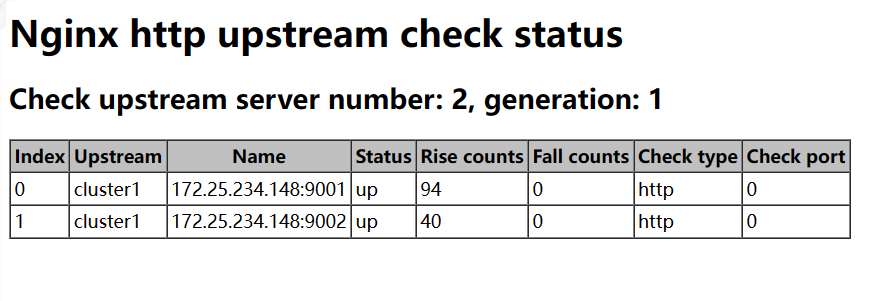
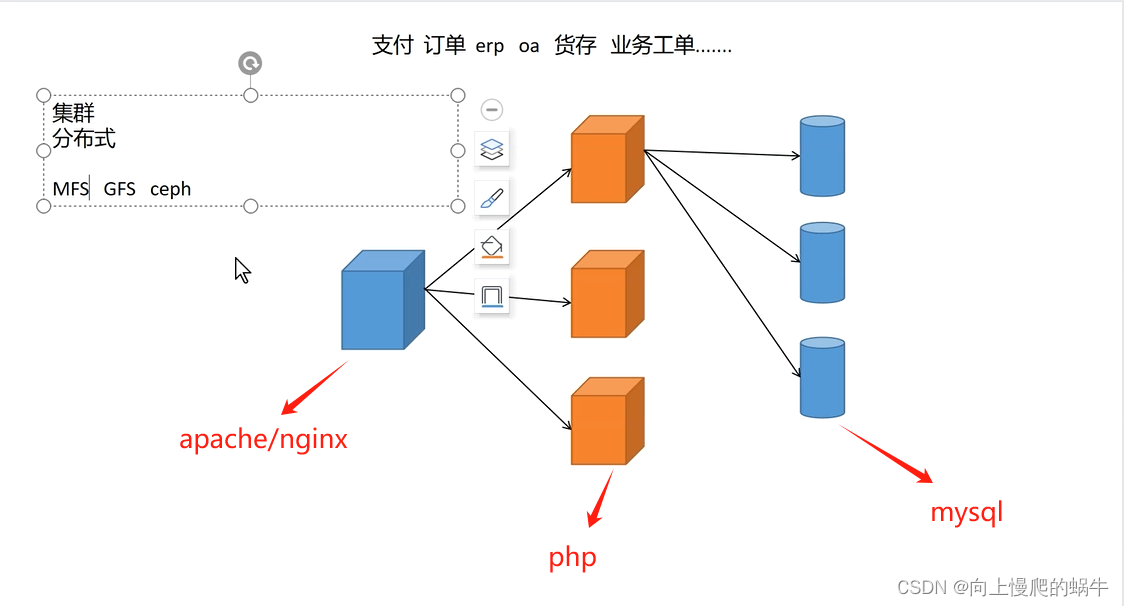
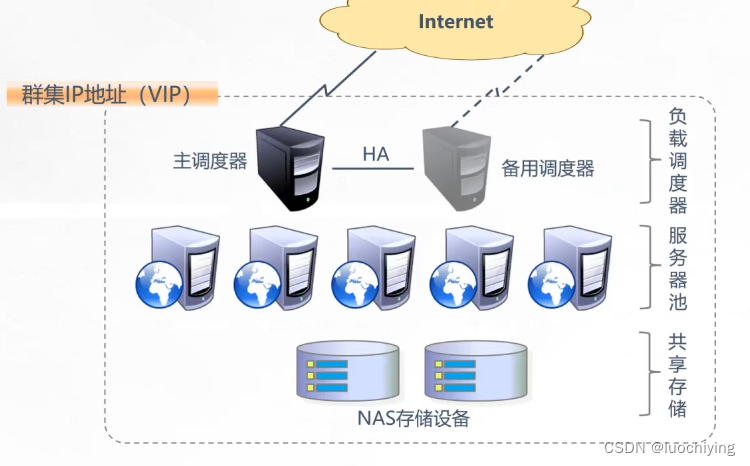
集群
节点介绍
Elasticsearch的协调节点并不是master节点。在Elasticsearch集群中,有几种不同类型的节点,其中包括:
- Master节点:负责集群范围内的管理和控制,例如创建或删除索引,决定哪些分片分配给哪个节点,以及跟踪哪些节点是加入或离开集群。
- Data节点:负责存储数据、执行数据相关的操作如增删改查、搜索和聚合。
- Ingest节点:负责预处理文档,在它们被索引之前执行各种转换。
- 协调节点(Coordinating only node):当一个节点设置成既不是master节点、data节点也不是ingest节点时,它就是一个纯协调节点。这种节点不存储数据,不执行数据处理,也不参与集群管理。
协调节点的主要功能是:
- 路由请求:当一个客户端发送请求到集群时,协调节点负责将请求路由到正确的节点。
- 汇聚结果:对于搜索请求,各个数据节点处理完自己拥有的分片数据后,将结果返回给协调节点。协调节点负责将这些结果合并,生成最终的响应发送给客户端。
- 减轻数据节点压力:协调节点可以处理查询结果的合并和减少,这样数据节点就可以集中精力处理本地的数据操作。
由于协调节点负责请求的路由和结果的聚合,将一些CPU密集型的任务从数据节点转移到协调节点,可以帮助提高集群性能,尤其是在处理复杂查询和大量的并发请求时。
在一些较小的集群或者负载较轻的场景下,节点可能会同时充当多种角色,包括数据节点、master节点和协调节点。但在大型或者负载较重的集群中,为了优化性能和提高稳定性,通常会专门配置一些节点作为协调节点。
Elasticsearch 的协调节点(Coordinating Node)是指那些没有被配置为专用角色的节点,它们是处理用户请求的节点,并且负责将这些请求路由到正确的数据节点上去。协调节点并不是专门的master节点,但一个节点可以同时是协调节点和master节点。
协调节点的主要作用和功能如下:
查询协调:当一个搜索请求发送到Elasticsearch集群时,协调节点负责将查询发送到拥有相关分片的数据节点上。每个数据节点执行其本地分片上的查询并将结果返回给协调节点,协调节点再合并这些结果,计算最终的查询结果,并将该结果返回给客户端。
聚合协调:和查询类似,协调节点还处理各种聚合操作。数据节点上的局部聚合结果会被发送回协调节点,由它来进行结果的最终合并和计算。
请求分发:协调节点接受客户端的写入(索引,更新,删除)请求,并根据文档的ID将请求路由到正确的数据节点上。
结果合并:对于数据分散在多个分片中的聚合查询,协调节点会负责合并各个分片返回的结果,形成最终的响应。
