Linux——缓冲区与FLIE*的原理简单实现
我们之前在fd的分配规则里面见到过了缓冲区这样的东西,今天我们来深入了解一下我们的缓冲区到底是怎么个事~。
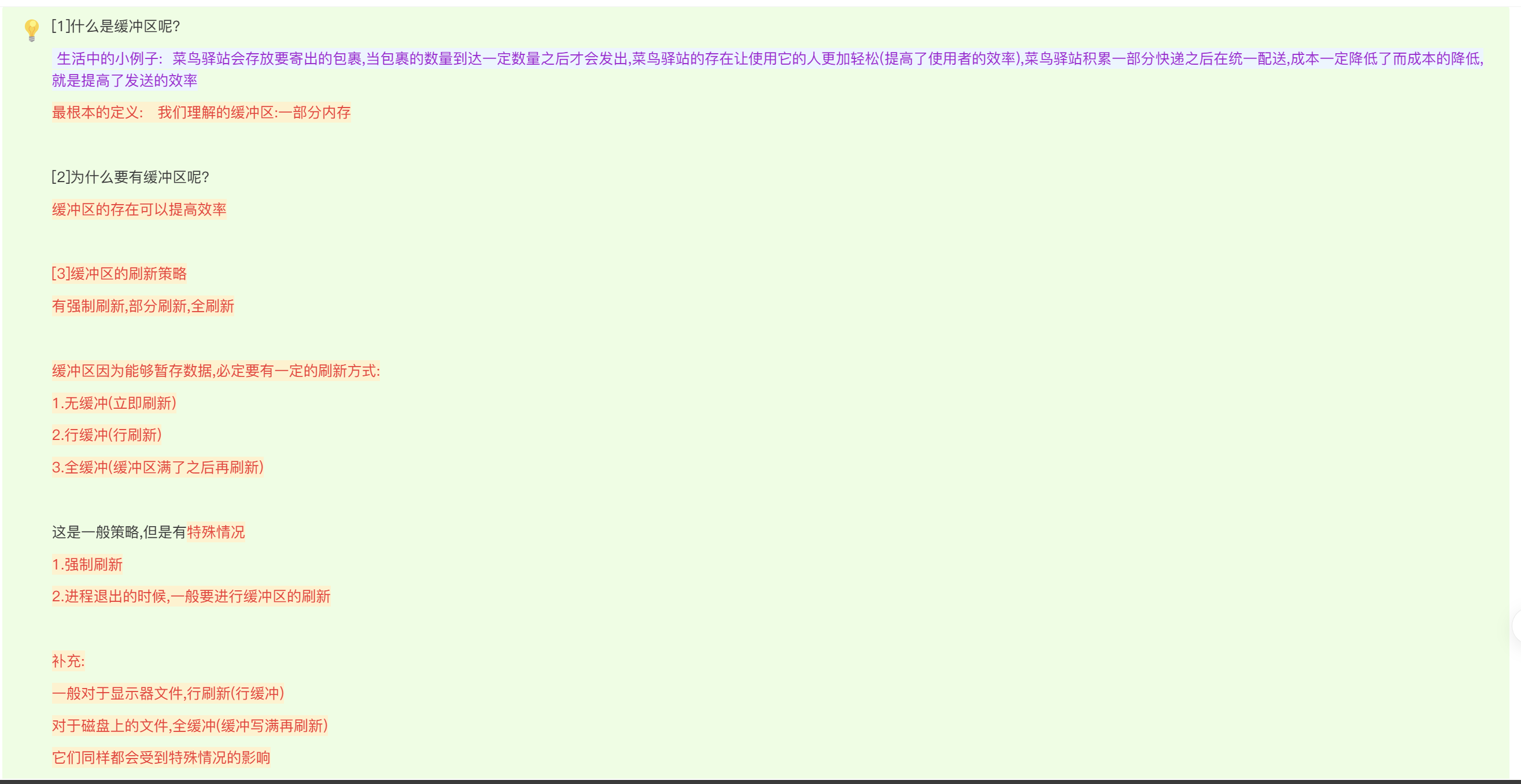
缓冲区的概念(buffering area)
我们已经了解到了缓冲区这样的概念了,但是为什么要设置缓冲区这样的东西呢?
其实大家可以想一想,我们的屏幕一天有大量的向某个文件输入输出的操作,如果我一拿到数据,就马不停蹄的往文件里面送,操作系统会累死,所以我不妨设置一个缓冲区,等到有一定数量的数据我再往文件里面送,这样操作系统轻松的多。
