什么是XPath?
在深入following-sibling选择器之前,先简单了解一下XPath。XPath是一种在XML文档中查找信息的语言。它同样适用于HTML文档,因为HTML是XML的一种形式。XPath使用路径表达式在XML文档中进行导航。在网络爬虫框架Scrapy中,XPath是一种常用的网页元素定位方法。
following-sibling选择器简介
在XPath中,following-sibling选择器用于选择当前节点之后的所有同级节点。这个选择器常用于那些具有相似结构但不容易直接定位的元素,尤其是在处理列表、表格等结构时特别有用。
使用方法
基本语法
xpath('//标签名[条件]/following-sibling::标签名')
这里,following-sibling::后面跟着的是你想要选择的同级元素的标签名。
实例解析
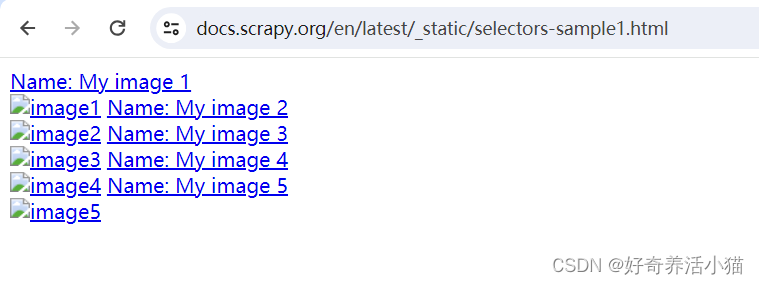
假设我们有以下HTML结构:
<div>
<h2>标题1</h2>
<p>段落1</p>
<h2>标题2</h2>
<p>段落2</p>
</div>
如果我们想要选择“标题1”后面的段落,我们可以使用以下XPath表达式:
xpath('//h2[text()="标题1"]/following-sibling::p[1]')
这将选择第一个<h2>标签之后的第一个<p>标签。
注意事项
- 选择范围:
following-sibling选择器会选取所有紧随当前节点的同级节点,如果需要选择特定的一个,记得加上索引。 - 使用场景:这个选择器在处理具有复杂关系或不规则结构的HTML时特别有用。
- 性能考虑:过度使用或不当使用
following-sibling可能会影响爬虫的性能,尤其是在处理大型文档时。
结语
掌握following-sibling选择器可以大大提高在Scrapy中处理HTML文档的效率和准确性。通过本文的介绍和示例,希望读者能够更好地理解和运用这一强大的工具。