一个节点可以具有一个或多个角色:master节点,数据节点,协调节点,和ingest节点。Master节点负责集群-wide的操作,如创建或删除索引,跟踪哪些节点是集群的一部分以及决定哪些分片分配给相关数据节点等。
通常情况下,所有节点默认都会有协调能力,但你可以通过配置节点将某些节点专门用作协调节点,而不承担数据节点的工作负载。这样做可以提高大型复杂查询处理的效率,因为这些节点可以专门用来进行查询聚合和结果的合并。在一个大规模的Elasticsearch集群中,有时会有专门的节点来承担协调节点的职责,这样可以提高性能。
节点配置
Elasticsearch中有多种类型的节点,包括主节点(Master)、数据节点(Data)、协调节点(Coordinating)、机器学习节点(ML)等。节点的角色可以在 elasticsearch.yml 配置文件中定义,该配置文件通常位于 Elasticsearch 安装目录下的 config 文件夹。
下面是不同类型节点的基本配置示例:
主节点(Master Node)
主节点负责集群的管理工作,比如创建或删除索引,追踪哪些节点是加入或离开集群的等。可以通过如下配置来指定一个节点为主节点:
node.master: true
node.data: false
node.ingest: false
node.ml: false
xpack.ml.enabled: false
在这个配置中,我们启用了主节点角色并禁用了数据、Ingest处理和机器学习功能,这样节点就专注于集群管理相关的任务。
数据节点(Data Node)
数据节点负责存储数据,执行数据相关的操作,比如CRUD、搜索和聚合。数据节点的配置示例:
node.master: false
node.data: true
node.ingest: false
node.ml: false
xpack.ml.enabled: false
此配置禁用了主节点的角色,并将节点设定为数据节点,同时也禁用了Ingest处理和机器学习功能。
协调节点(Coordinating Node)
协调节点主要负责查询协调,它们会接受客户端的搜索请求,然后将这些请求分发到有相关数据的节点上去,最后再将结果合并返回给客户端。一个纯粹的协调节点不持有数据,也不执行任何与数据相关的处理。配置如下:
node.master: false
node.data: false
node.ingest: false
node.ml: false
xpack.ml.enabled: false
注意:在默认情况下,每个节点都是主节点、数据节点以及协调节点。如果您不对节点进行任何配置,它将同时承担所有这些角色。特别地,当集群只有一个节点时,该节点必然是主节点和数据节点。
混合节点
如果你希望某个节点同时具有多种角色,例如同时是主节点和数据节点,可以组合上述配置:
node.master: true
