本篇是基于上篇单链表所作,推荐与上篇配合阅读,效果更加
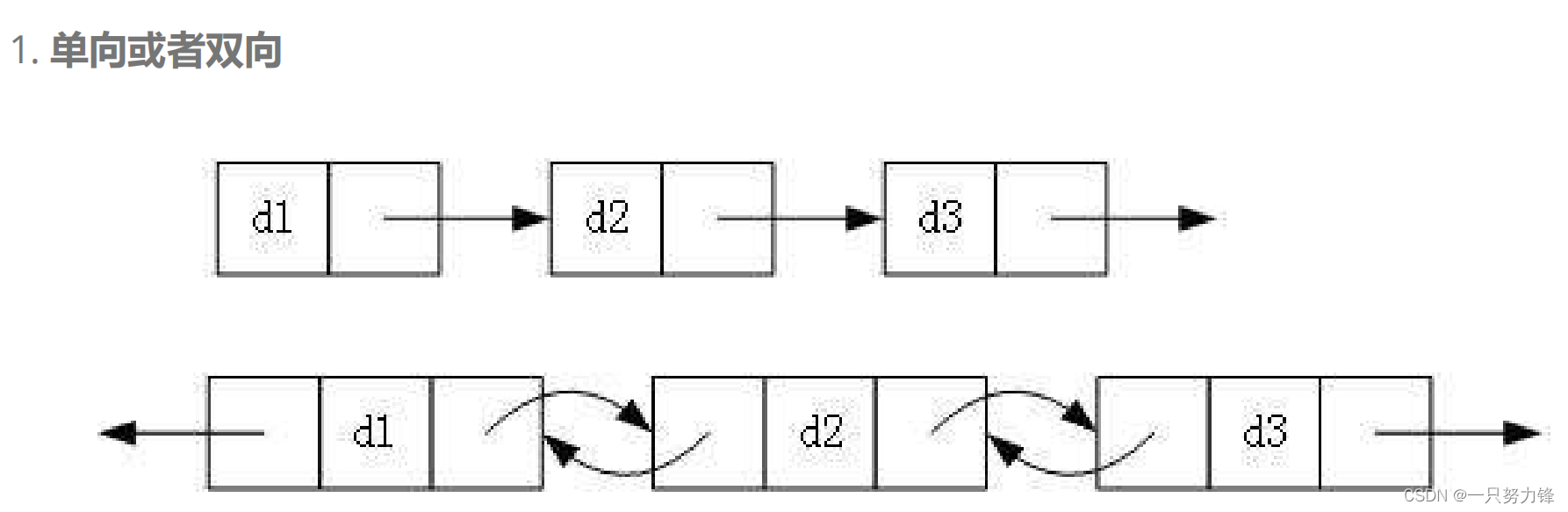
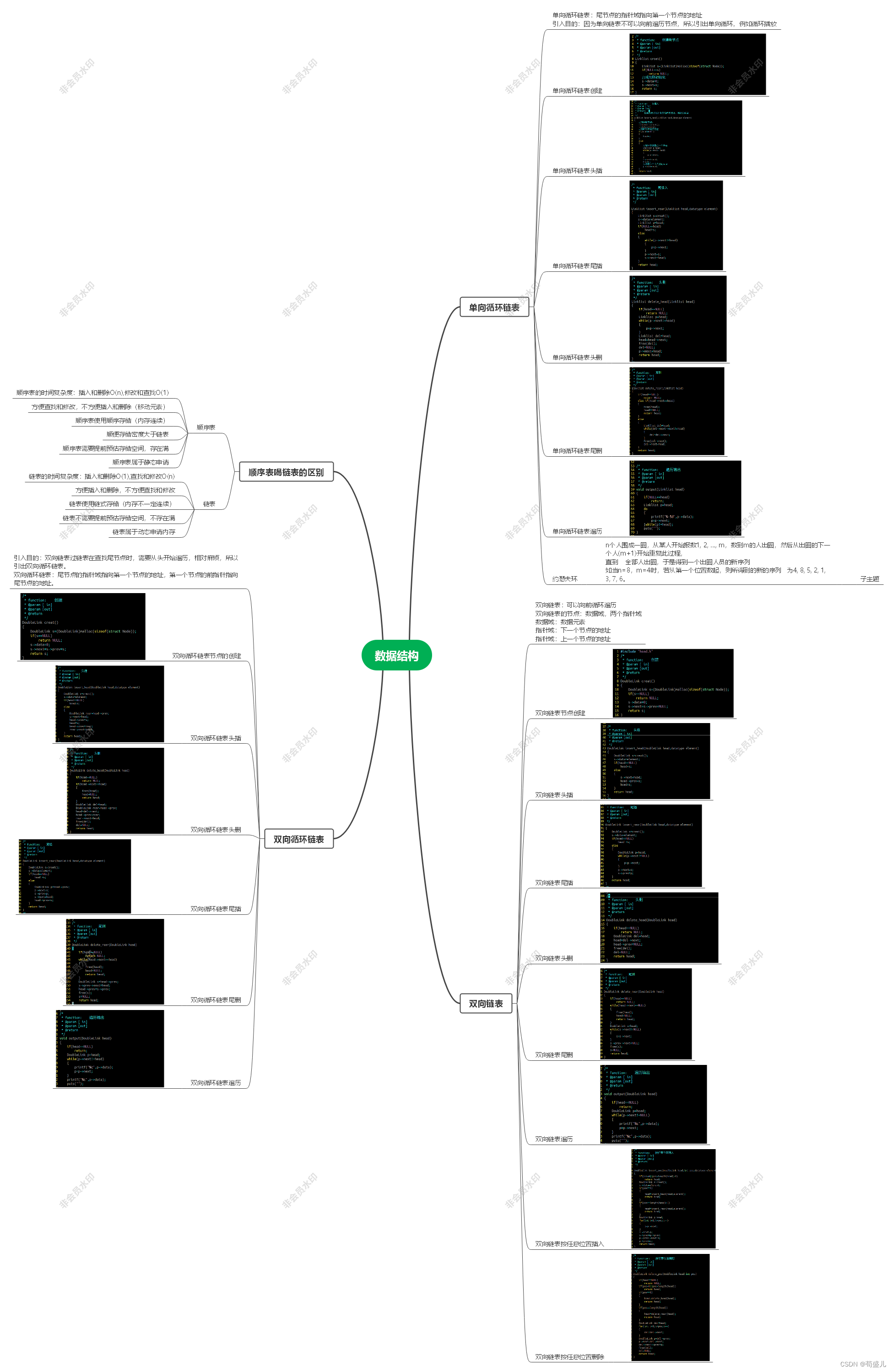
1.链表的分类
 我们一般叫这个头为哨兵位
我们一般叫这个头为哨兵位
1.带头单向循环链表:

2.带头单向不循环链表

3.带头双向循环链表

4.带头双向不循环链表

5.不带头单向循环链表

6.不带头单向不循环链表

7.不带头双向循环链表
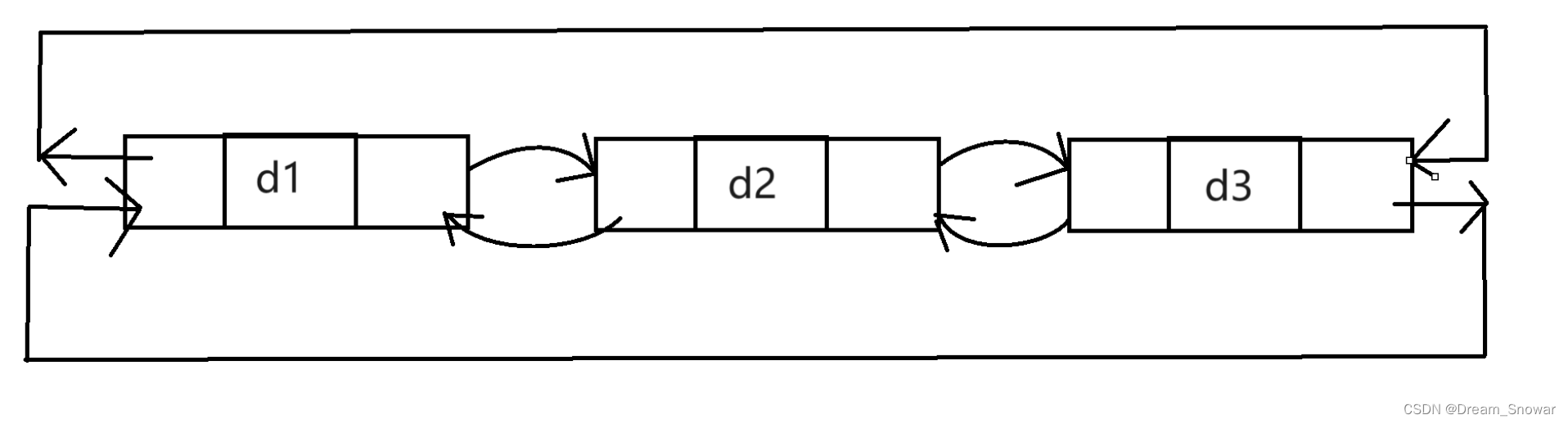
8.不带头双向不循环链表

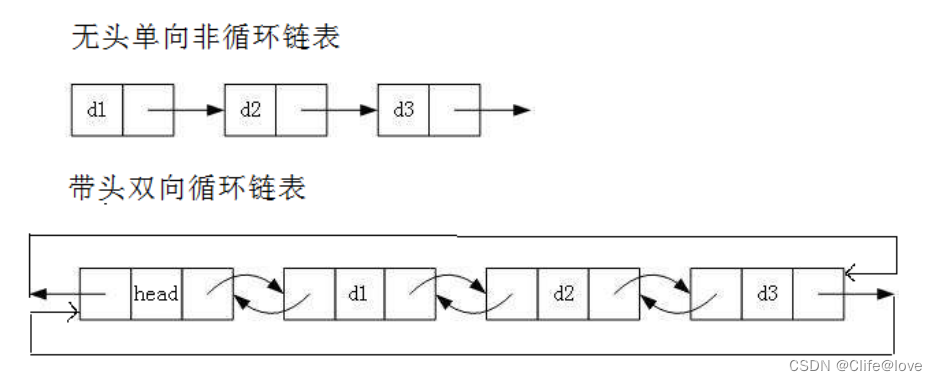
虽然有这么多的链表的结构,但是我们实际中最常用还是两种结构: 单链表 和 双向带头循环链表1. 无头单向非循环链表:结构简单,⼀般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。2. 带头双向循环链表:结构最复杂,⼀般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了。