其实总结起来就一句话缓冲区的存在就是为了提高效率。
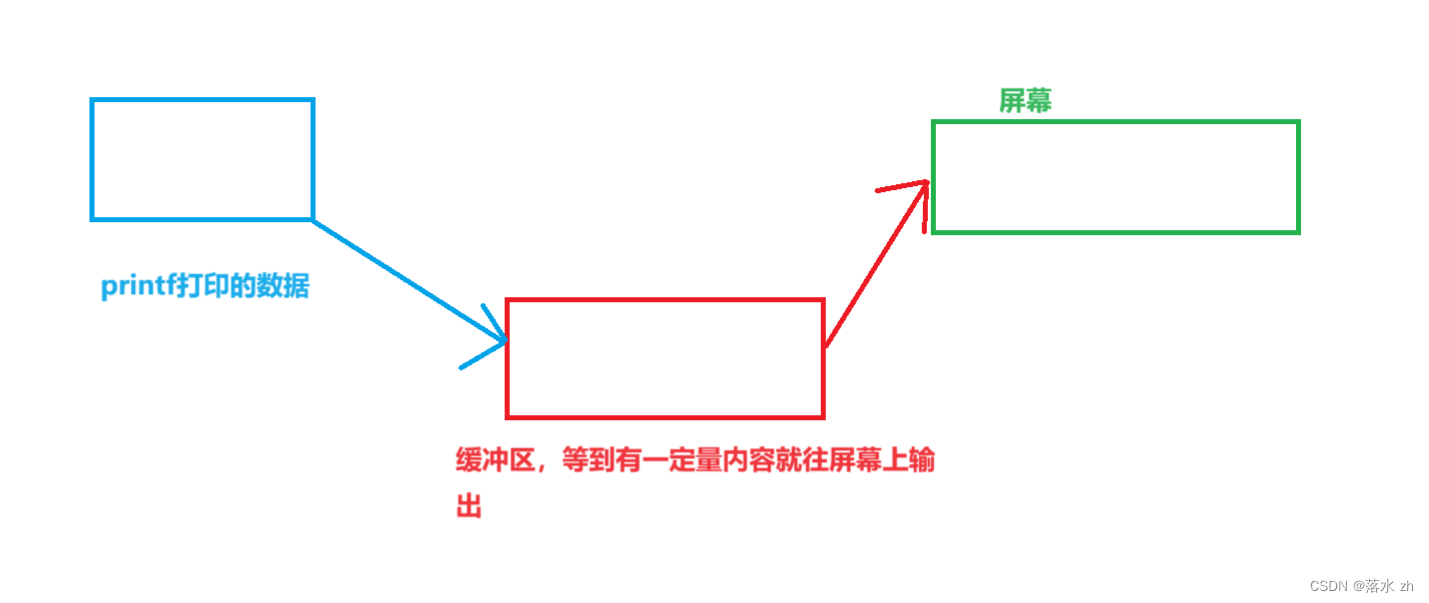
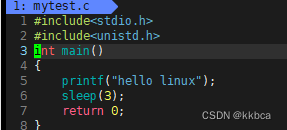
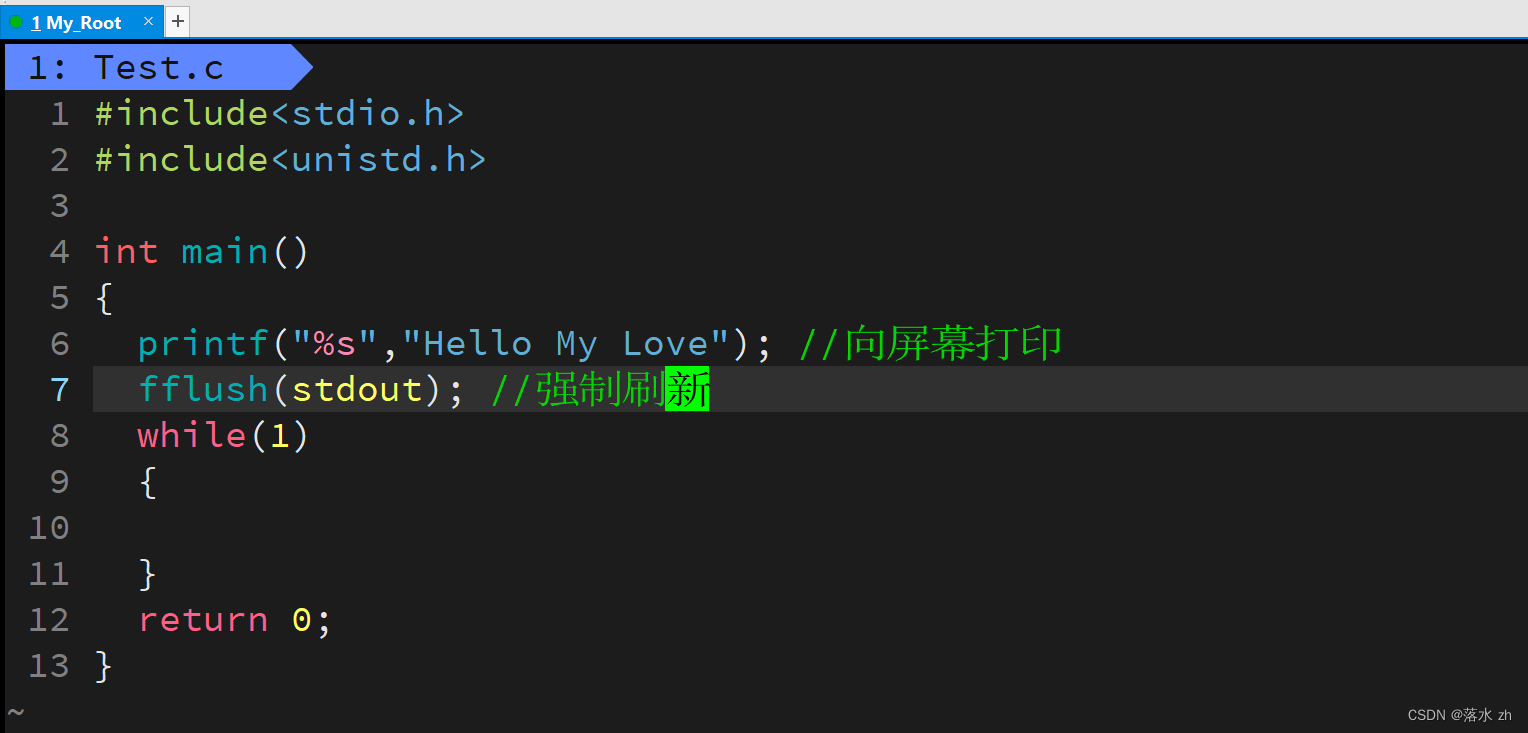
我们来看看缓冲区是不是真正存在,我们写下这样的一段代码:
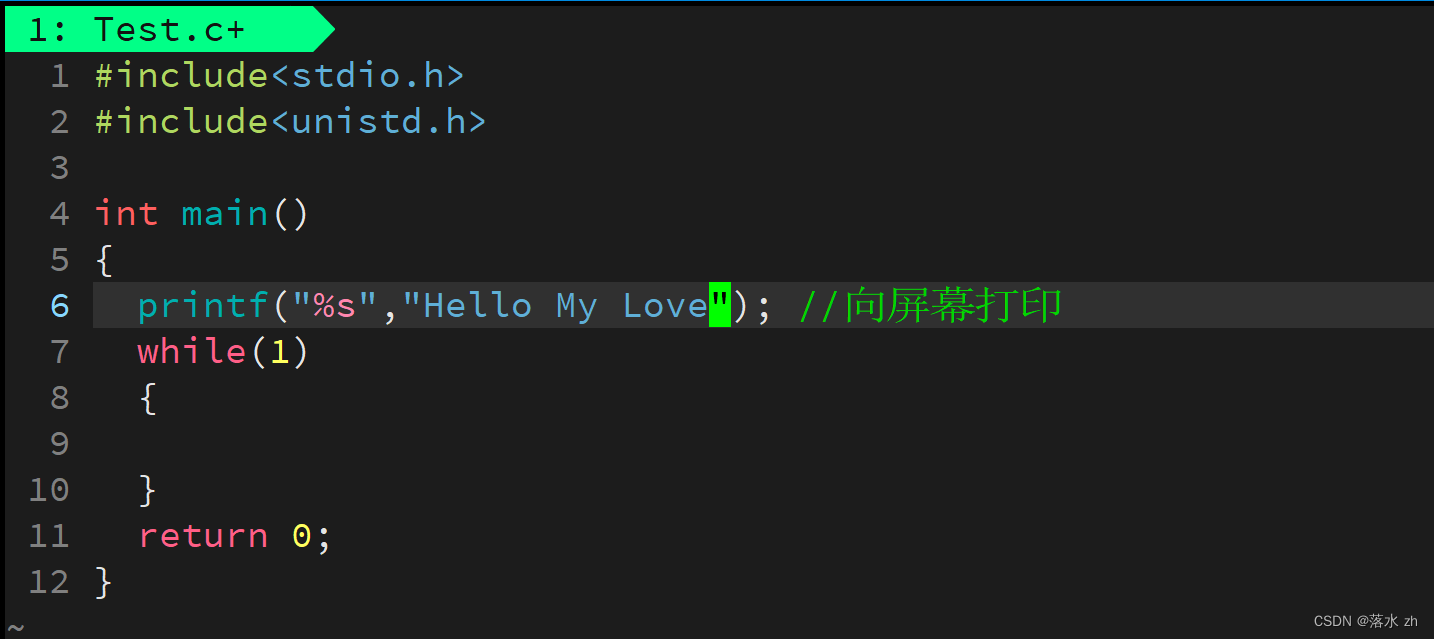
我们向屏幕打印,遇到while死循环,我们看看会发生什么事?