node.data: true
node.ingest: true
node.ml: false
xpack.ml.enabled: false
在这个示例中,此节点既是主节点也是数据节点,还具备处理 Ingest pipeline 的能力,但没有启用机器学习功能。
希望上述配置能够帮助你理解如何在 Elasticsearch 中配置不同类型的节点。有了这些基础之后,你可以根据集群的需要和机器的资源情况来配置合适的节点角色。
增加节点
Elasticsearch节点使用两种不同的方式来发现另一个节点:广播或单播。Elasticsearch可以同时使用两者,不过默认的配置是仅使用广播,因为单播需要已知节点的列表来进行连接。
删除节点
主从同步
Elasticsearch 的数据复制机制既有同步也有异步的特点:
同步复制(Primary-Replica Synchronization):当一个文档被索引(创建、更新或删除)时,这个操作首先在主分片(primary shard)上执行,然后在确认操作成功后,同步复制到相关的副本分片(replica shard)。Elasticsearch 会等待指定数量的副本分片(可以配置,通过
index.write.wait_for_active_shards设置)报告操作成功才认为整个写操作完成。这种机制确保数据的持久性和一致性。异步复制(Translog and Flush):虽然副本的同步基本上是实时进行的,但是对于数据的持久化存储,Elasticsearch 会将操作写入事务日志(translog)。在某个时间点(可以是基于时间间隔,也可以是基于 translog 大小等因素),Elasticsearch 会触发一个刷新(flush)操作,将 translog 中的操作持久化到硬盘上的 Lucene 索引文件中。这个过程是异步的,主要是为了优化性能和减少磁盘 I/O。
副本分片的延迟恢复(Delayed Recovery):在某些情况下,如集群重新平衡或节点重新加入集群,副本分片可能会进行延迟恢复,这个过程中副本分片与主分片的同步可能是异步的,并且可能会有延迟。
总的来说,Elasticsearch 设计了一个既能确保数据可靠性又能提供良好写入性能的数据同步机制。在默认配置下,主分片到副本分片的复制是近乎实时的,但是持久化到磁盘的操作则是异步发生的,这样在不牺牲数据安全的前提下,确保了集群的高效性能。
选主
Elasticsearch认为所有的节点都有资格成为主节点,除非某个节点的node.master选项设置为false。
将minimum_master_nodes设置为高于1
的数量,可以预防集群产生脑裂(splitbrain)的问题。修改elasticsearch.yml文件中的discovery.zen.minimum_master_nodes,将其设置为符合集群需求的数值,建议设置为"节点总数/2+1"。
什么是脑裂?
