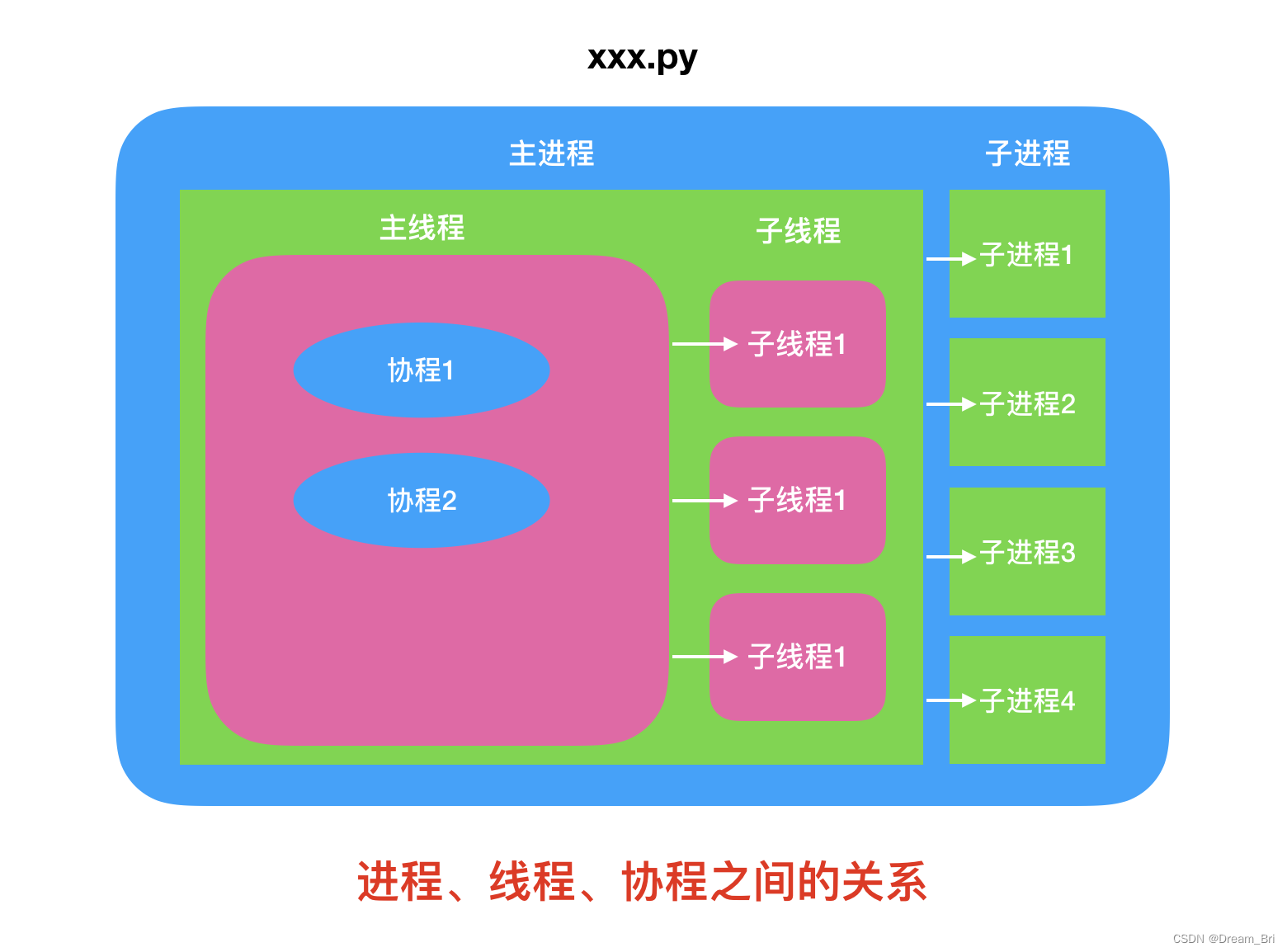
什么是线程
cpu调度的最小单位,比如qq,一个聊天窗口就是一个线程。
设置守护线程
设置守护线程的原因,当主线程结束后,子线程可能还没有结束,就会导致资源的浪费,可以设置子线程为守护线程,当主线程结束后,子线程也必须结束
daemon的值为True时子线程为守护线程
Pro1 = threading.Thread(target=sing, daemon=True, args=(3,))
设置主线程等待子线程结束
设置主线程等待子线程的呃原因,当主线程结束后,子线程分配的任务还没有执行完成,主线程要等待子线程执行结束
Pro1.join()
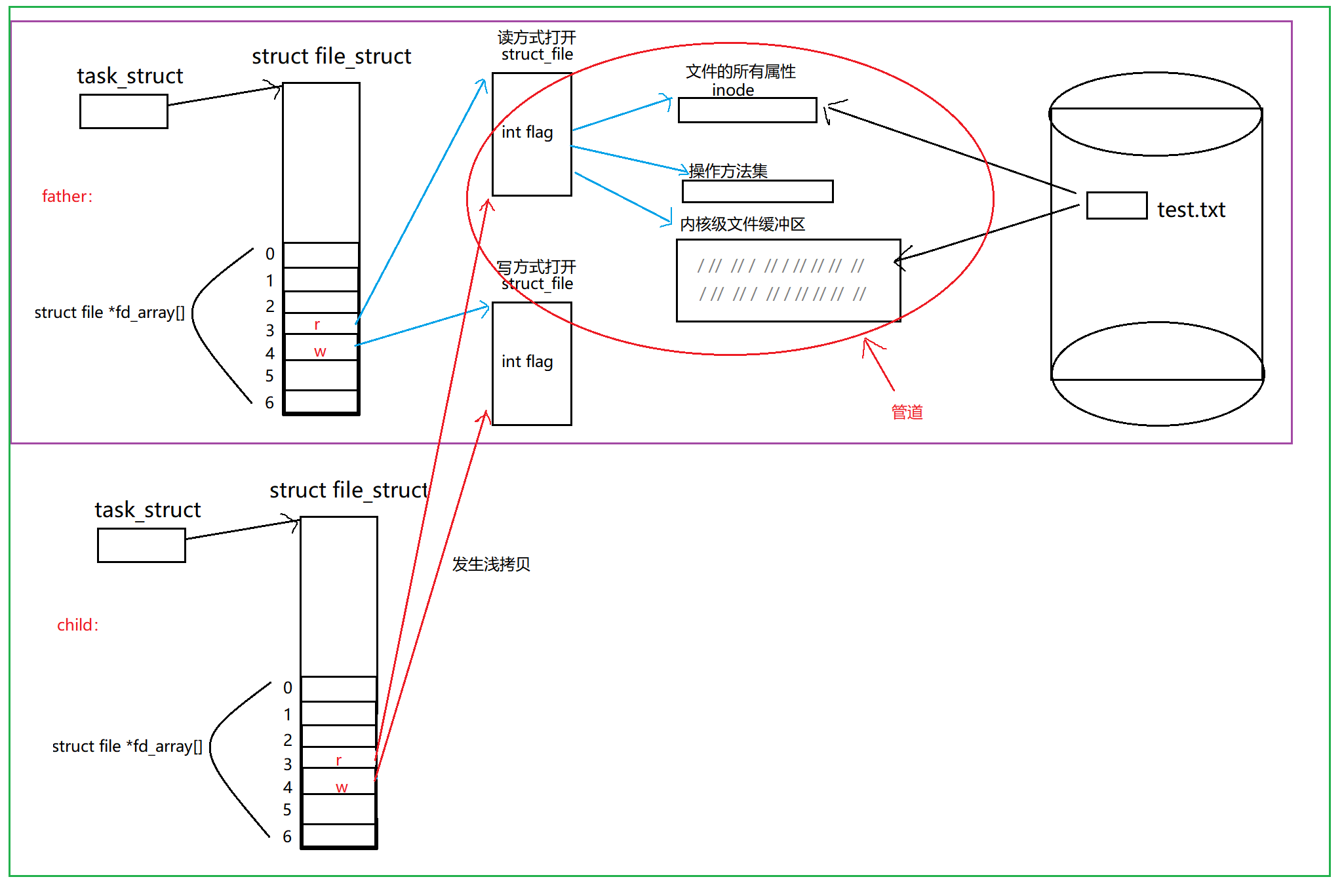
互斥锁
当多个线程几乎同时修改一个共享数据的时候,需要进行同步控制。互斥锁分为同步锁和异步锁
互斥锁工作原理
某个线程要更改共享数据时,先将其锁定,此时资源的状态为”锁定“,其他线程不能更改;知道该线程释放资源,将资源状态变为”非锁定“,其他线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行读写操作,从而保证了多线程情况下数据的正确性
# 创建锁
mutex = threading.Lock()
# 锁定
mutex.acquire()
# 释放
mutex.release()创建一个多线程程序
import threading
import time
def sing(num):
for i in range(num):
print("唱歌.....")
