说明
- 本文参考自林子雨老师的《大数据技术原理与应用(第三版)》教材内容,仅供学习和交流
HBase的实现原理
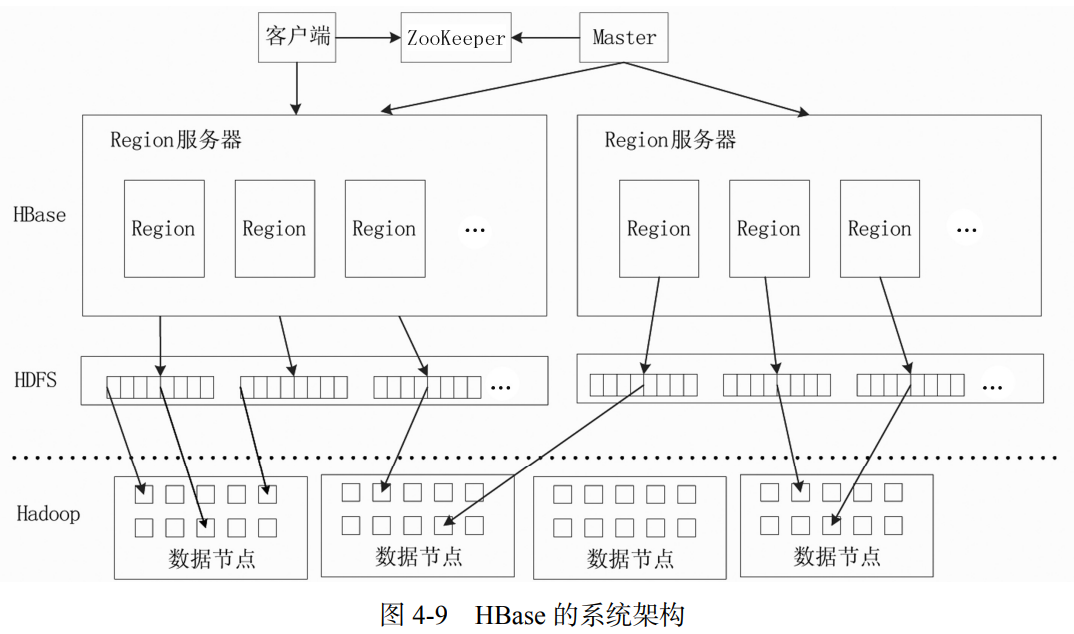
HBase功能组件
- HBase 的实现包括 3 个主要的功能组件:库函数,链接到每个客户端;一个 Master 主服务器(也称为 Master);多个 Region 服务器。
- Region 服务器负责存储和维护分配给自己的 Region,处理来自客户端的读写请求。
- Master 主服务器负责管理和维护HBase 表的分区信息,同时也负责维护 Region 服务器列表。Master 会实时监测集群中的 Region 服务器,把特定的 Region 分配到可用的 Region 服务器上,并确保整个集群内部不同 Region 服务器之间的负载均衡。当某个 Region 服务器因出现故障而失效时,Master 会把该故障服务器上存储的 Region 重新分配给其他可用的 Region 服务器。除此以外,Master 还处理模式变化,如表和列族的创建。
- 客户端并不是直接从 Master 主服务器上读取数据,而是在获得 Region 的存储位置信息后,直接从 Region 服务器上读取数据。
- 注意,HBase 客户端并不依赖于 Master 而是借助于 ZooKeeper 来获得 Region 的位置信息的,所以大多数客户端从来不和 Master 主服务器通信,这种设计方式使 Master 的负载很小。
表和 Region
对于每个 HBase 表而言,表中的行是根据行键的值的字典序进行维护的,表中包含的行的数量可能非常庞大,无法存储在一台机器上,需要分布存储到多台机器上。因此,需要根据行键的值对表中的行进行分区。每个行区间构成一个分区,被称为“Region”。
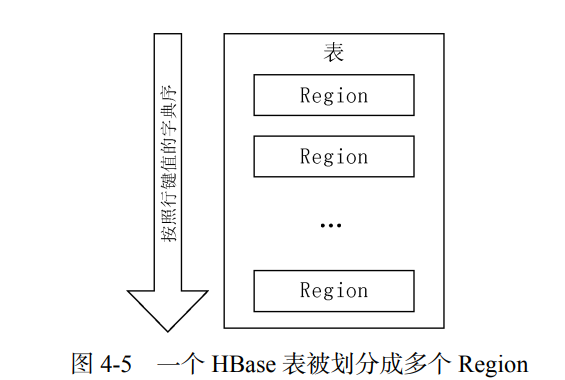
Region 包含了位于某个值域区间内的所有数据,是HBase负载均衡和数据分发的基本单位。这些 Region 会被分发到不同的 Region 服务器上。
初始时,每个表只包含一个 Region,随着数据的不断插入,Region 会持续增大。当一个 Region中包含的行数量达到一个阈值时,就会被自动等分成两个新的 Region,随着表中行的数量继续增加,就会分裂出越来越多的 Region