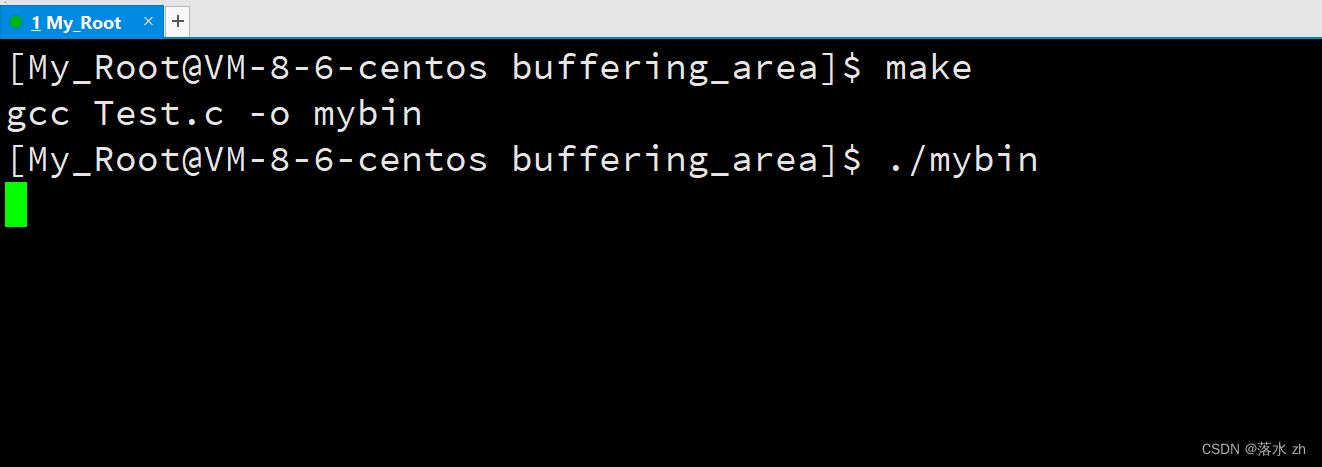
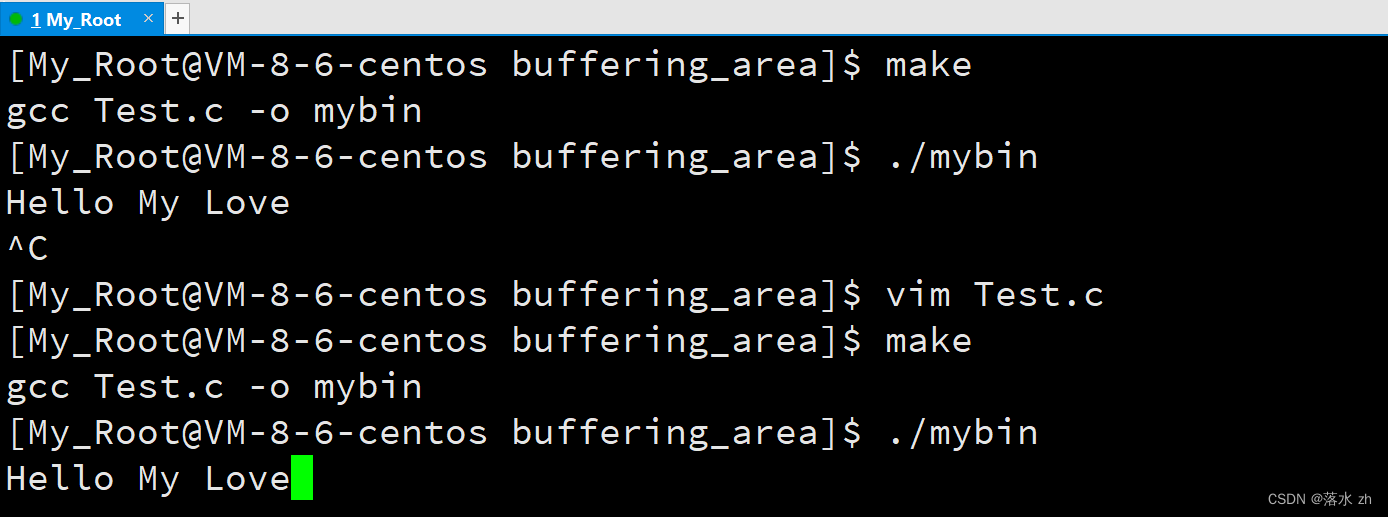
我们发现什么也没有输出,我们退出来,加上个换行符:
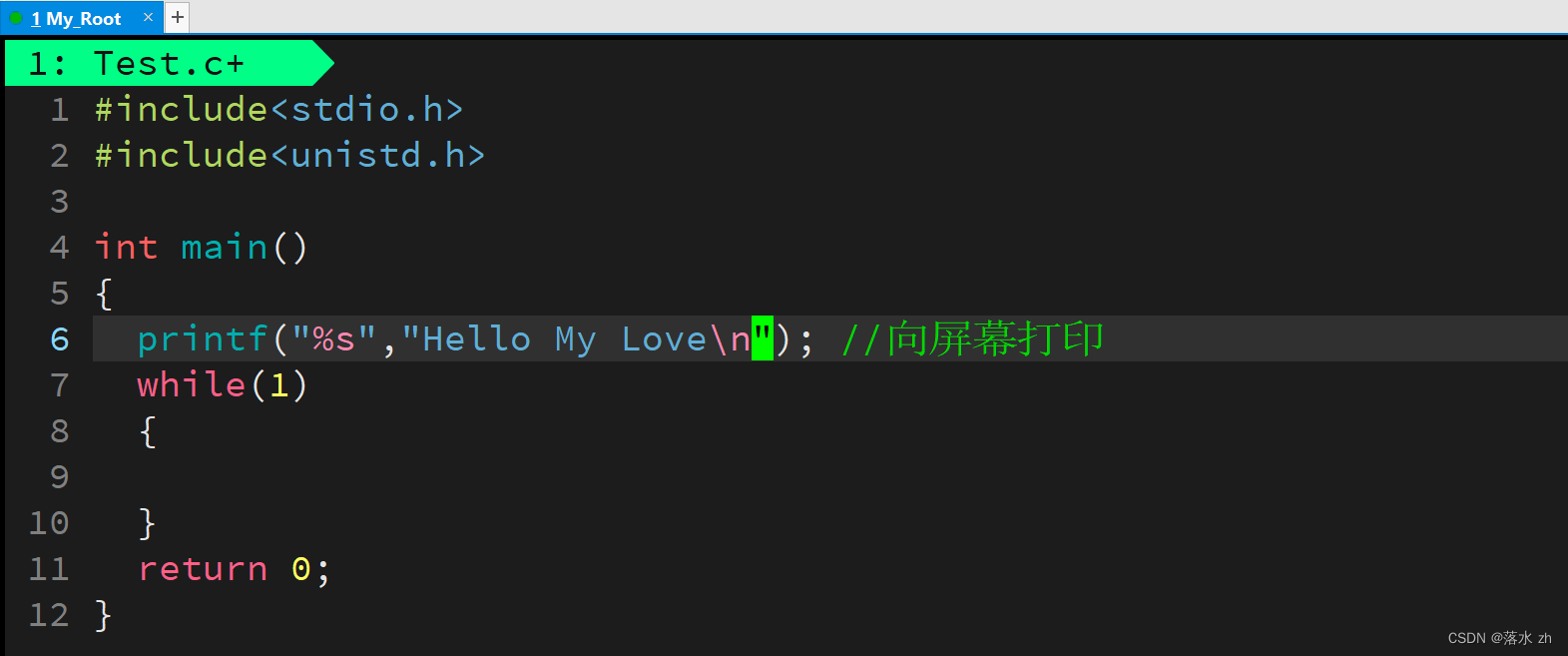 再来一次:
再来一次:
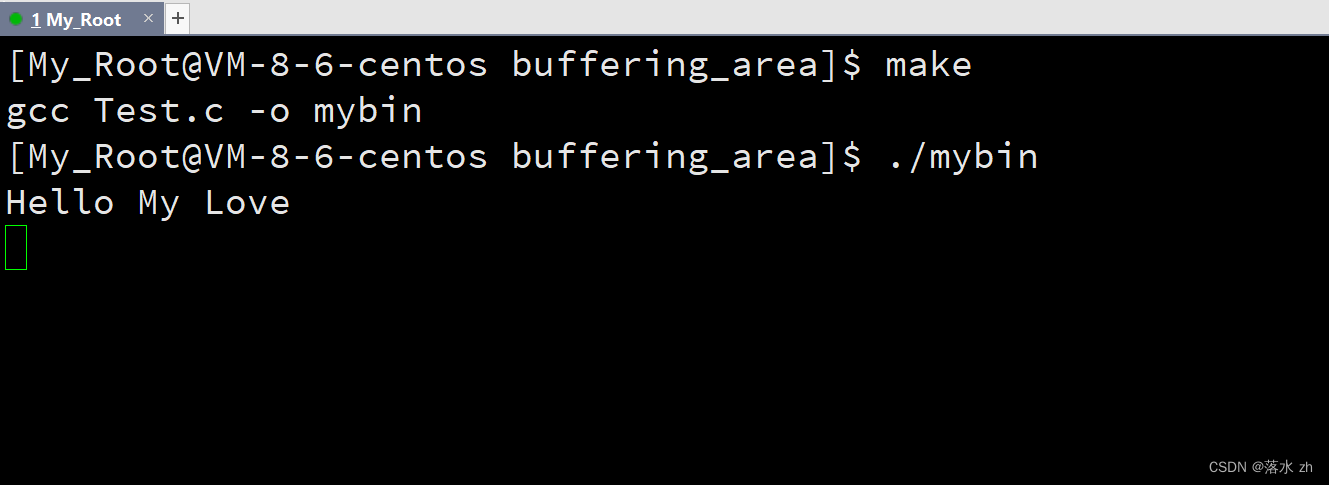 我们发现,字符串被打印出来了,证明了我们的猜想,但是为什么加上一个换行符,字符串就被打印出来了呢?
