背景
OpenAI has made waves online with its innovative embedding and transcription models, leading to breakthroughs in NLP and speech recognition. These models enhance accuracy, efficiency, and flexibility while speeding up transcription services.
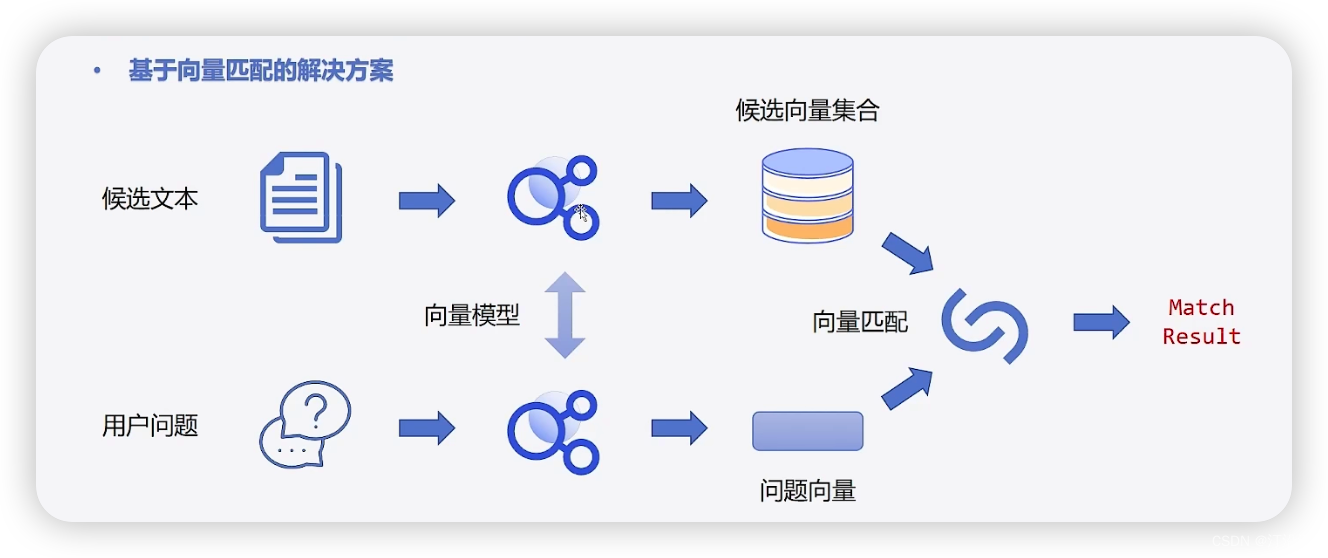
An embedding is a way of representing words or phrases as vectors in a high-dimensional space(按我理解,就是句子长度). By mapping words to vectors, we can capture the meaning of words and their relationships with other words in a way that can be easily processed by machine learning algorithms.
The benefit of using embeddings is that they allow us to capture the meaning of words in a way that is more nuanced than simply counting the number of times a word appears in a document. For example, consider the words “cat” and “dog”. These words may appear in similar contexts and therefore have similar embeddings because they are both types of pets. By contrast, the words “cat” and “computer” will likely have very different embeddings because they are not semantically related.
import numpy
import openai
from utils.embeddings_utils import get_embedding, cosine_similarity
texts = ["eating food", "I am hungry", "I am traveling" , "exploring new places"]
resp = openai.embeddings.create(
input= texts,
model="text-embedding-ada-002")
embedding_a = resp.data[0].embedding
embedding_b = resp.data[0].embedding
embedding_c = resp.data[0].embedding
embedding_d = resp.data[0].embedding
li = []
for ele in resp.data:
li.append(ele.embedding)
## Finding text similarity percentages
for i in range(len(texts) - 1):
for j in range(i + 1, len(resp.data)):
print("text similarity percentage between",texts[i], "and", texts[j],"is ",
numpy.dot(resp.data[i].embedding,resp.data[j].embedding)*100)
启用ada model.
给四个句子。
计算各自vector。
求相似性
结果
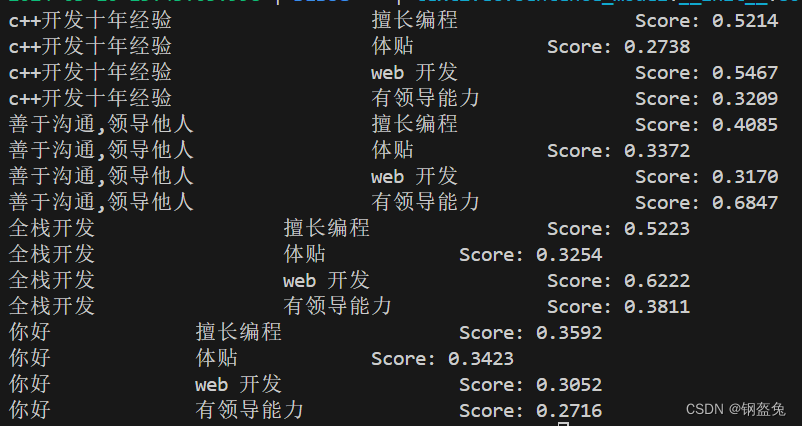
text similarity percentage between eating food and I am hungry is 84.51718333701376
text similarity percentage between eating food and I am traveling is 78.61389065433136
text similarity percentage between eating food and exploring new places is 80.65952658185421
text similarity percentage between I am hungry and I am traveling is 84.4268901528142
text similarity percentage between I am hungry and exploring new places is 76.50161515688097
text similarity percentage between I am traveling and exploring new places is 84.34661265708127