目录
1、ELK是什么
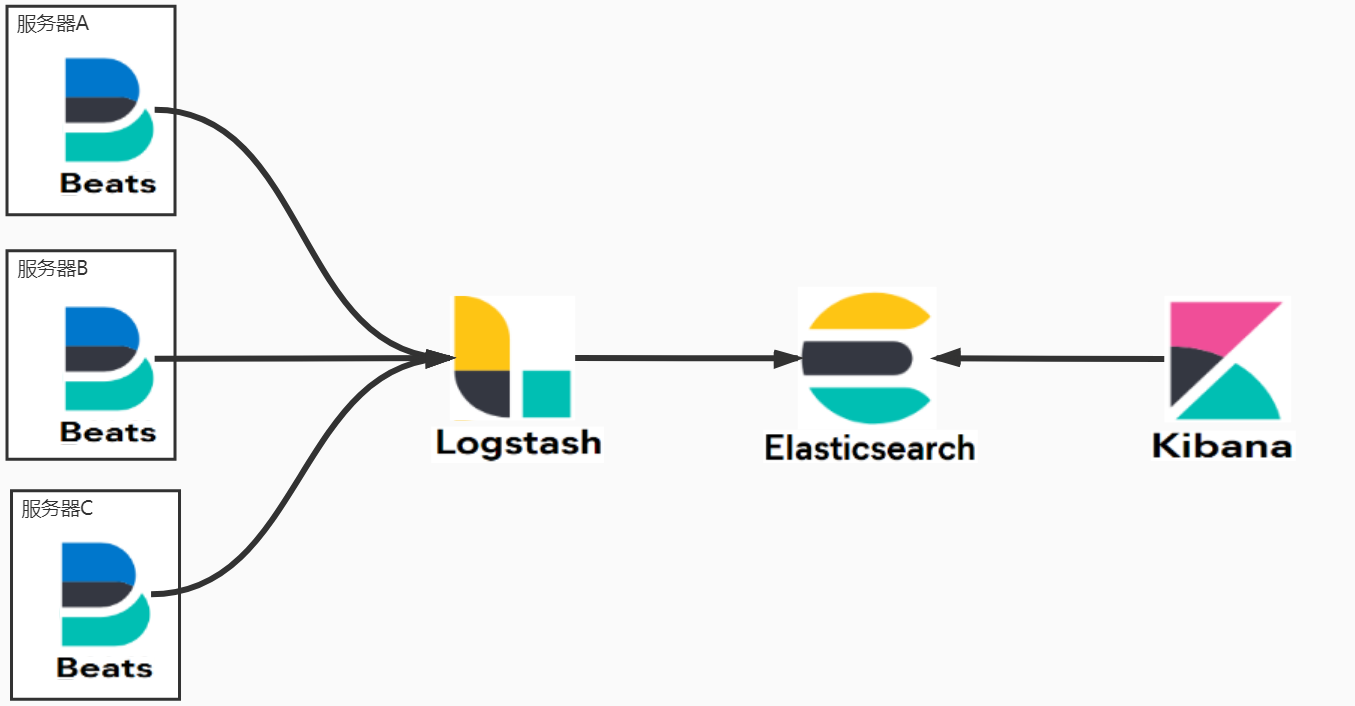
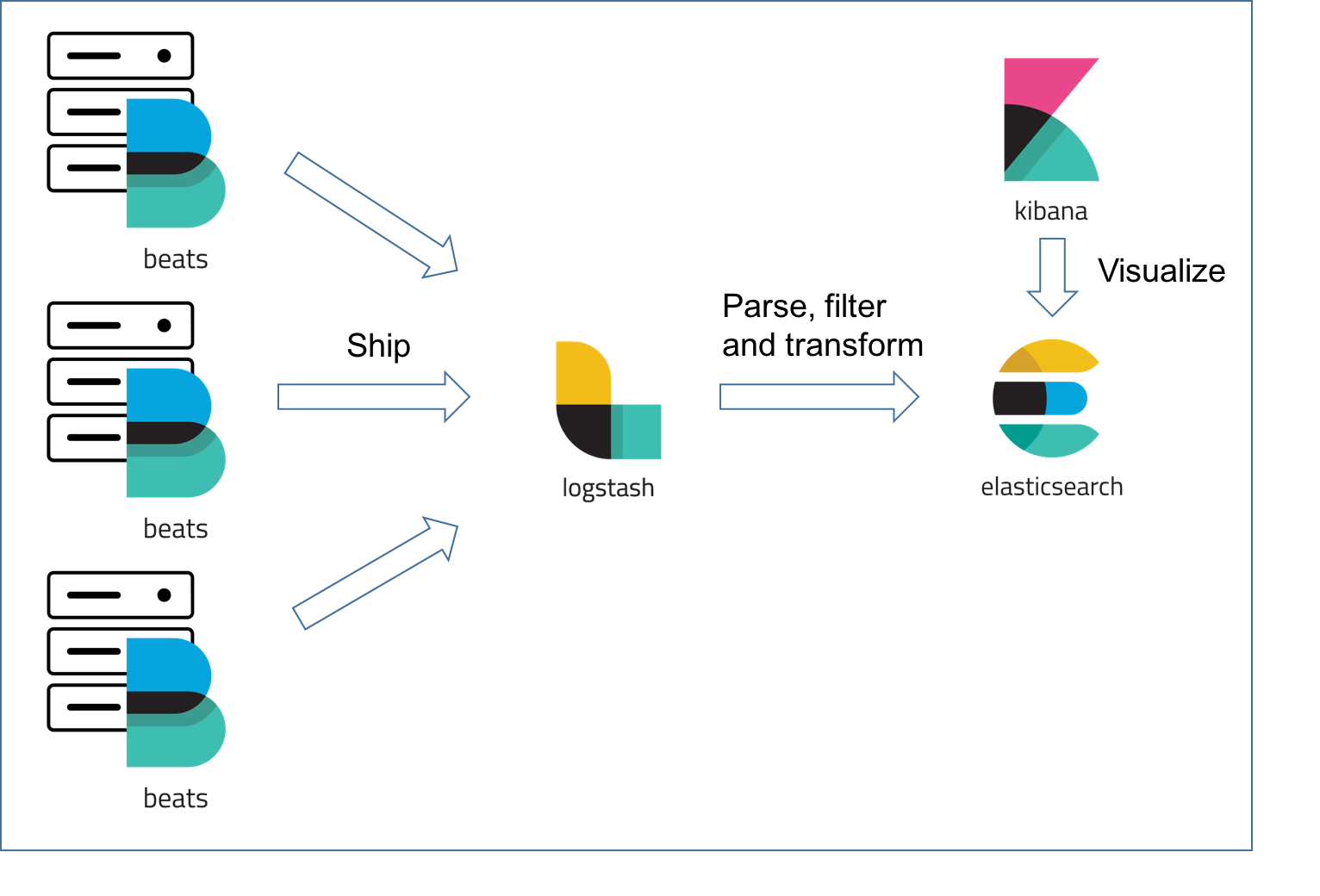
ELK 是一个由三个开源软件组成的组合,它们分别是 Elasticsearch、Logstash 和 Kibana。这三个软件被整合在一起,用于实时搜索、分析和可视化大规模数据集。
1. Elasticsearch(ES):Elasticsearch 是一个基于Apache Lucene实现的,分布式的开源搜索和分析引擎。它能够快速地存储、搜索和分析非结构化的大数据,具有高可用性和可伸缩性。Elasticsearch 使用倒排索引来实现高性能的文本搜索,并提供了丰富的查询语言和聚合功能,使用户能够轻松地执行各种复杂的搜索和分析操作。
2. Logstash:Logstash 是一个用于收集、处理和转发日志和事件数据的开源工具。它能够从多种来源(如日志文件、消息队列、数据库等)收集数据,并进行过滤、解析和转换,最终将数据发送到 Elasticsearch 或其他目标存储库中。Logstash 提供了丰富的插件和过滤器,使用户能够根据自己的需求灵活地定制数据处理流程。
3. Kibana:Kibana 是一个用于可视化和分析 Elasticsearch 数据的开源工具。它提供了直观友好的 Web 界面,让用户能够通过图表、图形和仪表板等方式对数据进行探索和展示。Kibana 支持实时查询和过滤数据,还可以创建交互式仪表板,方便用户进行数据监控和可视化分析。
ELK 组合的典型使用场景包括日志分析、应用程序性能监测(APM)、实时监控、安全事件分析等。通过将 Logstash 用于数据收集与预处理,然后将数据存储在 Elasticsearch 中,并使用 Kibana 进行数据分析和可视化,用户可以快速获取有关大规模数据的洞察,并支持决策制定和问题排查。
2、Elasticsearch(ES)
2.1 虚拟机docker安装es
拉取es镜像(指定版本7.17.7)
docker pull elasticsearch:7.17.7
配置文件
创建如下文件夹目录:
/usr/local/software/elk/elasticsearch/conf
/usr/local/software/elk/elasticsearch/data
/usr/local/software/elk/elasticsearch/plugins
[root@localhost elasticsearch]# mkdir conf
[root@localhost elasticsearch]# mkdir data
[root@localhost elasticsearch]# mkdir plugins
[root@localhost elasticsearch]# tree
.