time.sleep(0.5)
def dance(num):
for i in range(num):
print("跳舞.....")
time.sleep(0.5)
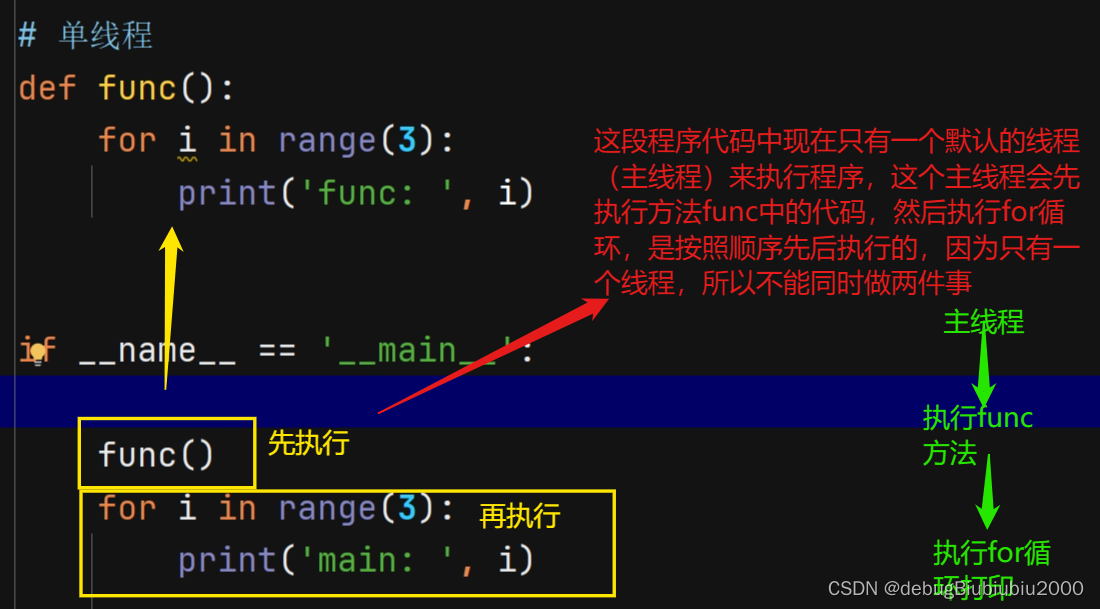
if __name__ == "__main__":
# 设置子线程守护主线程,当主线程结束后该子线程也结束
Pro1 = threading.Thread(target=sing, daemon=True, args=(3,))
Pro2 = threading.Thread(target=dance, daemon=True, kwargs={"num": 3})
Pro1.start()
Pro2.start()
print("主线程结束了")
使用多线程实现文件拷贝
import threading
import os
def copy_file(file_name, source_dir, dest_dir):
source_path = source_dir + "\\" + file_name
dest_path = dest_dir + "\\" + file_name
# 线程的执行顺序是不固定的,是由cpu进行调度的
print(source_path, "----->", dest_path)
with open(source_path, "rb") as source_file:
with open(dest_path, "wb") as dest_file:
while True:
file_data = source_file.read(1024)
if file_data:
dest_file.write(file_data)
else:
break
if __name__ == "__main__":
source_dir = "D:\\PycharmProjects\\TextProject\\视频"
dest_dir = "D:\\PycharmProjects\\TextProject\\Text"
try:
os.mkdir(dest_dir)
except:
print("目标文件夹已存在")
file_list = os.listdir(source_dir)
for file_name in file_list:
sub_process = threading.Thread(target=copy_file, args=(file_name, source_dir, dest_dir))
sub_process.start()
什么是进程
系统进行资源分配的基本单位,比如qq,一个qq号登录就是一个进程
设置守护进程