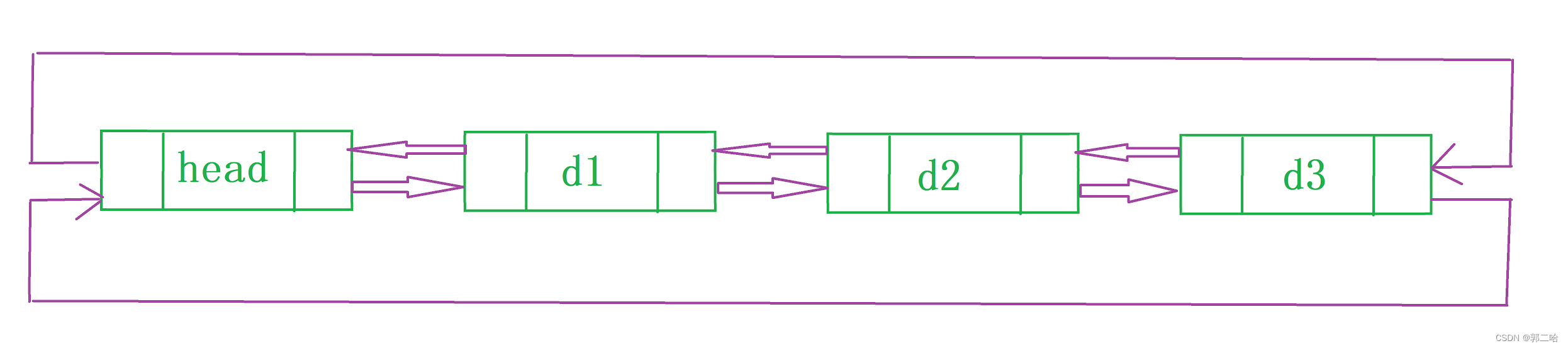
2.双向带头循环链表
我们还是经典三个文件:
我们先定义头文件所需要的函数
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
//定义双向链表中节点的结构
typedef int LTDataType;
typedef struct ListNode {
LTDataType data;
struct ListNode* prev;
struct ListNode* next;
}LTNode;
//注意,双向链表是带有哨兵位的,插入数据之前链表中必须要先初始化一个哨兵位
//void LTInit(LTNode** pphead);
LTNode* LTInit();
//void LTDesTroy(LTNode** pphead);
