1.背景
Distinct是一种常用的操作,在所有数据库的SQl语言中都是一个非常重要的操作,在Hive中,Distinct去重原理是通过MapReduce来实现的,Distinct操作可以应用于单个列,亦可以应用于多个列。基本原理是将输入的数据集按照指定的列进行分组,在每个分组内部去除重复的值,最后将每个分组的唯一值合并成一个结果集。
最近一位好学的小伙伴在学习的过程中,学习到count distinct 的这块内容的时候,基于单个count distinct 的原理,可以理解的不错,但是对于多字段的count distinct的时候讲的就很难让人理解,今天就来给大家总结一下。
2.Group By
group by的操作适合我们的聚合时distinct息息相关的,所以在我们总结distinct 之前 ,我们不得不先来看一下group by 操作的具体实现原理。
map阶段,将group by后的字段组合作为一个key,如果group by单个字段,那么key就一个。将group by之后要进行的聚合操作字段作为值,如果要进行count,则value是赋1;如要sum另一个字段,那么value就是该字段。
shuffle阶段,按照key的不同分发到不同的reducer。注意此时可能因为key分布不均匀而出现数据倾斜的问题。这个问题是我们处理数据倾斜比较常规的查找原因的方法之一,也是我们解决数据倾斜的处理阶段。
reduce阶段,如果是count将相同key的值累加,如果是其他操作,按需要的聚合操作,得到结果。
实例如下图,对应语句是:
with tmp1 as (
select
'a' as pro,
'1' as city
union all
select
'a',
'1'
union all
select
'a',
'1'
union all
select
'b',
'0'
)
select
pro,
city,
count(*)
from
tmp1
group by
pro,
city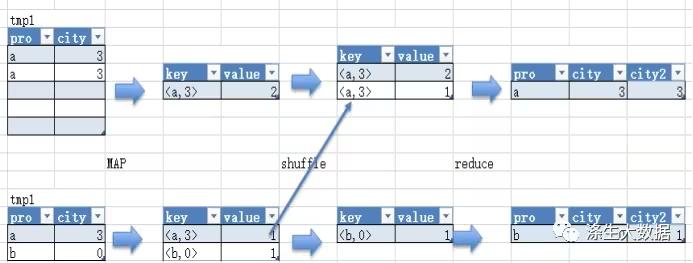
在这个阶段如果出现数据倾斜,我们也可以进行相应的处理,常见的就是把key单独拉出来计算,也可以替换随机数,当然除去替换key为随机数、提前挑出大数量级key值等通用调优方法,适用于group by的特殊方法有以下几种:
set hive.map.aggr=true,就是开启map端的combiner,减少传到reducer的数量级,同时需要设置参数hive.groupby.mapaggr.checkinterval, 规定在 map 端进行聚合操作的条目数目。
设置mapred.reduce.tasks为较大数量,用来降低每个reducer处理的数据量。
set hive.groupby.skewindata=true,该参数也是比较常规的设置,该参数可自动进行负载均衡。生成的查询计划会有两个 MR Job。第一个 MR Job 中,Map 的输出结果集合会随机分布到Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;第二个 MR Job 再根据预处理的数据结果按照 Group ByKey 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce中,最后完成最终的聚合操作。
3.Distinct 单字段
原理
上面我们可以清晰的明白group by的流程,那么接下来我们再来回顾一下distinct 的具体实现,当执行Distinct操作时,Hive会将操作转化为一个MapReduce作业,并按照指定的列进行分组。在Map阶段,每个Mapper会读取输入数据,并将指定的列作为输出的key,然后,通过Shuffle过程将具有相同key的数据发送到同一个Reducer中。
我们可以看出,由于使用了distinct,这就导致在map端的combine无法合并重复数据,所以必须将id作为Key输出,在Reduce阶段再对来自于不同Map Task、相同Key的结果进行消重,计入最终统计值。
对于这种count(distinct)全聚合操作的时候,即使我们设定了reduce task的具体个数,例如set mapred.reduce.tasks=100;hive最终也只会启动一个reducer。这就造成了所有map端传来的数据都在一个tasks中执行,这唯一的Reduce Task需要Shuffle大量的数据,并且进行排序聚合等处理,这使得这个操作成为整个作业的IO和运算瓶颈。
