停止了(Kafka工作运行完毕后不再使用时再关闭)

2.测试Kafka是否正常工作
再打开第三个终端,然后输入下面命令创建一个自定义名称为“wordsendertest”的Topic:
cd /usr/local/kafka
./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic wordsendertest
#可以用list列出所有创建的Topic,验证是否创建成功
./bin/kafka-topics.sh --list --zookeeper localhost:2181- kafka-topics.sh:Kafka 提供的命令行工具,用于管理 Kafka 主题(topics)
- --create:指示命令要创建一个新的主题
- --zookeeper localhost:2181:指定ZooKeeper 的连接地址,Kafka 使用 ZooKeeper 来管理集群的状态信息。在此,localhost:2181 表示 ZooKeeper 运行在本地主机上,端口号为2181
- --replication-factor 1:指定主题的副本因子(replication factor),即该主题的每个分区的数据将被复制到几个副本中。这里设置为1,表示每个分区只有一个副本
- --partitions 1:指定主题的分区数。分区用于将主题的数据分散存储和处理,可以提高性能和扩展性。这里设置为1,表示只有一个分区
- --topic dblab:指定要创建的主题的名称,这里命名为 "dblab"。 在本地主机上创建一个名为 "dblab" 的 Kafka 主题,该主题具有1个副本因子和1个分区

下面用生产者(Producer)来产生一些数据,请在当前终端(记作“数据源终端”)内继续输入下面命令:
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic wordsendertest- - kafka-console-producer.sh: Kafka 提供的命令行工具,用于在控制台上向 Kafka 主题发送消息
- --broker-list localhost:9092:指定Kafka 集群的 broker 地址列表,用于指定消息要发送到哪个 Kafka 集群。在此,localhost:9092 表示 Kafka 集群的一个 broker 运行在本地主机上,端口号为9092
- --topic dblab:指定要发送消息的目标主题,这里是 "dblab"。 在本地主机上向名为 "dblab" 的 Kafka 主题发送消息
上面命令执行后,就可以在当前终端内用键盘输入一些英文单词(也可以等消费者启用后再输入)
现在可以启动一个消费者(Consumer),来查看刚才生产者产生的数据。请另外打开第四个终端,输入下面命令:
cd /usr/local/kafka
./bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic wordsendertest --from-beginning- - kafka-console-consumer.sh:Kafka 提供的命令行工具,用于在控制台上消费 Kafka 主题的消息
- --zookeeper localhost:2181:指定了 ZooKeeper 的连接地址,Kafka 使用 ZooKeeper 来管理集群的状态信息。在此,localhost:2181 表示 ZooKeeper 运行在本地主机上,端口号为2181。尽管在较新的 Kafka 版本中,已经不再需要指定 ZooKeeper 地址,而是直接连接到 Kafka broker,但是一些旧版本的命令仍然需要指定
- --topic dblab:指定要消费消息的目标主题,这里是 "dblab"
- --from-beginning:指示消费者从该主题的起始位置开始消费消息,而不是从当前最新的消息开始消费。 从名为 "dblab" 的 Kafka 主题消费消息,并从起始位置开始消费
可以看到,屏幕上会显示出如下结果,也就是刚才在另外一个终端里面输入的内容(启动消费者后亦可在生产者中输入内容,消费者终端也可查看到)

-> 实例运行结束后可以Ctrl+Z停止进程 ~~~