├── conf
├── data
└── plugins
3 directories, 0 files
[root@localhost elasticsearch]# pwd
/usr/local/software/elk/elasticsearch
在conf下创建elasticsearch.yml,修改权限777
[root@localhost elasticsearch]# cd conf/[root@localhost conf]# touch elasticsearch.yml[root@localhost conf]# chmod 777 elasticsearch.yml[root@localhost conf]# ll总用量 0-rwxrwxrwx. 1 root root 0 12月 5 11:03 elasticsearch.yml
编辑elasticsearch.yml
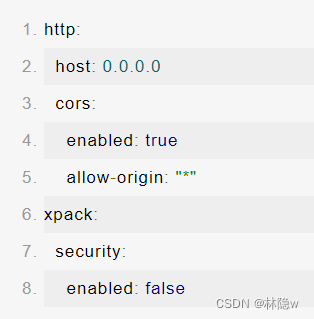
修改linux的vm.max_map_count
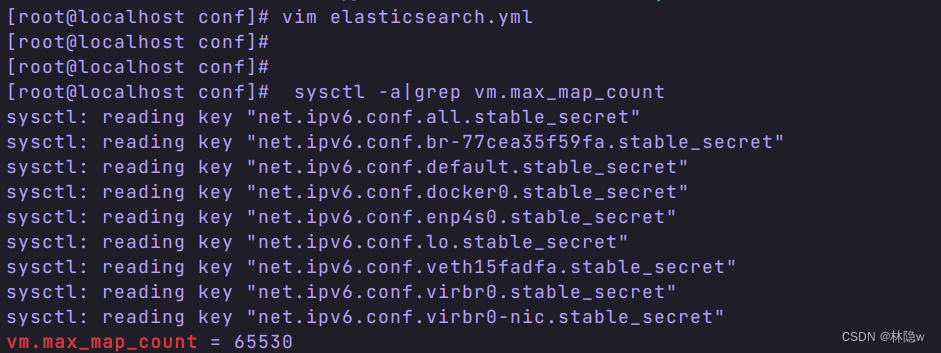
做如下修改:
[root@localhost conf]# sysctl -w vm.max_map_count=262144vm.max_map_count = 262144
创建docker运行容器
docker run -itd \
--name es \
--privileged \
--network docker_net \
--ip 172.18.12.77 \
-p 9200:9200 \
-p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms2g -Xmx2g" \
-v /usr/local/software/elk/elasticsearch/conf/elasticsearch.yml:/usr/share/elasticsearch/conf/elasticsearch.yml \
-v /usr/local/software/elk/elasticsearch/data:/usr/share/elasticsearch/data \
-v /usr/local/software/elk/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
elasticsearch:7.17.7
2.2 倒排索引
倒排索引(Inverted Index)是一种用于快速定位和搜索文档的数据结构,常用于搜索引擎中,需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。倒排索引也常被称为反向索引、置入档案或反向档案,用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。它的实现原理可以简单描述为以下几个步骤:
1. 文档收集:首先,将需要进行索引的文档集合进行收集,这些文档可以是网页、文本文件、数据库记录等。
2. 分词处理:对每个文档进行分词处理,将文本内容切分成独立的词项(Term)。这个过程可以使用词法分析器或者自然语言处理技术来完成。
3. 建立倒排索引表:对于每个词项,记录下该词项出现在哪些文档中。为了提高检索效率,倒排索引表通常使用哈希表或者树型数据结构进行存储。每个词项对应一个倒排列表(Posting List),其中包含了包含该词项的文档的相关信息,比如文档 ID、词频等。
4. 优化:为了进一步提高索引的效率,可以对倒排列表进行排序、压缩和合并等优化操作。例如,可以按照文档的相关性对倒排列表进行排序,或者使用压缩算法减小索引的存储空间占用。
5. 搜索:当用户输入一个查询词项时,搜索引擎会在倒排索引表中查找该词项对应的倒排列表。然后根据查询的要求(如布尔检索、短语匹配等),从倒排列表中获取相关的文档信息,并按照相关性进行排序。
图片来源:在项目开发中使用ElasticSearch_elasticsearch集成进普通java项目-CSDN博客