我们发现,字符串被打印出来了,证明了我们的猜想,但是为什么加上一个换行符,字符串就被打印出来了呢?
其实我们缓冲区有自己的刷新方式,我们一般有三种方式的刷新:
无缓冲:数据不经过缓冲区,直接输入输出。
行缓冲:以换行符为标识,遇到换行符刷新。
全缓冲:只有缓冲区满了才刷新。
其实除了这三种之外,我们遇到一些特殊情况的时候,也会进行刷新:
强制刷新 fflush
我们就是想让缓冲区的内容吐出来的话,我们可以强制刷新,就是我们之前用的fflush:
进程结束
一般来说,进程结束,也会强制刷新缓冲区:

一个奇怪的例子
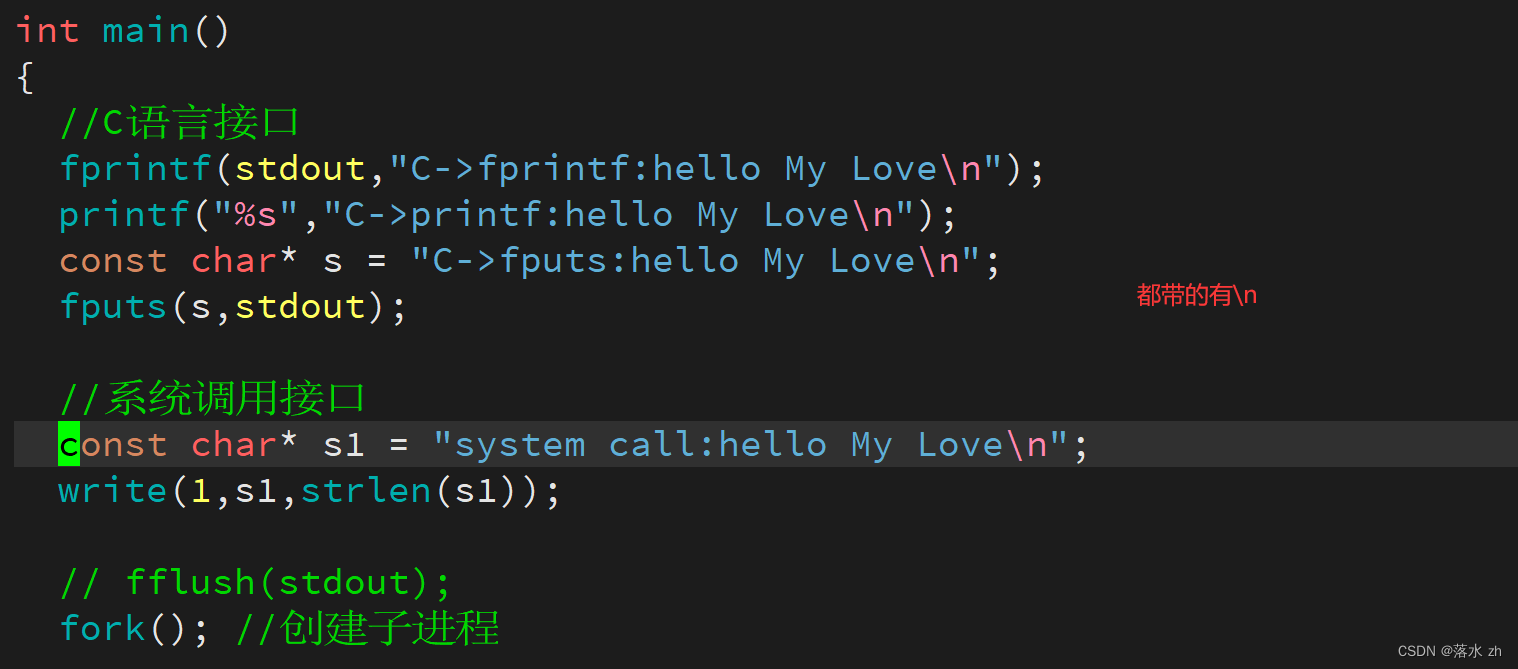
我们写一段这样的代码:
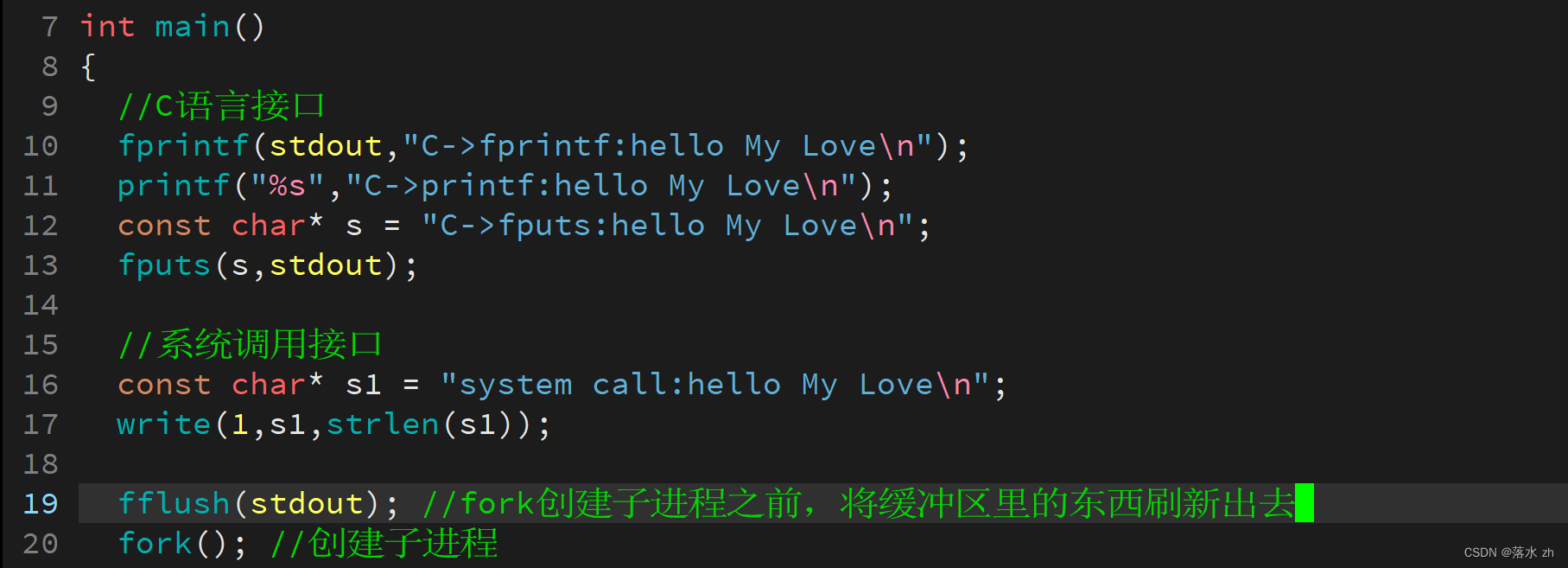
//C语言接口
fprintf(stdout,"C->fprintf:hello My Love\n");
printf("%s","C->printf:hello My Love\n");
const char* s = "C->fputs:hello My Love\n";
fputs(s,stdout);
//系统调用接口