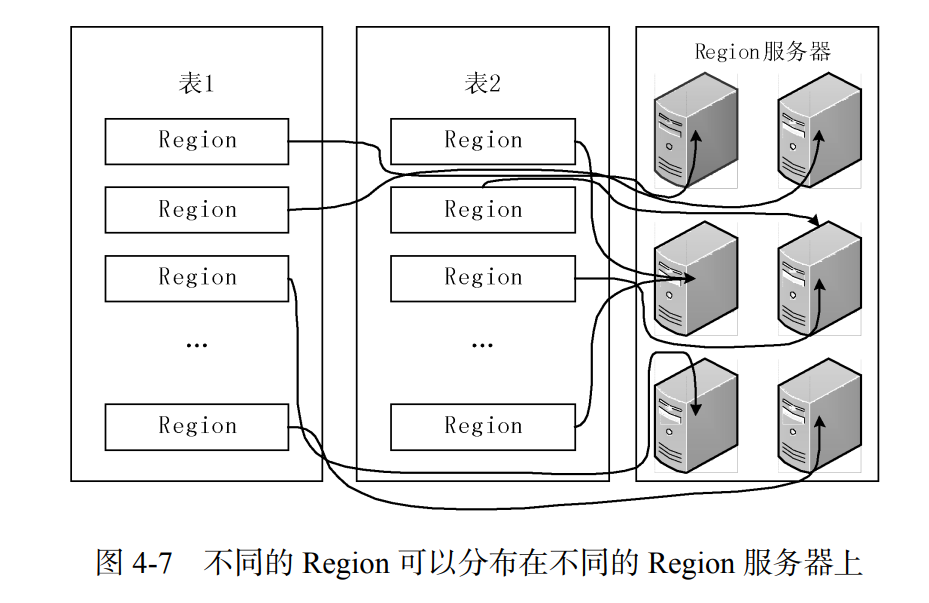
每个 Region 的默认大小是 100~200 MB。Master主服务器会把不同的 Region 分配到不同的 Region 服务器上,同一个 Region 不会被拆分到多个 Region 服务器上。
每个 Region 服务器负责管理一个 Region 集合,通常在每个 Region服务器上会放置 10~1000 个 Region。
Region 的定位
- 一个 HBase 的表可能非常庞大,会被分裂成很多个 Region,这些 Region 可被分发到不同的Region 服务器上。因此,必须设计相应的 Region 定位机制,保证客户端可以定位所需数据的Region服务器地址
- 每个 Region 都有一个 RegionID 来标识它的唯一性,一个 Region 标识符就可以表示成
“表名+开始主键+RegionID”。 - 为了定位每个 Region 所在的位置,可以构建一张映射表。映射表的每个条目(或每行)包含两项内容,一个是 Region 标识符,另一个是 Region 服务器标识。这个映射表包含了关于 Region 的元数据(即 Region和 Region 服务器之间的对应关系),因此也被称为“元数据表”,又名“.META.表”。
- 当一个 HBase 表中的 Region 数量非常庞大的时候,
.META.表的条目就会非常多,一个服务器保存不下,也需要分区存储到不同的服务器上,因此.META.表也会被分裂成多个 Region。为了定位这些 Region,需要构建新的映射表,记录所有元数据的具体位置,新的映射表就是“根数据表”,又名“-ROOT-表”。-ROOT-表不能被分割,永远只存在一个 Region 用于存放-ROOT-表。用来存放-ROOT-表的唯一一个Region,它的名字是在程序中被“写死”的,Master 主服务器永远知道它的位置。 - HBase 使用类似 B+树的三层结构来保存 Region 位置信息。
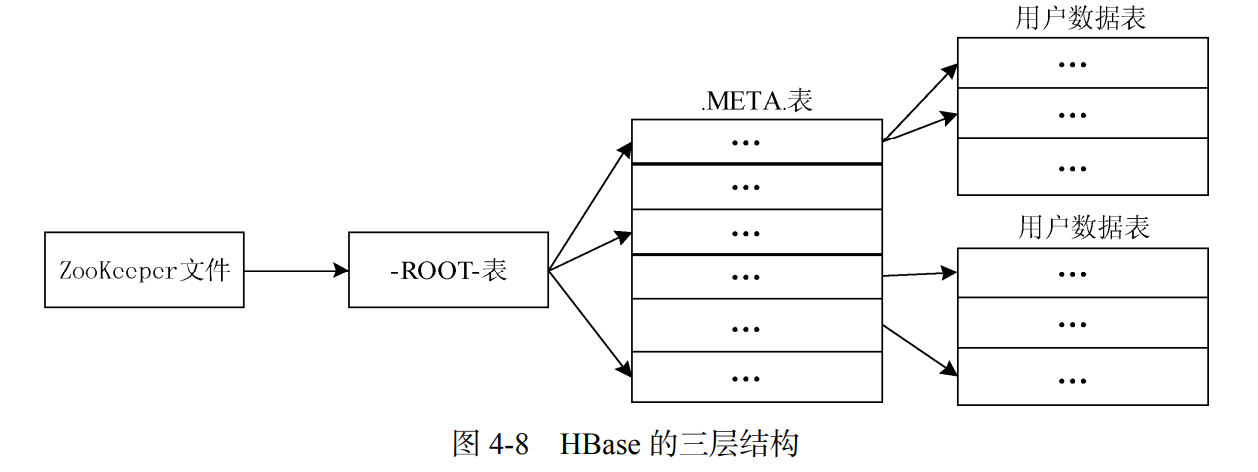
- HBase 三层结构中各层次的名称和作用
| 层次 | 名称 | 作用 |
|---|---|---|
| 第一层 | ZooKeeper文件 | 记录了-ROOT-表的位置信息 |