倒排索引的优势在于它可以快速定位包含某个词项的文档,而不需要遍历所有文档。这是通过将词项映射到文档的方式来实现的,相比于传统的正排索引(即将文档映射到词项的方式),倒排索引在面对大规模文本数据时效率更高。

图片来源:ES第十天-索引原理那些事_es正排索引原理-CSDN博客
常见的词典结构:

图片来源:正排索引与倒排索引应用场景 - 简书
需要注意的是,倒排索引在建立和维护过程中会消耗一定的存储空间和计算资源,特别是对于大规模数据集。因此,在实际应用中,需要权衡索引的规模和查询的效率,进行适当的优化和折衷。
2.3 es的分词器ik
下载分词器压缩文件,elasticsearch-analysis-ik-7.17.7.zip
上传到Linux的usr/local/software/elk/plugins 文件目录下

进入es容器,创建文件夹ik
目录如下:
:/usr/share/elasticsearch/plugins/ik
拷贝分词器到容器中的ik文件夹中
root@8b71f6edf8d6:/usr/share/elasticsearch/plugins/ik# lelasticsearch-analysis-ik-7.17.7.ziproot@8b71f6edf8d6:/usr/share/elasticsearch/plugins/ik# pwd/usr/share/elasticsearch/plugins/ik
解压分词器
unzip elasticsearch-analysis-ik-7.17.7.zip
解压好后删除zip文件
rm -rf elasticsearch-analysis-ik-7.17.7.zip
查看ik文件
root@8b71f6edf8d6:/usr/share/elasticsearch/plugins/ik# ls -ltotal 1432-rw-r--r--. 1 root root 263965 Jan 18 2022 commons-codec-1.9.jar-rw-r--r--. 1 root root 61829 Jan 18 2022 commons-logging-1.2.jardrwxr-xr-x. 2 root root 4096 Jan 18 2022 config-rw-r--r--. 1 root root 54953 Dec 1 2022 elasticsearch-analysis-ik-7.17.7.jar-rw-r--r--. 1 root root 736658 Jan 18 2022 httpclient-4.5.2.jar-rw-r--r--. 1 root root 326724 Jan 18 2022 httpcore-4.4.4.jar-rw-r--r--. 1 root root 1807 Dec 1 2022 plugin-descriptor.properties-rw-r--r--. 1 root root 125 Dec 1 2022 plugin-security.policy
重启es容器
docker restart es
补充:另外,分词器也支持自定义config文件

<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"><properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict"></entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords"></entry><!--用户可以在这里配置远程扩展字典 --><!-- <entry key="remote_ext_dict">words_location</entry> --><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> --></properties>
可以创建一个自己的分词文件my_ext_dict.dic(内容略)