const char* s1 = "system call:hello My Love\n";
write(1,s1,strlen(s1));
fork(); //创建子进程
 但是如果我重定向给log.txt:
但是如果我重定向给log.txt:
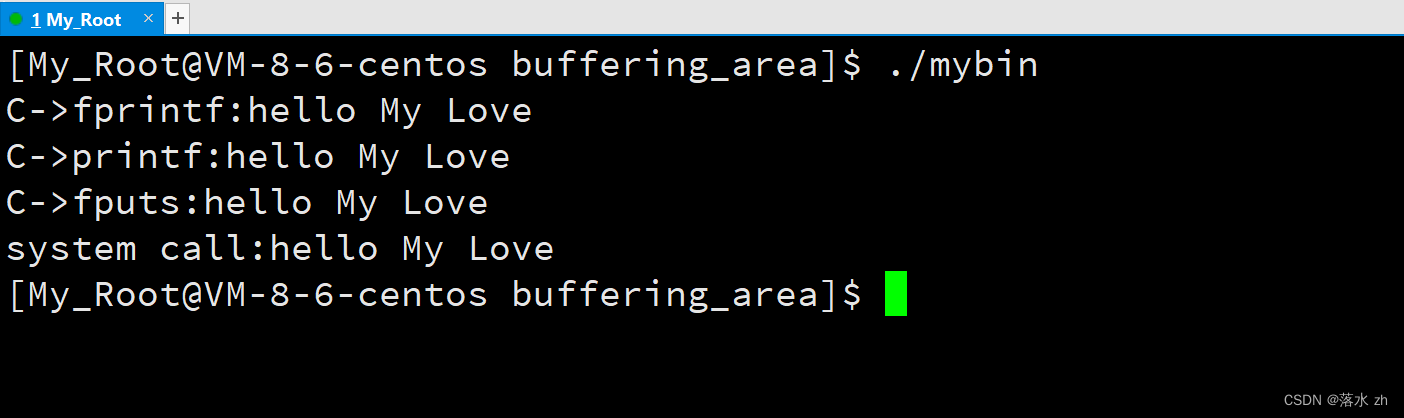
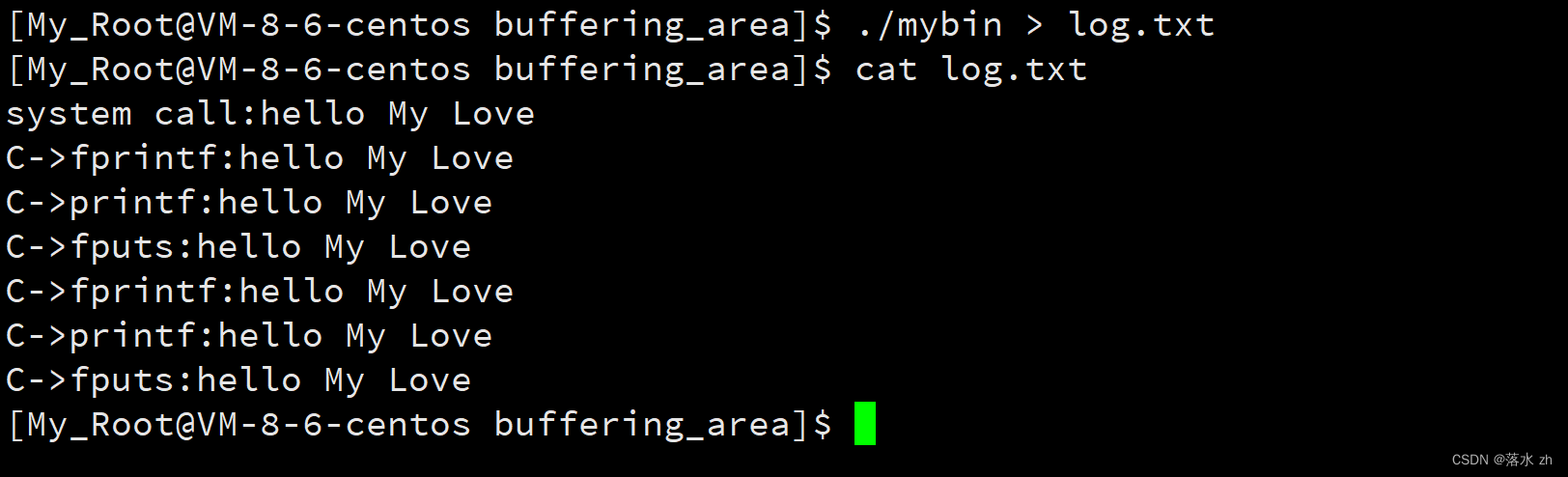 我么发现,C语言接口调用的被重复了两次,而系统调用的只被打印了一次。这是为什么呢?其实这是C语言在语言层面上为我们提供了一个缓冲区,我们之前的提到的那几种缓冲方式都是基于C语言为我们提供的缓冲区(我们称为用户缓冲区)。
我么发现,C语言接口调用的被重复了两次,而系统调用的只被打印了一次。这是为什么呢?其实这是C语言在语言层面上为我们提供了一个缓冲区,我们之前的提到的那几种缓冲方式都是基于C语言为我们提供的缓冲区(我们称为用户缓冲区)。
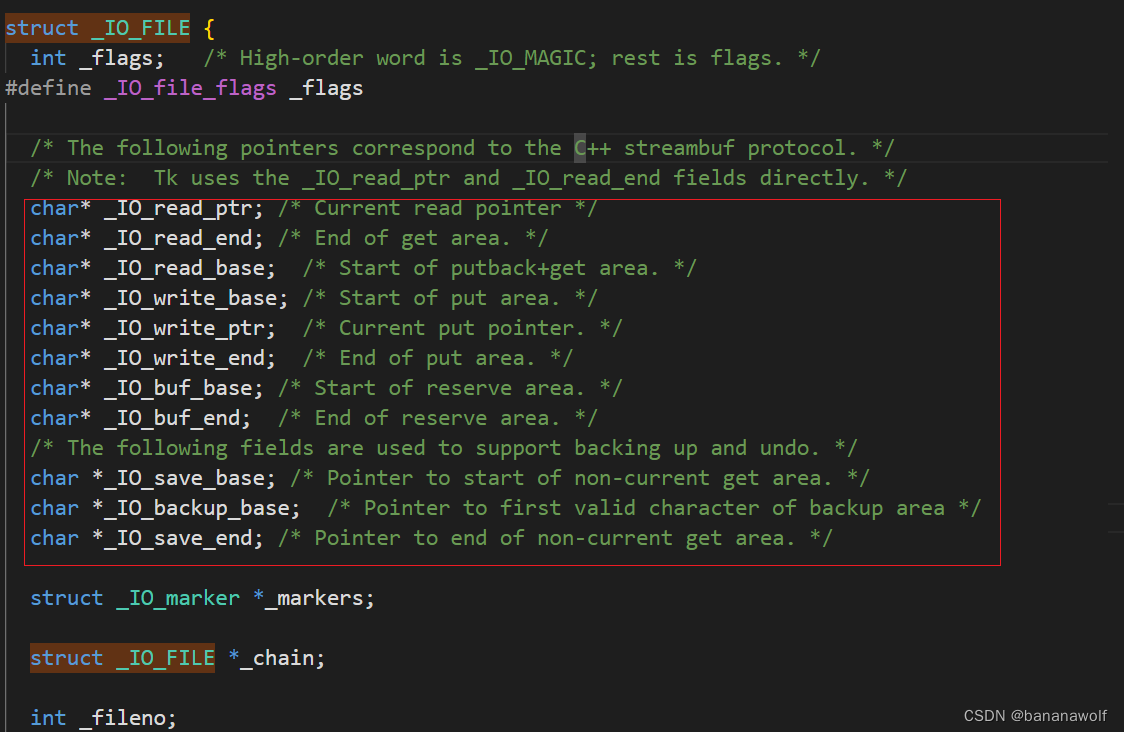
用户级别缓冲区和内核缓冲区
我们除了用户级别的缓冲区,我们也有内核缓冲区,这两者有什么区别呢?