void LTDesTroy(LTNode* phead); //推荐一级(保持接口一致性)
void LTPrint(LTNode* phead);
//不需要改变哨兵位,则不需要传二级指针
//如果需要修改哨兵位的话,则传二级指针
void LTPushBack(LTNode* phead, LTDataType x);
void LTPushFront(LTNode* phead, LTDataType x);
//头删、尾删
void LTPopBack(LTNode* phead);
void LTPopFront(LTNode* phead);
//查找
LTNode* LTFind(LTNode* phead, LTDataType x);
//在pos位置之后插入数据
void LTInsert(LTNode* pos, LTDataType x);
//删除pos位置的数据
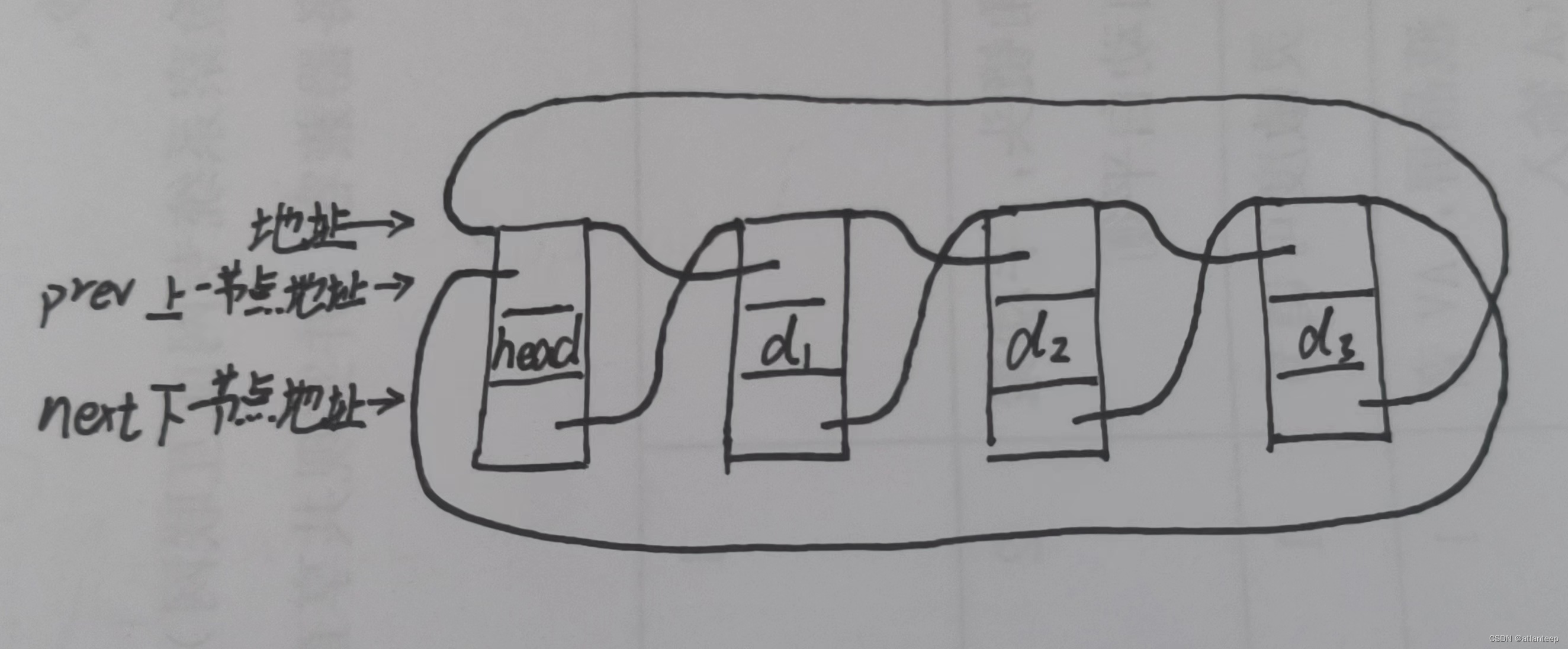