通常是在重负荷或网络存在问题的情况下Elasticsearch集群中一个或多个节点失去了和主节点的通信,开始选举新的主节点,并且继续处理请求。为了防止这种情况的发生,你需要根据集群节点的数量来设置discovery.zen.minimum_master_nodes如果节点的数量不变,将其设置为集群节占的总数;否则将节点数除以2并加1是一个不错的选择,因为这就意味着如果一个或多个节点失去了和其他节点的通信,它们无法选举新的主节点来形成新集群,因为对于它们不能获得所需的节点(可成为主节点的节点)数量(超过一半)。
查看集群节点状态信息:
GET /_cluster/state/master_node,nodes?pretty
返回集群名称、集群id、master节点id和各个节点名称、id、ip地址、属性。
如何判断节点或者master可用?
master每秒(discovery.zen.fd.ping_interval)ping 其他节点,如果超过30s(discovery.zen.fd.ping_timeout)没回应,超过3次ping操作(discovery.zen.fd.ping_retries),宣布节点失联。
master 选举的大致步骤:
初始化选举过程:当一个节点认为当前的 master 不可用(例如,响应超时),或者集群正在启动的时候,它会尝试发起 master 选举。
节点自我评估:在选举开始之前,每个节点首先确定自己是否有资格参与 master 节点的选举。只有在
elasticsearch.yml配置文件中被设置为 master-eligible 的节点(即node.master: true)才能成为 master。通常只有少数节点会被配置为 master-eligible,以避免选举过程太过复杂。发出选票:集群中的 master-eligible 节点会相互通信,交换它们的状态信息。每个 master-eligible 节点都可以给其他节点投票。通常情况下,节点会优先考虑版本较新的、集群状态版本较高的或是 ID 较小的节点。
投票计数:每个 master-eligible 节点收集到的投票会被计数。在默认情况下,需要集群中超过半数的 master-eligible 节点投票,一个节点才能成为 master。这个机制是为了确保集群的「脑裂」(split-brain)问题最小化。
宣布结果:一旦一个节点获得了足够的票数,它会被宣布为新的 master 节点。其他节点收到新 master 的消息后,会与其同步集群状态。
在 Elasticsearch 中,为了确保 master 节点的稳定选举和最小化脑裂的风险,它采用了类似于 Raft 或 Paxos 这样的一致性算法的简化版本。最新版本的 Elasticsearch 还引入了 cluster.initial_master_nodes 配置选项来控制集群启动过程中的 master 选举行为。
负载均衡
Elasticsearch 的负载均衡机制是基于 Elasticsearch 集群的内在特性,其中包括分片、复制和集群协调。以下是一些关键点,包括 Elasticsearch 如何处理负载均衡:
分片(Shards):
Elasticsearch 集群存储数据时,会将其分成多个分片。每个分片是一个独立的索引,并且可以存在于任何集群内的节点上。将数据分散存储可以提高性能和可扩展性。复制(Replicas):
为了提供高可用性和读取操作的负载均衡,Elasticsearch 允许为每个主分片创建多个复制分片。复制分片可以在不同的节点上,从而提供数据冗余和读取操作的负载均衡。集群协调:
Elasticsearch 集群内有一个名为“主节点”的特殊节点负责管理集群的元数据和均衡分片。当节点加入或离开集群时,主节点会重新分配分片,以确保集群保持均衡。分片分配:
Elasticsearch 使用分片分配算法使得分片在集群的各个节点中尽可能均匀。这个算法考虑多个因素,如节点的硬件资源、当前节点上分片的数量和大小等。请求路由:
当客户端发送搜索请求到 Elasticsearch 时,请求可以先发送到任意节点。该节点会成为协调节点(coordinating node),负责将请求转发到存储着相关数据的分片所在节点上。读写操作:
写入(索引)操作通常会先发送到主分片,然后同步到相关的复制分片上。读取(搜索)操作可以在任意的主分片或其复制分片上执行,从而提供负载均衡。自适应负载均衡:
Elasticsearch 有能力监控其节点的健康状态和负载情况。如果必要,它可以通过迁移分片或调整请求路由逻辑来优化负载均衡。客户端负载均衡:
除了 Elasticsearch 集群自身的负载均衡机制,客户端也可以实现负载均衡。许多 Elasticsearch 客户端库提供了对请求进行负载均衡的功能,可以智能地选择发送请求的节点。
总而言之,Elasticsearch 通过其精心设计的分片和复制机制,以及集群内的智能分片分配和请求路由策略来实现负载均衡。这些策略的目标是确保集群高效地工作,以及在节点故障或负载变化时保持高可用性和稳定性。
集群配置
Elasticsearch 集群配置是一个比较复杂的过程,因为它需要考虑诸多因素,比如硬件资源、网络配置、安全设置、负载平衡、数据冗余和备份等。下面给出一些基础的 Elasticsearch 集群配置选项和示例。