当distinct一个字段时,这里会将group by的字段和distinct的字段组合在一起作为map输出的key,value设置为1,同时将group by的字段定为分区键,这一步非常重要,这样就可以将GroupBy字段作为reduce的key,在reduce阶段,利用mapreduce的排序,输入天然就是按照组合key排好序的。根据分区键将记录分发到reduce端后,按顺序取出组合键中的distinct字段,这时distinct字段也是排好序的。依次遍历distinct字段,每找到一个不同值,计数器就自增1,即可得到count distinct结果。例如下面的SQL语句,过程可以下图示意。
with tmp1 as (
select
'a' as pro,
'1' as city,
'张三' as userid
union all
select
'a',
'1',
'张三'
union all
select
'a',
'1',
'张三'
union all
select
'b',
'0',
'张三'
)
select
pro,
count(distinct userid)
from
tmp1
group by
pro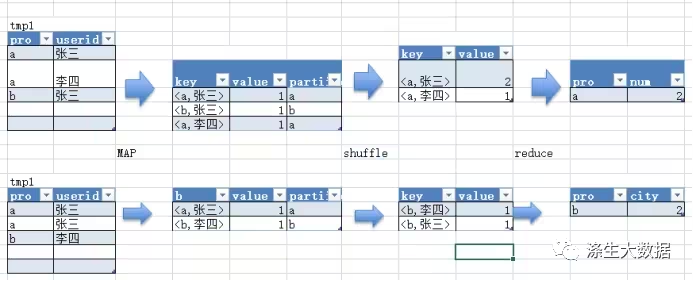
优化
对于单distinct 的优化,我们的课程也提到过很多次,利用Hive对嵌套语句的支持,将原来一个MapReduce作业转换为两个作业,在第一阶段选出全部的非重复的字段id,在第二阶段再对这些已消重的id进行计数;这样在第一阶段我们可以通过增大Reduce的并发数,并发处理Map输出。在第二阶段,由于id已经消重,因此COUNT(*)操作在Map阶段不需要输出原id数据,只输出一个合并后的计数即可。这样即使第二阶段Hive强制指定一个Reduce Task的时候,极少量的Map输出数据也不会使单一的Reduce Task成为瓶颈。
其实在实际运行时,Hive还对这两阶段的作业做了额外的优化。它将第二个MapReduce作业Map中的Count过程移到了第一个作业的Reduce阶段。这样在第一阶Reduce就可以输出计数值,而不是消重的全部id。这一优化大幅地减少了第一个作业的Reduce输出IO以及第二个作业Map的输入数据量。最终在同样的运行环境下优化后的语句可以说是大大提升了执行效率。sql优化模板如下:
SELECT
COUNT(*)
FROM
(
SELECT
DISTINCT id
FROM
TABLE_NAME
WHERE
…
) t;4.Distinct 多字段(mult-distinct)
原理
对于mult-distinct,如果我们仍然按照上面一个distinct字段的方法,即下图这种实现方式,无法根据uid和date分别排序,也就无法通过LastKey去重,仍然需要在reduce阶段在内存中通过Hash去重。
with tmp1 as (
select
'a' as pro,
'1' as city,
'张三' as userid
union all
select
'a',
'1',
'张三'
union all
select
'a',
'1',
'张三'
union all
select
'b',
'0',
'张三'
)
select
pro,
count(distinct userid),
count(distinct city)
from
tmp1
group by
pro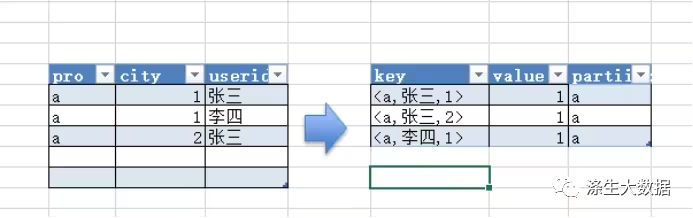
所以hive会使用另外一种处理方式,如果查询中有多个 distinct-expression,同一条record,会生成多条记录进行Shuffle,增大Shuffle量;假设有N个distinct,处置数据有M条,那么这布处置后的输出是N*M条数据(这里产生数据膨胀,也是数据倾斜产生的阶段),所以尽量在MAP端过滤尽可能多的数据生。处理方法是对所有的distinct字段编号,那么相同字段就会分别排序,这时只需要在reduce阶段记录LastKey即可去重。这种实现方式很好的利用了MapReduce的排序,节省了reduce阶段去重的内存消耗,但是缺点是增加了shuffle的数据量。需要注意的是,在生成reduce value时,除第一个distinct字段所在行需要保留value值,其余distinct数据行value字段均可为空。