内核缓冲区和用户级缓冲区是两种不同层次的缓冲区,用于管理数据在用户空间和内核空间之间的传输。以下是它们之间的主要区别:
1.位置和所有权:
用户级缓冲区: 由程序员在用户空间显式创建和管理。这些缓冲区是应用程序的一部分,程序员负责分配、释放和管理这些缓冲区的生命周期。
内核缓冲区: 由操作系统内核管理。这些缓冲区是操作系统内核的一部分,操作系统负责分配、释放和管理这些缓冲区的生命周期。
2.可见性:
用户级缓冲区: 只对创建它们的进程可见。其他进程无法直接访问或操作这些缓冲区,除非通过进程间通信(Inter-Process Communication,IPC)等机制进行共享。
内核缓冲区: 在整个系统内核中是可见的,可以被多个进程访问。操作系统通过提供适当的系统调用来允许用户程序与内核缓冲区进行交互。
3.效率:
用户级缓冲区: 可以通过手动管理来实现更高效的内存使用,但程序员需要自行处理缓冲区的大小、数据拷贝等细节。
内核缓冲区: 由操作系统内核优化管理,通常设计用于提高 I/O 操作的效率。内核缓冲区通常涉及更多底层的操作,例如页面调度、块缓存等,以减少磁盘 I/O 的次数,提高整体性能。
4.接口和操作:
用户级缓冲区: 使用标准库函数(如 fread、fwrite)等进行数据的读写。程序员有更多的控制权,但也需要处理更多的细节。
内核缓冲区: 通过系统调用(如 read、write)等进行数据的读写。这些系统调用将数据传递给内核,由内核负责实际的 I/O 操作。
总的来说,用户级缓冲区更灵活,但需要程序员自己管理,而内核缓冲区由操作系统管理,更适用于底层的系统 I/O 操作。选择使用哪种缓冲区通常取决于具体的应用场景和性能需求。