Elasticsearch.yml 配置文件示例
以下是一个 Elasticsearch 数据节点的示例配置文件 elasticsearch.yml:
# 集群名称
cluster.name: my-elasticsearch-cluster
# 节点名称
node.name: node-1
node.attr.rack: r1
# 数据节点配置
node.master: true # 该节点可以是master节点
node.data: true # 该节点可以存储数据
node.ingest: true # 该节点可以处理数据预处理
# 网络配置
network.host: 192.168.1.10
http.port: 9200
# 发现模块配置
discovery.seed_hosts: ["192.168.1.10", "192.168.1.11", "192.168.1.12"]
cluster.initial_master_nodes: ["node-1", "node-2"]
# 其他配置
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
# 堆内存设置
heap.size: 2g
其他重要配置项
- jvm.options: JVM 配置,用于设置内存等参数。
- discovery.zen.minimum_master_nodes: 在
zen发现中,用于防止脑裂的最小 master 节点数,3.2 版本已移除。 - index.number_of_shards 和 index.number_of_replicas: 设置索引的主分片和副本分片数。
节点类型配置
Elasticsearch 7.x 之后引入了新的节点角色:
- Master-eligible node: 能够被选举为管理节点的节点,负责集群的管理和控制。
- Data node: 存储数据,并执行与数据相关的操作(CRUD, search, aggregations)。
- Ingest node: 处理文档预处理,如enrichment, geo-ip等。
- Coordination node: 只处理客户端请求,将操作分发到其他节点,不存储数据,没有计算负载。
- Machine learning node: 执行机器学习相关的任务。
- Transform node: 执行转换任务,比如持续性的聚合。
集群健康和监控
创建集群后,监控其状态非常重要。Elasticsearch 提供了许多 API 来监控集群健康和性能:
# 查看集群健康状态
GET /_cluster/health
# 查看节点状态
GET /_cat/nodes?v
# 查看索引信息
GET /_cat/indices?v
集群健康状态:
{
//集群名称
"cluster_name" : "es-cn-09k1wi493002cgixs",
//状态
"status" : "green",
//指示 REST API 是否达到调用中设置的超时
"timed_out" : false,
//集群节点数
"number_of_nodes" : 3,
//集群数据节点数
"number_of_data_nodes" : 3,
//活跃主分片的数量
"active_primary_shards" : 570,
//活跃分片的数量
"active_shards" : 1272,
//从一个节点重新定位或迁移到另一个节点的分片数量
"relocating_shards" : 0,
//处于初始化状态的分片数量
"initializing_shards" : 0,
//未分配给节点的分片数量。 这通常是由于设置的副本数大于节点数。 在启动过程中,尚未初始化或正在初始化的分片将被计入此处
"unassigned_shards" : 0,
//将分配的分片数量,但它们的节点配置为延迟分配
"delayed_unassigned_shards" : 0,
//集群级别的待处理任务的数量,例如集群状态的更新、索引的创建和分片重定位。 它应该很少是 0 以外的任何值。
"number_of_pending_tasks" : 0,
//
"number_of_in_flight_fetch" : 0,
//集群任务在队列中等待的最长时间
"task_max_waiting_in_queue_millis" : 0,
//集群所需的活动分片的百分比
"active_shards_percent_as_number" : 100.0
}
节点状态:

备注
- 配置文件中的一些值(比如网络地址、节点名称、集群名称)需要根据你的实际环境来设置。
- Elasticsearch 的配置文件是 YAML 格式的,因此格式必须严格符合 YAML 语法。
- 如果你运行 Elasticsearch 的版本是 7.x 或者 8.x,请确保你的配置与你的版本兼容,因为某些配置选项可能在不同版本之间有所不同。
配置好 Elasticsearch 集群后,你应该根据你的使用场景做适当的调整和优化,比如调整 JVM 设置、索引配置、分片策略和内存分配等。基于你的数据量、查询复杂度和性能需求,可能需要进行多次调整才能找到最适合的配置。