目录
查看
show functions -- 查看所有函数,共216个
show functions like '*array*' -- 模糊查询
desc function extended 函数名 -- 查看用法分类
根据函数输入行数与输出行数
UDF 一对一
用户自定义函数,即普通函数,例如space
UDAF 多对一
用户自定义聚合函数,即聚合函数
UDTF 一对多
用户自定义表生成函数,例如explode
分组
group by -- 相同值分组,右侧括号图
数学
取余
奇数:num % 2 = 1
pmod(num1,num2) -- 余数绝对值
字符串
- space(n) -- n个空格字符串
- 拼接
- concat(str1,str2,...strN) -- 写谁拼谁,有空则空
- concat_ws(separator, [string | array(string)]+) -- 同一个分隔符
- reverse(str) -- 倒序字符
数组
- split(str,expr) -- str拆成数组,按照正则表达式
- 列转数组
- collect_set -- 去重,去null
- collect_list -- 不去重
- sort_array(array) -- 排数组元素,只能升序
炸裂
explode(array | map)
语法
按行输出数组元素
select explode:只能一个UDTF
不支持group by
单独使用
select explode(split(space(3),' ')) ex; 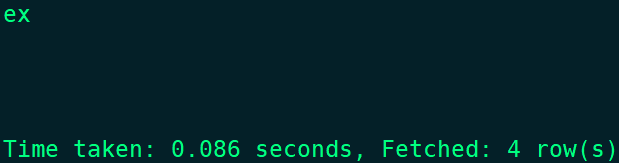
配套使用 lateral view
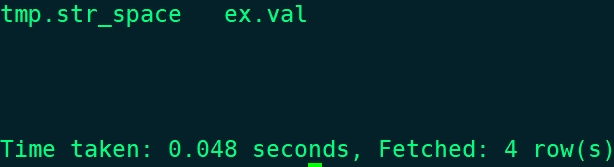
select * -- 全局查询
from (select space(3) str_space)tmp -- 字符串
lateral view explode(split(str_space,' ')) ex as val -- 一一对应作用
;
posexplode
语法:行为像explode,只是多了数组元素的位置
单独使用
select posexplode(split(space(3),' '));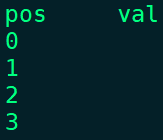
配套使用 lateral view
select *
from (select space(3) str_space)tmp -- 字符串
lateral view posexplode(split(str_space,' ')) posex as pos,val;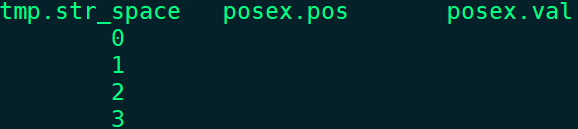
lateral view
语法
lateral view explode 表别名 [as 元素] -- 不返回null行
lateral view posexplode 表别名 [as 位置,元素] -- 返回null行作用:辅助扩展表数据
1.可以在select语句外使用;UDTF变成虚拟表
2.关联范围笛卡尔积(类比cross join:所有行笛卡尔积)
3.直接使用字段不需要嵌套
4.可多个
使用
-- 两个lateral view各一个笛卡尔积
-- 最后两张虚拟表笛卡尔积运算;共三次笛卡尔积
select *
from (select space(3) str_space)tmp -- 结果 4 * 4 = 16行
lateral view explode(split(str_space,' ')) es as val -- 4行
lateral view posexplode(split(str_space,' ')) pex as pos,val1 -- 4行
; 
排序 4by
order by 全局排序
对输入所有数据排序,只有一个reducer,无论设置是多少个,容易OOM
sort by 每个reducer内排序
默认一个reduce
所以使用前设置reduce个数
distribute by 分组
分发map端数据给reducer
分组规则:hash值相同分到一个组
类比group by + 聚合函数
分组规则:相同值分组
distribute by rand()保证每个分区的数据量基本一致,防止数据倾斜
cluster by
distribute by和sort by字段相同,可使用
只能asc
distribute by + sort by 使用场景
1.Map输出的文件大小不均
2.Reduce输出文件大小不均
3.小文件过多
4.文件超大
排名 聚合