我们还要注意一点,一般来说我们向显示器输出的话,一般是行刷新,如果向文件输出就是全刷新
我们来解释一下第一个,为什么我们向屏幕打印只有一次打印:
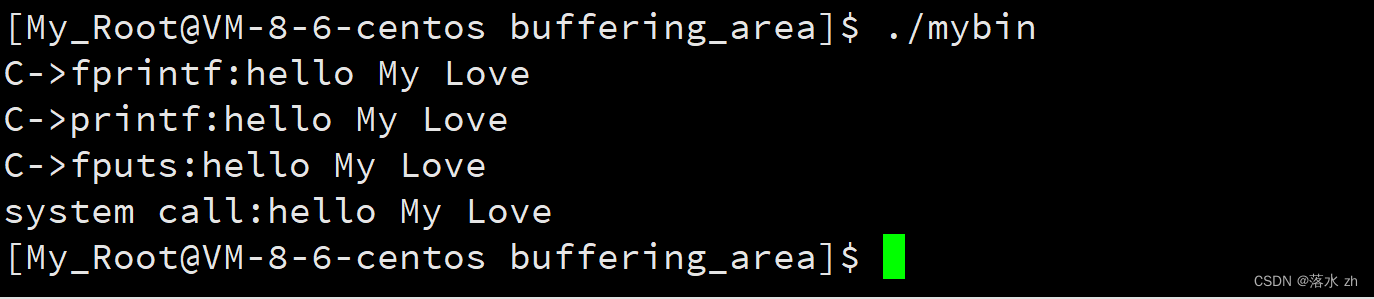
这是因为我们向显示器打印是用的行刷新,我们的代码当中每个字符串后面我都带的有\n,意思是我的这些文字已经提前刷到内核缓冲区里了:
在fork创建子进程之前,我父进程的缓冲区里没有任何东西了:
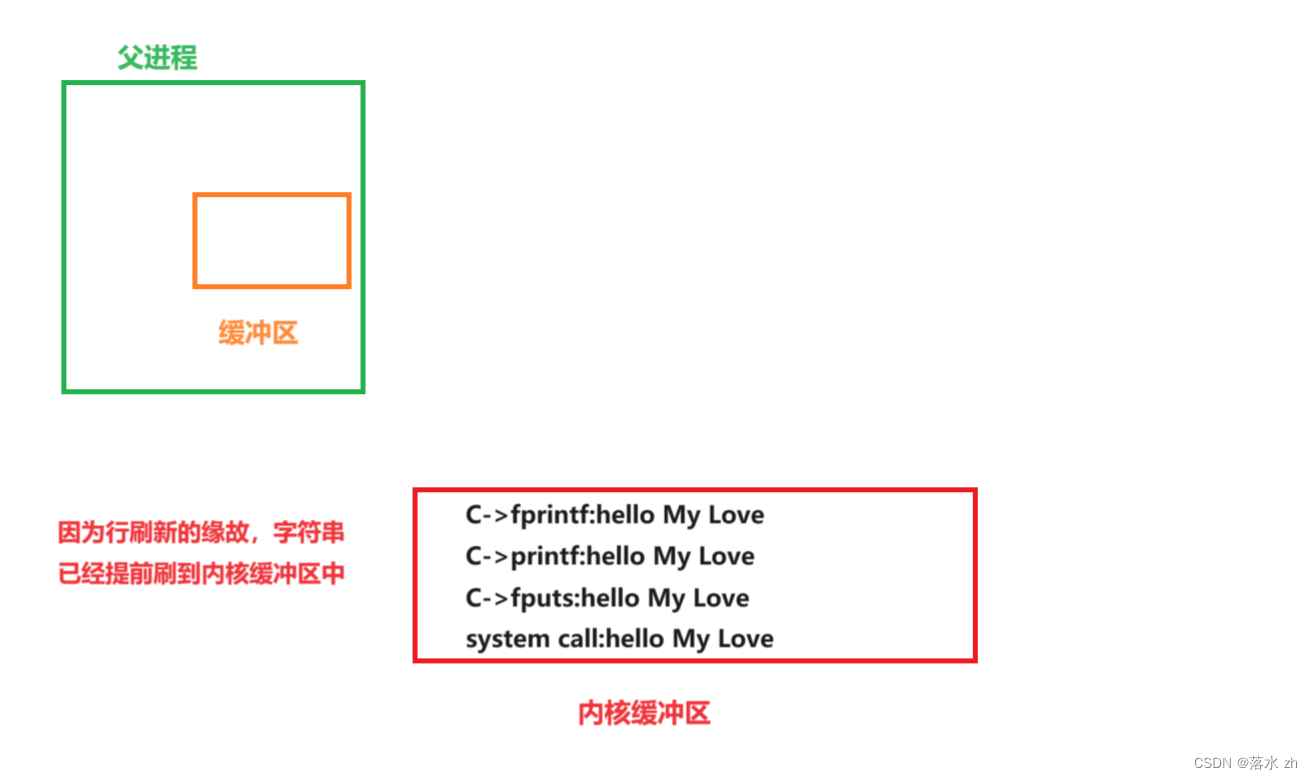
此时创建子进程,也会复制父进程的缓冲区,此时缓冲区里什么也没有,然后创建完之后,子进程结束,所以我们只看到一次打印。
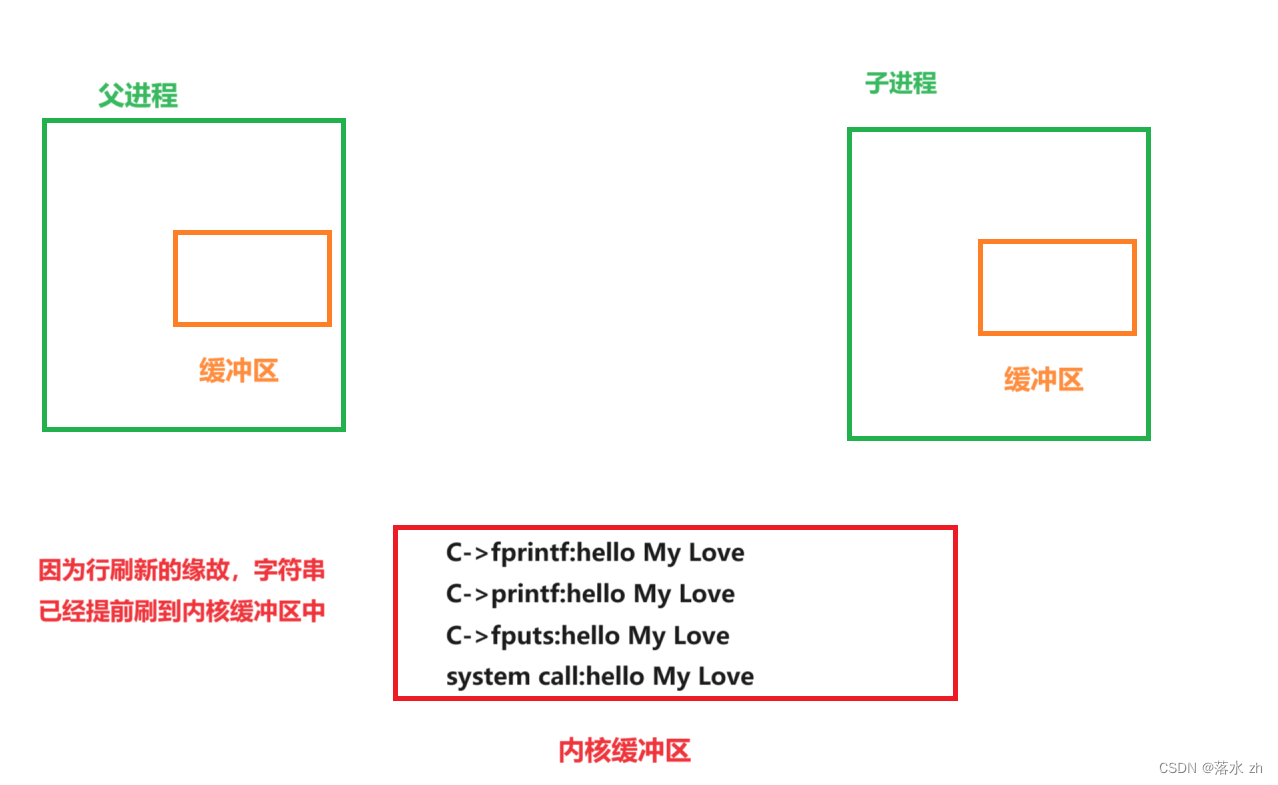
但是如果,我们向文件log.txt中重定向的时候,刷新方式会发生改变,会变成全刷新,意思就是只有当缓冲区满了,或者进程结束,我才刷新缓冲区:

此时fork创建子进程,就会把父进程缓冲区里的内容复制一份:
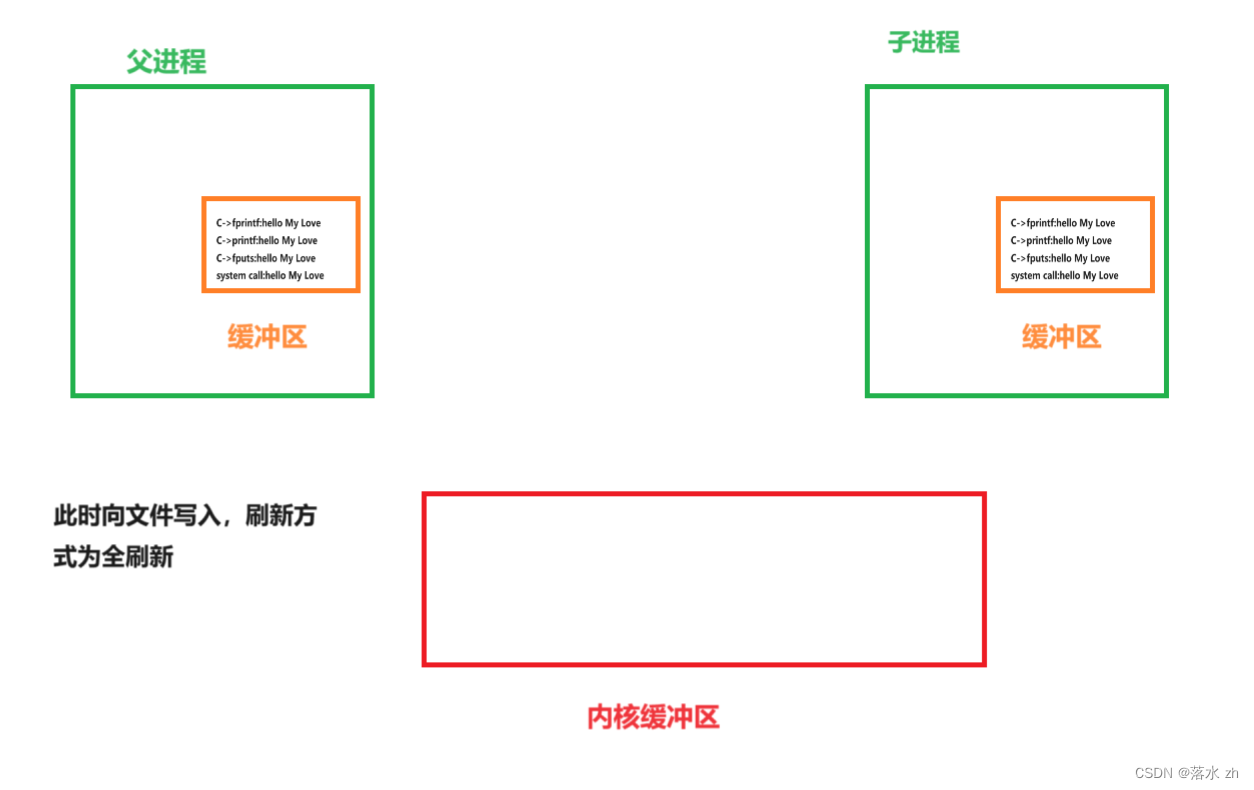 这个时候,程序结束,内核缓冲区会有两份一模一样的数据,所以我们会看到两次打印。
这个时候,程序结束,内核缓冲区会有两份一模一样的数据,所以我们会看到两次打印。
如果我们不想让它复制,我们就应该在fork发生写实拷贝之前将缓冲区里的东西刷新出去:
但是还有一个问题,为什么我们的系统调用的接口,没有被打印两次呢?