void LTErase(LTNode* pos);首先我们还是得先定义节点,由于是双向链表,所以节点内存在两个节点的地址,一个是前驱节点的(指向其前一个节点),一个是尾结点的(指向其后一个节点)
![]()
这一段代码,是为了确保数据类型
我们节点定义成这样:
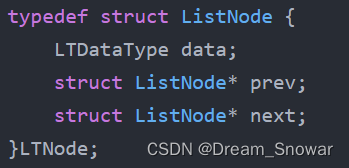
接下来又是完成各个功能:增,删,查,改。但是,由于我们长线的是带头的链表,所以我们需要对头初始化
3.初始化
我们先定义初始化函数,然后写函数:
void LTInit(LTNode** pphead);void ltinit(ltnode** pphead) {
*pphead = (ltnode*)malloc(sizeof(ltnode));
if (*pphead == null) {
perror("malloc fail!");
exit(1);
}
(*pphead)->data = -1;
(*pphead)->next = (*pphead)->prev = *pphead;
}和上回写单链表差不多,检测开辟是否成功,成功就接着给数据赋值,由于此时只有一个节点,即哨兵节点,且是循环链表,所以存放的前驱和尾节点就是哨兵节点自己
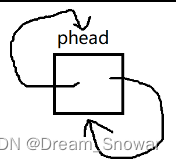
所以我们可以得出,如果哨兵节点的next指针或者prev指针指向自己,说明当前链表为空。
4.创建新的节点
我们写法和上次差不多
LTNode* LTBuyNode(LTDataType x) {
LTNode* newnode = (LTNode*)malloc(sizeof(LTNode));
if (newnode == NULL) {
perror("malloc fail!");
exit(1);
}
newnode->data = x;
newnode->next = newnode->prev = newnode;
return newnode;
}只是这回,多了一个前驱节点,我们定义时间默认前驱和后去节点指向的是本身。
但是既然我们都这么写了一个创建新节点的函数,那么我们可不可以用这个函数直接去进行哨兵节点的创建?