2.4 springboot整合es
整合流程:将数据库查询读取出的数据,存入到es中,然后通过kibana网页端进行查询。
es的实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
@Document(indexName = "book_index",createIndex = true)
public class BookDoc {
@Id
@Field(type = FieldType.Long)
private Long id;
@Field(type = FieldType.Text)
private String title;
private String isbn;
@Field(type = FieldType.Text)
private String introduction;
@Field(type = FieldType.Keyword)
private String author;
@Field(type = FieldType.Double)
private BigDecimal price;
@Field(type = FieldType.Date,format = DateFormat.year_month_day)
private LocalDate createTime;
}Dao层
@Repository
public interface IBookDocDao extends ElasticsearchRepository<BookDoc,Long> {
}service及其实现类
public interface IBookDocService {
void loadFromDb();
List<BookDoc> findAll();
List<BookDoc> searchBooks(String keyword);
}@Service
public class BookDocServiceImpl implements IBookDocService {
@Autowired
private IBookDocDao bookDocDao;
@Autowired
private IBookService ibs;
@Autowired
private ElasticsearchRestTemplate elasticsearchRestTemplate;
@Override
public void loadFromDb() {
List<Book> books = ibs.findAll();
books.forEach(book->{
BookDoc bookDoc = new BookDoc();
bookDoc.setAuthor(book.getAuthor());
bookDoc.setId(book.getId());
bookDoc.setTitle(book.getTitle());
bookDoc.setIntroduction(book.getIntroduction());
bookDoc.setIsbn(book.getIsbn());
bookDoc.setCreateTime(book.getCreateTime().toInstant().atZone(ZoneId.systemDefault()).toLocalDate());
bookDocDao.save(bookDoc);
});
System.out.println("数据导入ES成功");
}
@Override
public List<BookDoc> findAll() {
Iterable<BookDoc> bookDocIterable = bookDocDao.findAll();
List<BookDoc> bookDocList = StreamSupport.stream(bookDocIterable.spliterator(), false)
.collect(Collectors.toList());