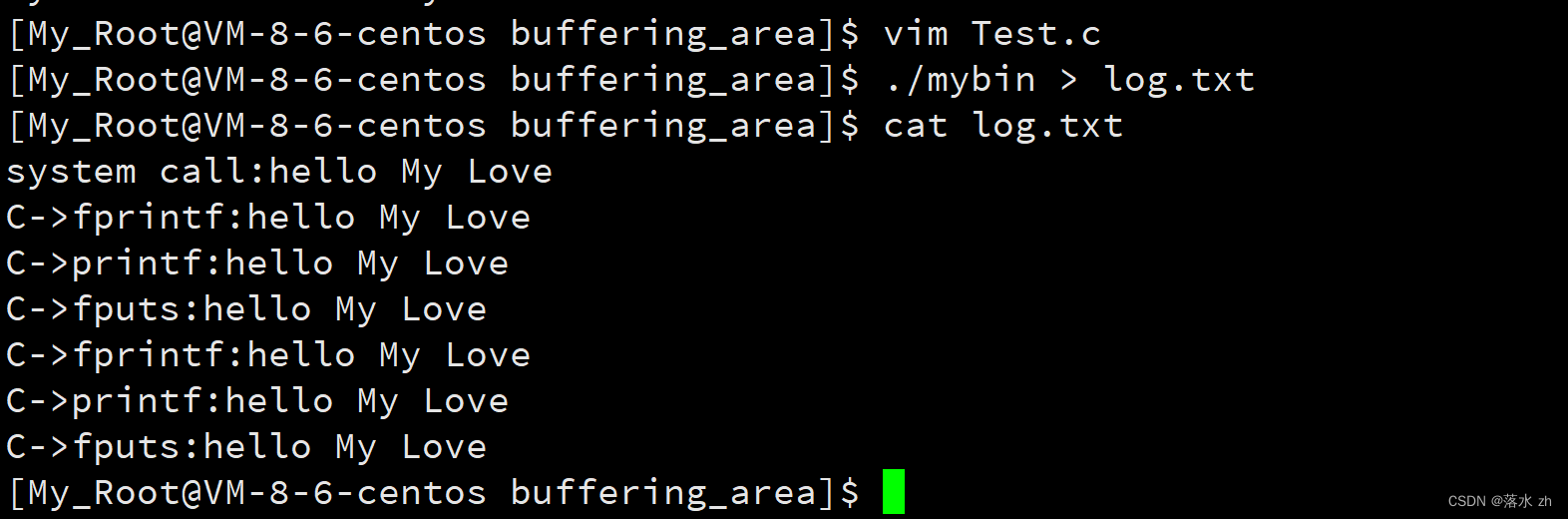
那是因为我们调用的系统调用的write接口是直接向内核缓冲区中写入,不会经过fork的写实拷贝。
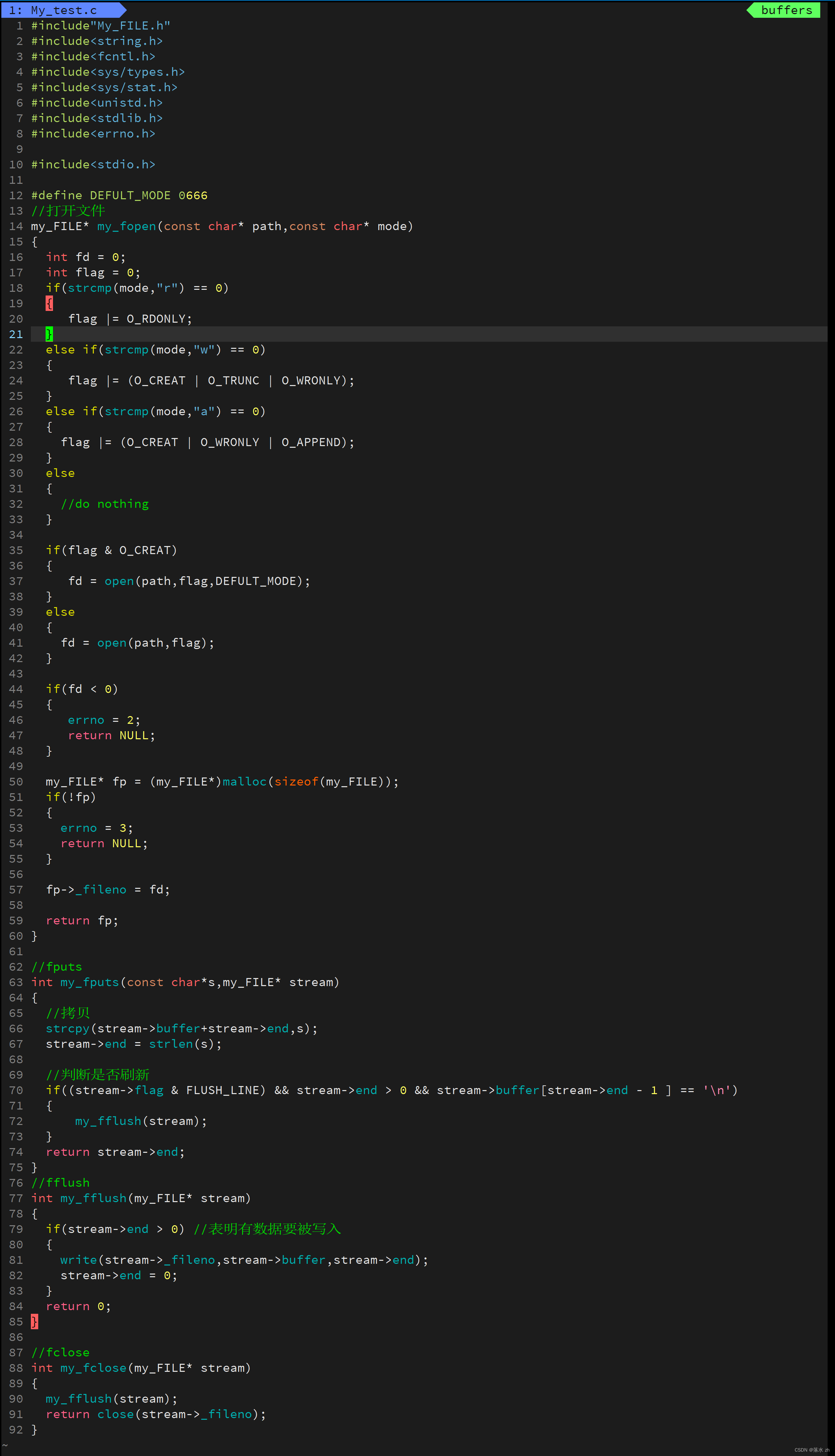
自己实现简易版的FILE*
我们可以根据这个原理实现一个简单的FILE*: