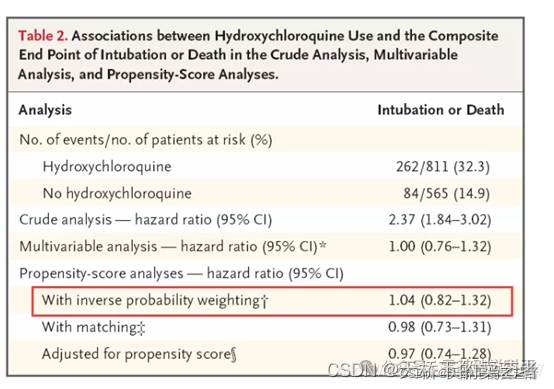
基于 PS (倾向评分)的逆概率加权(IPTW )法首先由Rosenbaum作为一种以模型为基础的直接标准化法提出,属于边际结构模型。简单来说,就是把许多协变量和混杂因素打包成一个概率并进行加权,这样的话,我只用计算它的权重就可以了,方便了许多。那么,如何将多个协变量的影响用一个倾向评分值来表示呢? 即如何估计倾向评分值呢? 根据 Rosen-baum 和 Rubin 的定义:倾向评分值为在给定一组协变量(X i )条件下,研究对象 i(i =1,2,…N)被分配到某处理组或接受某暴露因素(Z i =1)的条件概率。
R语言绘制逆概率加权后的基线表
代码:
library(tableone)
library(survey)
# 这是一个关于早产低体重儿的数据(公众号回复:早产数据,可以获得该数据),
# 低于2500g被认为是低体重儿。数据解释如下:low 是否是小于2500g早产低体重儿,age 母亲的年龄,
# lwt 末次月经体重,race 种族,smoke 孕期抽烟,ptl 早产史(计数),ht 有高血压病史,ui 子宫过敏
# ,ftv 早孕时看医生的次数
bc<-read.csv("E:/r/test/zaochan.csv",sep=',',header=TRUE)
bc <- na.omit(bc)
#先把分类变量转成因子
bc <- na.omit(bc)
bc$race<-ifelse(bc$race=="black",1,ifelse(bc$race=="white",2,3))
bc$smoke<-ifelse(bc$smoke=="nonsmoker",0,1)
bc$low<-factor(bc$low)
bc$race<-factor(bc$race)
bc$ht<-factor(bc$ht)
bc$ui<-factor(bc$ui)
#假设我们研究的是有无高血压(ht)对生出低体重儿(low)的影响,我们先绘制一个还没有加权的患者基线表
dput(names(bc))##输出变量名
allVars <-c("age", "lwt", "race", "smoke", "ptl", "ht", "ui",
"ftv", "bwt")###所有变量名
fvars<-c("race", "smoke","ht","ui")#分类变量定义为fvars
tab2 <- CreateTableOne(vars = allVars, strata = "low" , data = bc, factorVars=fvars,
addOverall = TRUE )###绘制基线表
print(tab2)#输出表格
#我们先建立回归方程生成预测值
pr<- glm(ht ~age + lwt + race + smoke + ptl + ui + ftv, data=bc,
family=binomial(link = "logit"))
pr1<-predict(pr,type = "response")
summary(bc$ht)
#分别生成两种权重
#Robins等给出的加权系数(形)计算方法
w<- (bc$ht==1) * (1/pr1) + (bc$ht==0) * (1)/(1-pr1)
#Heman等人对计算方法,计算稳定权重要先生成概率(发生高血压的概率)
pt<-12/(177+12)
w1 <- (bc$ht==1) * (pt/pr1) + (bc$ht==0) * (1-pt)/(1-pr1)
#绘制加权后的基线表格 #Robins
bcSvy1<- svydesign(ids = ~ id, strata = ~ low, weights = ~ w,
nest = TRUE, data = bc)
Svytab1<- svyCreateTableOne(vars = c( "age", "lwt", "race", "smoke", "ptl","ui",
"ftv", "bwt"),
strata = "low", data =bcSvy1 ,
factorVars = c("race", "smoke","ht","ui"))
Svytab1
#绘制加权后的基线表格 #Heman
bcSvy2<- svydesign(ids = ~ id, strata = ~ low, weights = ~ w1,
nest = TRUE, data = bc)
Svytab2<- svyCreateTableOne(vars = c( "age", "lwt", "race", "smoke", "ptl", "ui",
"ftv", "bwt"),
strata = "low", data =bcSvy2 ,
factorVars = c("race", "smoke","ht","ui"))
Svytab2