答案是肯定的,我们首先先改变以下我们定义的函数,
LTNode* LTInit();然后调用创建新节点的函数,得到哨兵节点
LTNode* LTInit() {
LTNode* phead = LTBuyNode(-1);
return phead;
}
5.头插和尾插
注意:头插,是把新的节点插在第一个节点前,不是哨兵节点前
头插和尾插,头删和尾删的思路整体和单链表一致,我就不详细说明了,直接上代码
定义函数:
void LTPushBack(LTNode* phead, LTDataType x);
void LTPushFront(LTNode* phead, LTDataType x);
函数代码示例:
//尾插
void LTPushBack(LTNode* phead, LTDataType x) {
assert(phead);
LTNode* newnode = LTBuyNode(x);
//phead phead->prev(ptail) newnode
newnode->next = phead;
newnode->prev = phead->prev;
phead->prev->next = newnode;
phead->prev = newnode;
}
//头插
void LTPushFront(LTNode* phead, LTDataType x) {
assert(phead);
LTNode* newnode = LTBuyNode(x);
//phead newnode phead->next
newnode->next = phead->next;
newnode->prev = phead;
phead->next->prev = newnode;
phead->next = newnode;
}
不懂的你们可以再看看图:
6.头删和尾删
定义函数:
void LTPopBack(LTNode* phead);
void LTPopFront(LTNode* phead);函数代码示例:
//尾删
void LTPopBack(LTNode* phead) {
assert(phead);
//链表为空:只有一个哨兵位节点
assert(phead->next != phead);
LTNode* del = phead->prev;
LTNode* prev = del->prev;
prev->next = phead;
phead->prev = prev;
free(del);
del = NULL;
}
//头删
void LTPopFront(LTNode* phead) {
assert(phead);
assert(phead->next != phead);
LTNode* del = phead->next;
LTNode* next = del->next;
//phead del next
next->prev = phead;
phead->next = next;
free(del);
del = NULL;
}7.查找
整体思路还是遍历,和单链表十分相似
定义函数:
LTNode* LTFind(LTNode* phead, LTDataType x);函数代码示例:
LTNode* LTFind(LTNode* phead, LTDataType x) {
assert(phead);
LTNode* pcur = phead->next;
while (pcur != phead)
{
if (pcur->data == x) {
return pcur;
}
pcur = pcur->next;
}
return NULL;
}8.在pos位置之后插入数据
这个和单恋表的也很相似,多了一个prev指针而已,写的时候要注意顺序,函数定义我就不写了
函数代码示例:
//在pos位置之后插入数据
void LTInsert(LTNode* pos, LTDataType x) {
assert(pos);
LTNode* newnode = LTBuyNode(x);
//pos newnode pos->next
newnode->next = pos->next;
newnode->prev = pos;
pos->next->prev = newnode;
pos->next = newnode;
}9.删除pos位置的数据
这个和单链表还是一样的,遍历整个表,然后相爱指针指向的地址,然后释放内存
函数代码示例:
void LTErase(LTNode* pos) {
assert(pos);
//pos->prev pos pos->next
pos->next->prev = pos->prev;
pos->prev->next = pos->next;
free(pos);
pos = NULL;
}
10.打印
这个其实是用来看每个节点中间的数据的,我们可以通过前驱节点或者尾节点实现正序或逆序打印,这一步也是遍历然后看哨兵节点是否是下一位,是就中断,我这里之举一种例子,另一种只要将next改成prev
函数代码示例:
void LTPrint(LTNode* phead) {
//phead不能为空
assert(phead);
LTNode* pcur = phead->next;
while (pcur != phead)
{
printf("%d->", pcur->data);
pcur = pcur->next;
}
printf("\n");
}11.销毁
这个链表的销毁和点链表不大一样,因为存在哨兵节点,所以我们要分开释放内存
函数代码示例:
void LTDesTroy(LTNode* phead) {
//哨兵位不能为空
assert(phead);
LTNode* pcur = phead->next;
while (pcur != phead)
{
LTNode* next = pcur->next;
free(pcur);
pcur = next;
}
//链表中只有一个哨兵位
free(phead);
phead = NULL;
}最后还是一如既往的测试环节就交给大家了。推荐阅读完http://t.csdnimg.cn/UhXEj
然后再阅读这个