return bookDocList;
}
@Override
public List<BookDoc> searchBooks(String keyword) {
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.multiMatchQuery(keyword, "book_author", "book_title", "book_introduction"))
.build();
SearchHits<BookDoc> searchHits = elasticsearchRestTemplate.search(searchQuery, BookDoc.class);
List<BookDoc> bookDocs = new ArrayList<>();
searchHits.forEach(hit -> bookDocs.add(hit.getContent()));
return bookDocs;
}
}单元测试
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
@RunWith(SpringRunner.class)
public class BookDocServiceImplTest {
@Autowired
private IBookDocService ibds;
@Test
public void loadFromDb() {
ibds.loadFromDb();
}
@Test
public void findAll() {
ibds.findAll().forEach(System.out::println);
}
@Test
public void searchBooks() {
ibds.searchBooks("java").forEach(System.out::println);
}
}kibana查询测试
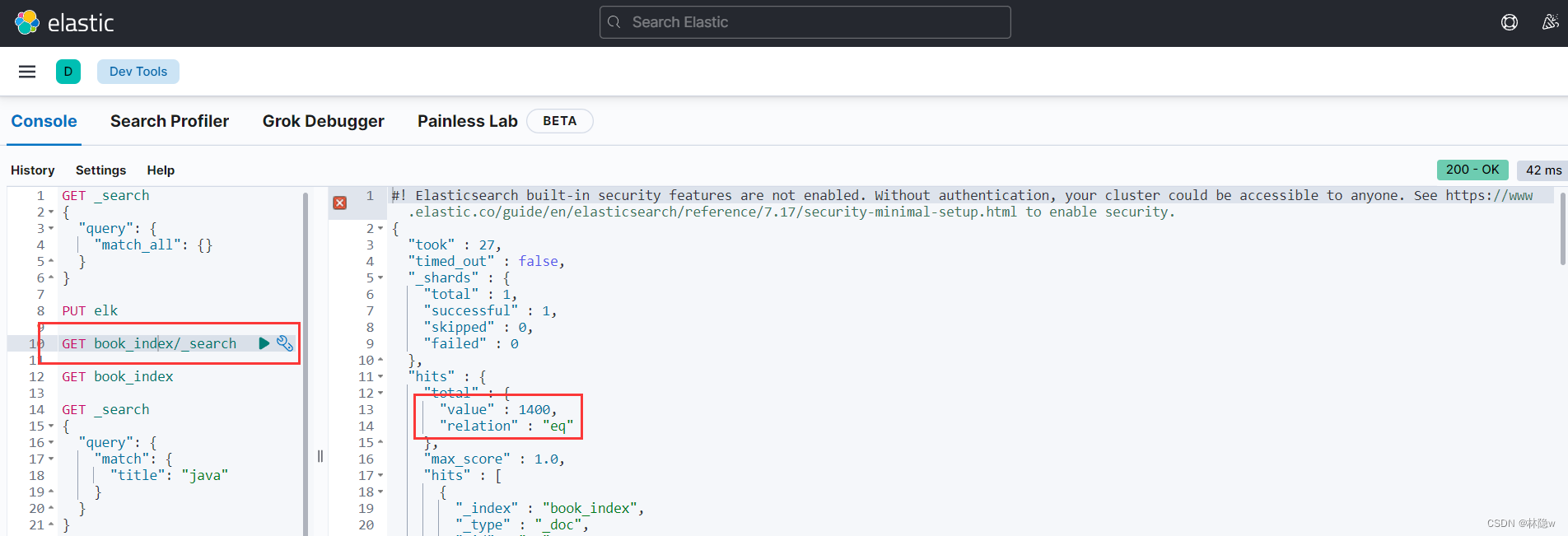
测试成功。
3、Kibana
docker安装kibana
docker pull kibana:7.17.7

创建kibana运行容器
docker run -it \
--name kibana \
--privileged \
--network docker_net \
--ip 172.18.12.78 \
-e "ELASTICSEARCH_HOSTS=http://192.168.***.***:9200" \
-p 5601:5601 \
-d kibana:7.17.7
安装运行好后就可以打开对应的地址进行访问查看。
4、Logstash
4.1 docker安装logstash
拉取镜像
[root@localhost ~]# docker pull logstash:7.17.7

创建docker容器(简易版)
docker run -it \
--name logstash \
--privileged \
-p 5044:5044 \
-p 9600:9600 \
--network docker_net \
--ip 172.18.12.79 \
-v /etc/localtime:/etc/localtime \
-d logstash:7.17.7
配置容器
进入容器
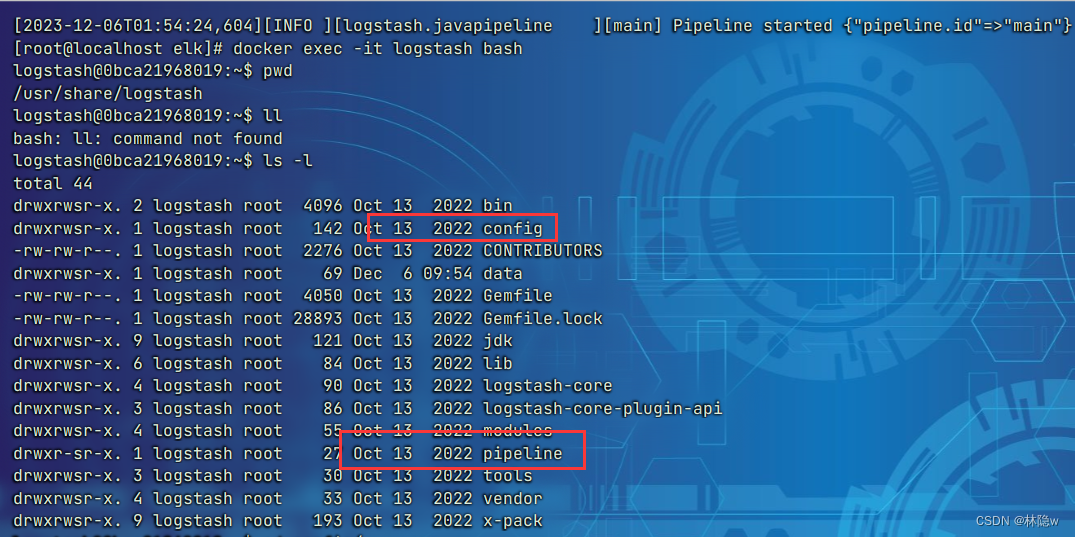
进入config
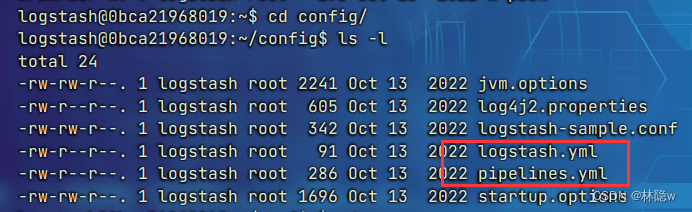
进入pipeline

编辑上述三个配置文件
1. logstash.yml
path.logs: /usr/share/logstash/logs
config.test_and_exit: false
config.reload.automatic: false
http.host: "0.0.0.0"
xpack.monitoring.elasticsearch.hosts: [ "http://192.168.***.***:9200" ]