设置守护进程的原因,当主进程结束后,子进程可能还没有结束,就会导致资源的浪费,可以设置子进程为守护进程,当主进程结束后,子进程也必须结束
Pro1 = multiprocessing.Process(target=sing, args=(3,)) Pro1.daemon = True
设置主进程等待子进程结束
设置主进程等待子进程的呃原因,当主进程结束后,子进程分配的任务还没有执行完成,主进程要等待子进程执行结束
Pro1.join()
创建一个多进程程序
import time
import multiprocessing
import os
def sing(num):
print("sing进程的编号是:%d" % os.getpid())
print("sing父进程的编号是:%d" % os.getppid())
for i in range(num):
print("唱歌.....")
time.sleep(0.5)
def dance(num):
print("dance进程的编号是:%d" % os.getpid())
print("dance父进程的编号是:%d" % os.getppid())
for i in range(num):
print("跳舞.....")
time.sleep(0.5)
if __name__ == "__main__":
print("main进程的编号是:%d" % os.getpid())
print("main父进程的编号是:%d" % os.getppid())
Pro1 = multiprocessing.Process(target=sing, args=(3,))
Pro2 = multiprocessing.Process(target=dance, kwargs={"num": 3})
# 设置子进程守护主进程,当主进程结束后该子进程也结束
Pro1.daemon = True
Pro1.start()
Pro2.start()
print("主进程结束了")
使用多进程实现文件拷贝
import multiprocessing
import os
"""多进程拷贝"""
def copy_file(file_name, source_dir, dest_dir):
source_path = source_dir + "\\" + file_name
dest_path = dest_dir + "\\" + file_name
print(source_path, "----->", dest_path)
with open(source_path, "rb") as source_file:
with open(dest_path, "wb") as dest_file:
while True:
file_data = source_file.read(1024)
