HBase节点故障的容错方案
本文主要探讨hbase集群的高可用容错方案和容错能力的探讨。涉及Master和RS相关组件,在出现单机故障时相关的容错方案。
更多关于分布式系统的架构思考请参考文档关于常见分布式组件高可用设计原理的理解和思考
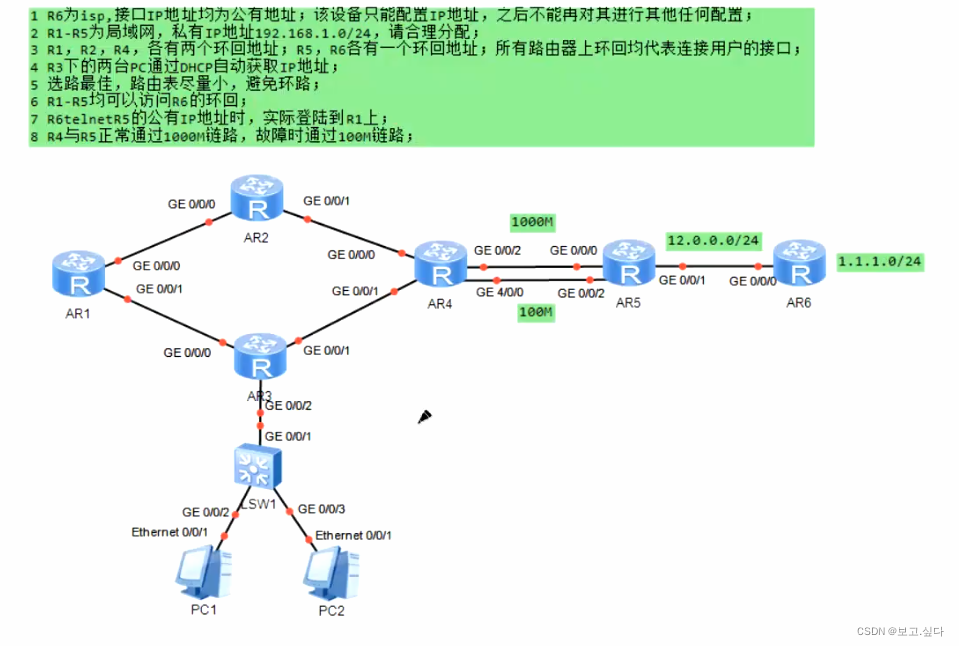
1. Master高可用
1.1 选主和HA切换逻辑
Master的HA机制主要依靠zk完成。整体的逻辑跟HDFS的NN逻辑整体上一致,也略有差别,可以参考 HDFS节点故障的容错方案
相同点
1, Master使用zk的临时锁节点进行选主
2,其他节点的watch机制跟hdfs的逻辑也一致
不同点
1, Master没有另外涉及zkfc辅助选主,而是Master自己完成了相关的逻辑
2,Master集群没有涉及fencing逻辑。
2. RS高可用
RS节点是具体的数据存储节点,HBase通常依赖hdfs进行数据存储,包括wal日志等基础原数据存储等。由于hdfs本身能够提供高可用,并且能够提供远程存储能力,因此1个RS写入的数据(包括wal日志)等能够在另外一个RS中进行数据回放。
由于HBase本身没有直接跟磁盘进行交互,因此底层的磁盘io等信息被hdfs隔离,因此hdfs的读写、存储能力直接影响HBase的性能。
2.1 感知RS节点异常
1,RS在zk中注册临时路径(/hbase/rs),如果RS节点异常,在ttl时间(默认 3min)后临时节点会被zk删除。

2, Master通过watch机制监听rs的相关路径,RS在zk中注册的临时路径过期后被删除,zk会将相关事件通知Master
2.2 异常DN上的数据处理
Master感知到RS异常后,会将RS上的Region信息迁移到其他的RS,并将wal日志在对应的RS节点进行回放,从而确保数据不丢失。
4. 疑问和思考
暂无
5. 参考文档
暂无