| 第二层 | -ROOT-表 |
记录.META.表的Region位置信息,-ROOT-表只能有一个 Region,通过-ROOT-表访问.META.表中的数据 |
| 第三层 | .META.表 |
记录用户数据表的Region位置信息,.META.表可以有多个 Region,保存HBase 中所有用户数据表的 Region 位置信息 |
为了加快访问速度,.META.表的全部 Region 都会被保存在内存中
客户端访问流程:客户端访问用户数据前,首先访问 ZooKeeper,获取
-ROOT-表的位置信息,然后访问-ROOT-表,获得.META.表的信息,接着访问.META.表,找到所需的 Region 具体的Region服务器,最后才会到该 Region 服务器读取数据。该过程需要多次网络操作,为加速寻址过程,一般会在客户端把查询过的位置信息缓存起来,访问相同的数据时,直接从客户端缓存中获取 Region 的位置信息,不需要每次都经历一个“三级寻址”过程。注意:随着 HBase 中表的不断更新,Region 的位置信息可能会发生变化,但是客户端缓存并不会本地检测 Region 位置信息是否失效,而是在需要访问数据时,从缓存中获取 Region 位置信息发现不存在时,才会判断出缓存失效。这时,客户端会再次经历“三级寻址”过程,重新获取最新的 Region 位置信息访问数据,并替换缓存中失效信息。
客户端从 ZooKeeper 服务器上获取
-ROOT-表地址后,通过“三级寻址”获取用户数据表所在的 Region 服务器,并直接访问该 Region 服务器获得数据,没有必要再连接Master 主服务器。因此,减轻了Master 主服务器的负载。
























![[GXYCTF2019]BabyUpload1](https://img-blog.csdnimg.cn/direct/9e4d749c17ee4e5780f7b5ee885a9e9b.png)



![[足式机器人]Part2 Dr. CAN学习笔记- 最优控制Optimal Control Ch07](https://img-blog.csdnimg.cn/direct/e696fd22eefb4c99b5dfeede070cdf48.png#pic_center)