2. piplelines.yml
# This file is where you define your pipelines. You can define multiple.
# # For more information on multiple pipelines, see the documentation:
# # https://www.elastic.co/guide/en/logstash/current/multiple-pipelines.html
#
- pipeline.id: main
path.config: "/usr/share/logstash/pipeline/logstash.conf"
3. logstash.conf
input {
tcp {
mode => "server"
host => "0.0.0.0"
port => 5044
codec => json_lines
}
}
filter{
}
output {
elasticsearch {
hosts => ["192.168.***.***:9200"] #elasticsearch的ip地址
index => "elk" #索引名称
}
stdout { codec => rubydebug }
}
保存配置,重启容器
docker restart logstash
注意:可能需要释放端口9600和5044
4.2 springboot整合logstash
引入依赖
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>7.3</version>
</dependency>创建logback-spring.xml
<?xml version="1.0" encoding="UTF-8"?>
<!-- 日志级别从低到高分为TRACE < DEBUG < INFO < WARN < ERROR < FATAL,如果设置为WARN,则低于WARN的信息都不会输出 -->
<!-- scan:当此属性设置为true时,配置文档如果发生改变,将会被重新加载,默认值为true -->
<!-- scanPeriod:设置监测配置文档是否有修改的时间间隔,如果没有给出时间单位,默认单位是毫秒。
当scan为true时,此属性生效。默认的时间间隔为1分钟。 -->
<!-- debug:当此属性设置为true时,将打印出logback内部日志信息,实时查看logback运行状态。默认值为false。 -->
<configuration scan="true" scanPeriod="10 seconds">
<!--1. 输出到控制台-->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<!--此日志appender是为开发使用,只配置最低级别,控制台输出的日志级别是大于或等于此级别的日志信息-->
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>DEBUG</level>
</filter>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} -%5level ---[%15.15thread] %-40.40logger{39} : %msg%n</pattern>
<!-- 设置字符集 -->
<charset>UTF-8</charset>
</encoder>
</appender>
<!-- 2. 输出到文件 -->
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!--日志文档输出格式-->
<append>true</append>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} -%5level ---[%15.15thread] %-40.40logger{39} : %msg%n</pattern>
<charset>UTF-8</charset> <!-- 此处设置字符集 -->
</encoder>
</appender>
<!--LOGSTASH config -->
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>192.168.***.***:5044</destination>
<encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder">
<!--自定义时间戳格式, 默认是yyyy-MM-dd'T'HH:mm:ss.SSS<-->
<timestampPattern>yyyy-MM-dd HH:mm:ss</timestampPattern>
<customFields>{"appname":"App"}</customFields>
</encoder>
</appender>
<root level="DEBUG">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="FILE"/>
<appender-ref ref="LOGSTASH"/>
</root>
</configuration>
创建controller
@RestController
@RequestMapping("/api/query")
@Slf4j
public class QueryController {
@Autowired
private IBookDocService iBookDocService;
@GetMapping("/helloLog")
public HttpResp helloLog() {
List<BookDoc> bookDocList = iBookDocService.findAll();
log.debug("从ES查询到数据:{}", bookDocList);
log.debug("测试logstash是否工作");
return HttpResp.success(bookDocList.subList(0, 10));
}
}4.3 配置kibana
首先,创建一个索引elk
![]()
创建索引模式

检索日志


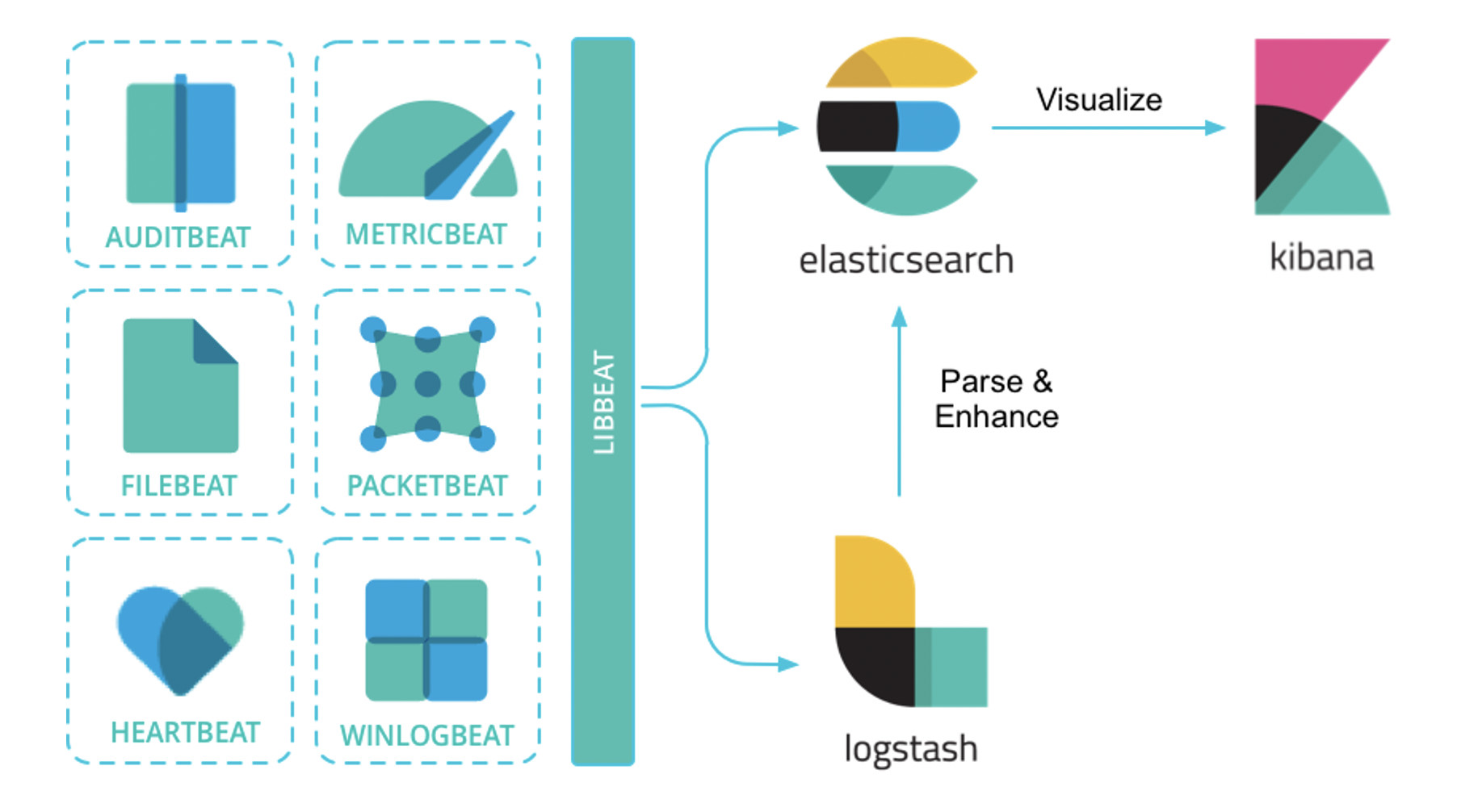
除了 ELK 组合,还有其他一些相关的工具和插件可以与 ELK 集成,以满足更复杂的需求,如 Beats(轻量级数据收集器)、Elastic APM(应用程序性能监测)、ElastAlert(告警工具)等。
总之,ELK 是一个功能强大、灵活可扩展且易于使用的组合,广泛应用于大数据搜索、分析和可视化领域,为用户提供了一套完整的解决方案。
参考
https://www.cnblogs.com/kkbill/p/11520398.html
感谢阅读,码字不易,多谢点赞!如有不当之处,欢迎反馈指出,感谢!