if file_data:
dest_file.write(file_data)
else:
break
if __name__ == "__main__":
source_dir = "D:\\PycharmProjects\\TextProject\\视频"
dest_dir = "D:\\PycharmProjects\\TextProject\\Text"
try:
os.mkdir(dest_dir)
except:
print("目标文件夹已存在")
file_list = os.listdir(source_dir)
for file_name in file_list:
sub_process = multiprocessing.Process(target=copy_file, args=(file_name, source_dir, dest_dir))
sub_process.start()
什么是进程池
当需要创建的子进程数量不多时,可以直接利用multiprocessing中的Process动态成生多个进程,但如果是上百甚至上千个目标,手动的去创建进程的工作量巨大,此时就可以用到multiprocessing模块提供的Pool方法。
进程池也可以使用join方法,主进程等待进程池中的任务结束以后再结束

进程池有两种工作方式
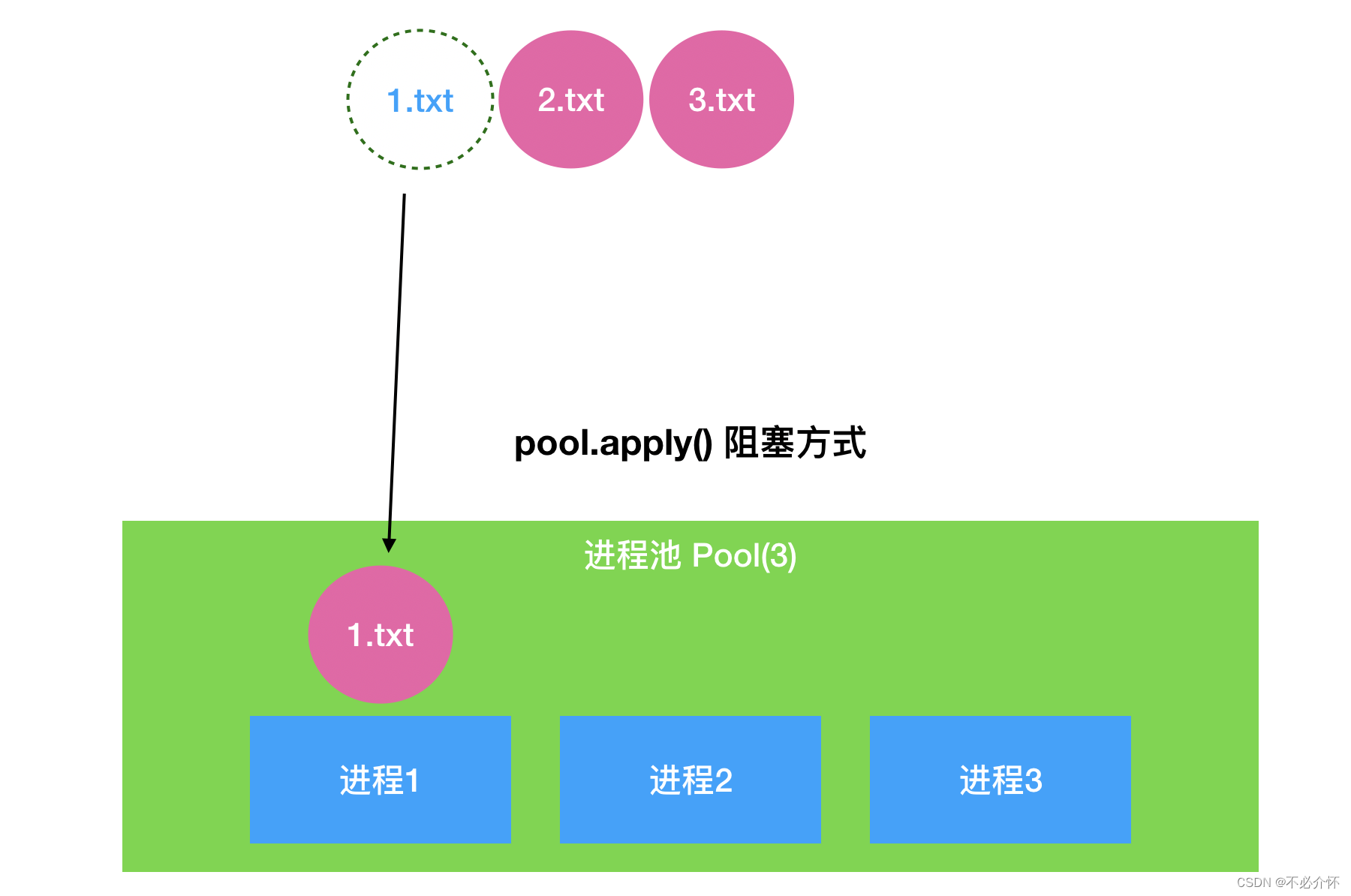
一种是同步的方式
同步执行 apply()
进程池创建以后,将接收到的任务一个个的去执行,进程1先去执行任务1.txt,进程1执行结束以后进程2去执行2.txt,进程2结束以后进程3去执行3.txt,当进来4.txt的时候交给进程1,以此类推
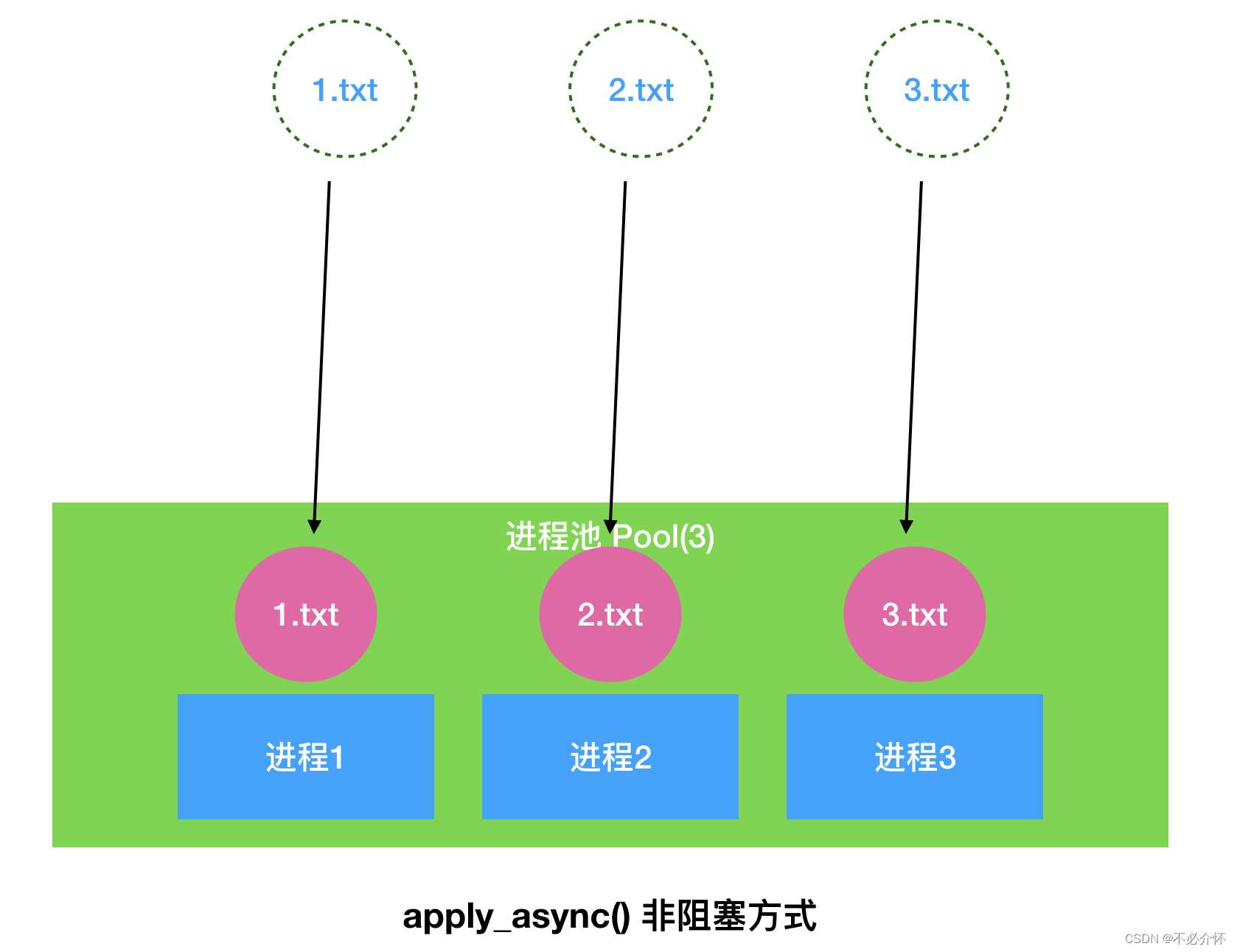
一种是异步的方式
并行执行apply_async()
进程池创建以后,要接收任务,让任务接收结束以后,将任务依次分配给进程池中已经存在的进程,一起执行。使用并行执行的方式需要使用线程池对象.close()方法停止接收任务
创建一个进程池
import time
import multiprocessing
def copy_work():
print("文件拷贝中.......%s"%multiprocessing.current_process())
time.sleep(0.5)
if __name__ == "__main__":
pool = multiprocessing.Pool(3)
for i in range(10):
# 以进程同步的方式进行
# pool.apply(copy_work)
# 以进程异步的方式进行
# 如果使用异步的方式要注意两点
# 1、pool.close()表示不再接收任务
# 2、主进程不在等待进程池执行结束后再退出
pool.apply_async(copy_work)
pool.close()
pool.join()
使用进程池实现文件的拷贝
import multiprocessing
import os
"""多进程拷贝"""
def copy_file(source_dir, dest_dir, file_name):
source_path = source_dir + "\\" + file_name
dest_path = dest_dir + "\\" + file_name
print(source_path, "----->", dest_path, "%s" % multiprocessing.current_process())
with open(source_path, "rb") as source_file:
with open(dest_path, "wb") as dest_file:
while True:
file_data = source_file.read(1024)
if file_data:
dest_file.write(file_data)
else:
break
if __name__ == "__main__":
source_dir = "D:\\PycharmProjects\\TextProject\\视频"
dest_dir = "D:\\PycharmProjects\\TextProject\\Text"
try:
os.mkdir(dest_dir)
except Exception as e:
print("目标文件夹已存在")
file_list = os.listdir(source_dir)
pool = multiprocessing.Pool(3)
for file_name in file_list:
pool.apply_async(copy_file, (source_dir, dest_dir, file_name))
pool.close()
pool.join()
什么是消息队列
进程之间有时需要通信,操作系统提供了很多机制来实现进程间的通信。
消息队列的数据结构就是个队列,遵循先进先出的规则
创建一个消息队列
put()和put_nowait()向队列传入一个内容,当队列中的内容已满后,前者等待不结束程序,后者不等待直接结束程序员
get()和get_nowait()从队列中取出一个内容,当队列中的内容为空时,前者等待内容的传入再取出,后者不等待直接退出
Queue.qsize():返回当前队列包含的消息数量;
Queue.empty():如果队列为空,返回True,反之False ;
Queue.full():如果队列满了,返回True,反之False;
import multiprocessing
import time
# 创建Queue消息队列对象
queue = multiprocessing.Queue(5)
# 使用put方法进入消息队列
queue.put(1)
queue.put([1, 2, 3])
queue.put([1, 2, 3])
# 使用full方法,判断队列是否已满
print("队列是否已满:%s" % queue.full())
# 使用qsize查看队列中消息的个数
print("队列中的消息个数:%s" % queue.qsize())
queue.put((1, 2, 3))
# 使用put_nowait,如果队列已经满了,不等待消息出队,直接报错
queue.put_nowait({"key": 1, "key2": 2})
time.sleep(0.0001)
# 使用empty判断队列是否为空
print("队列是否为空:%s" % queue.empty())
print("队列是否已满:%s" % queue.full())
print("队列中的消息个数:%s" % queue.qsize())
# 使用get方法取出一个队列消息
print(queue.get())
print(queue.get())
print(queue.get())
print(queue.get())
# 使用get_nowait方法取出一个队列消息,如果队列为空,不等待消息传入,直接报错
print(queue.get_nowait())
使用消息队列实现进程间通信
import multiprocessing
def work1(queue):
queue.put(1)
queue.put([1, 2, 3])
queue.put([1, 2, 3])
queue.put((1, 2, 3))
def work2(queue):
queue.put_nowait({"key": 1, "key2": 2})
queue.get()
queue.get()
queue.get()
queue.get()
queue.get()
def main():
queue = multiprocessing.Queue(5)
process1 = multiprocessing.Process(target=work1, args=(queue,))
process2 = multiprocessing.Process(target=work2, args=(queue,))
process1.join()
process1.start()
process2.start()
if __name__ == "__main__":
main()