当然我们有读源码的能力的话,而也可以从hive源码里具体代码可参考ReduceSinkOperator.process方法,代码片段如下图所示。
优化
select
sum(case when d.pv_flag = 1 then 1 else 0 end) as pv,
count(distinct id) as uv,
count(distinct ip) as ip,
sum(distinct otime),
count(distinct cookie)
from
access_dap d
where
log_date = '$YESTERDAY'对于这种多重distinct的操作,我们也会经常遇见,就比如上面的的sql,这个sql我们可以按照三步走的步骤进行优化。
1.预处理,去重汇总,将能去重的重复的数据先去重,并且尽量过滤数据,收敛数据。
2.以空间换时间,我们的磁盘空间是非常容易获取到,我们可以用union all的把数据根据distinct的字段扩充起来,假如有4个distinct,相当于数据扩充4倍,用rownumber=1来达到间接去重的目的,这里的union all只走一个job。
3.嵌套查询,得到最终结果,这里没有一个distinct,全部走的是普通sum,可以在mapper端提前聚合,同样可以调节reduce数,这个会快很多。
----1
create table tmp1 as
select
id,
ip,
cookie,
idis_zero,
sum(case when pv_flag = 1 then 1 else 0 end) as pv,
sum(otime) as onlinetime
from
login_log
group by
id,
ip,
cookie,
idis_zero;
---2
create table tmp2 as
select
type,
type_value,
rownumber(type, type_value) as rn,
pv,
onlinetime
from
(
select
type,
type_value,
pv,
onlinetime
from
(
select
'id' as type,
cast(id as string) as type_value,
pv,
onlinetime
from
tmp1
where
idis_zero = 0
union all
select
'ip' as type,
ip as type_value,
pv,
onlinetime
from
tmp1
union all
select
'cookie' as type,
case when cookie = 'null' then 'acorn_cookie' else cookie end as type_value,
pv,
onlinetime
from
tmp1
) t1 cluster by type,
type_value
) t2;
-----------------------------------------------------------------------------------------------------
select
sum(
case when type = 'ip' then pv else cast(0 as bigint) end
) as pv,
sum(
case when type = 'id'
and rn = 1 then 1 else 0 end
) as uv,
sum(
case when type = 'ip'
and rn = 1 then 1 else 0 end
) as ip,
sum(
case when type = 'ip' then onlinetime else cast('0' as bigint) end
) as onlinetime,
sum(
case when type = 'cookie'
and rn = 1 then 1 else 0 end
) as cookie,
'$STA_TYPE',
'$STA_TYPE'
from
tmp2























![[UI5 常用控件] 01.Text](https://img-blog.csdnimg.cn/direct/7fb80a350d444c8baf4c0df9bfe16376.png)