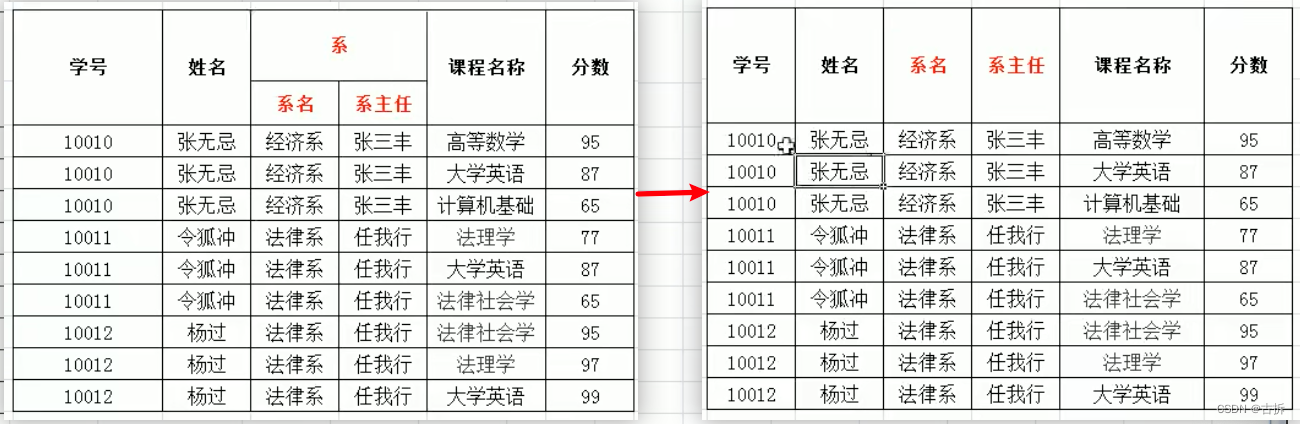
好的,让我们以学校数据库中的一个表为例来说明第一范式(1NF)、第二范式(2NF)和第三范式(3NF)的概念。
什么是数据库三范式
数据库的范式(Normalization)是一组关于数据库设计的规则,目的是减少数据冗余和改善数据完整性。数据库设计通常遵循三个基本的范式,它们分别是:
第一范式(1NF):
- 原子性:表的每一列都是不可分割的基本数据项,即表中的所有字段值都是不可再分的原子值。
- 唯一性:表的每一行都是唯一的,可以通过一个主键(Primary Key)来区分。
第二范式(2NF):
- 在1NF的基础上,消除非主属性对于码的部分函数依赖。
- 部分函数依赖是指表中的非主属性只依赖于候选键的一部分,而不是整个候选键。
- 为了达到2NF,通常需要把表分解成两个或多个表,以确保每个表中的非主属性只依赖于该表的主键。
第三范式(3NF):
- 在2NF的基础上,消除非主属性对于码的传递函数依赖。
- 传递函数依赖是指表中的非主属性依赖于另外一个非主属性,这个非主属性依赖于候选键。
- 达到3NF需要进一步分解表,以确保每个表中的非主属性只依赖于该表的主键,并且没有非主属性依赖于其他非主属性。
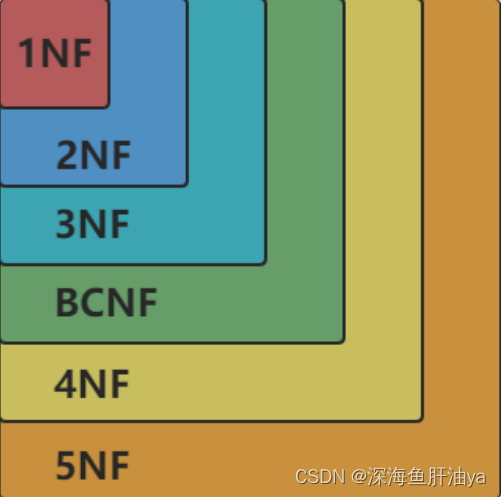
这些范式的目标是减少数据冗余(即重复数据),避免更新异常,增强数据的一致性。通常,在实际应用中,设计到第三范式就足够了,但有时候也可能会用到更高级的范式,如BCNF(Boyce-Codd Normal Form)。设计数据库时,需要在规范化和性能之间做出权衡,因为过度规范化可能会导致查询性能下降。
一个例子讲清三范式
从一个未优化的例子逐步拆表
原始表格(未规范化):
假设我们有一个记录学生信息和他们选修课程成绩的表格,如下所示:
| 学生ID | 学生姓名 | 选修课程 | 成绩 | 导师姓名 | 导师电话 |
|---|---|---|---|---|---|
| 001 | 张三 | 数学, 物理 | 85, 90 | 李教授 | 1234567890 |
| 002 | 李四 | 化学 | 78 | 王教授 | 0987654321 |
这个表有多个问题:选修课程和成绩字段包含了多个值,违反了1NF;导师姓名和电话是依赖于学生ID的非主属性,违反了2NF;导师电话依赖于导师姓名,而不是学生ID,违反了3NF。
第一范式(1NF):
要满足1NF,表中的每个字段都必须只有单一的(不可分割的)值,不可以有重复的列。
| 学生ID | 学生姓名 | 选修课程 | 成绩 | 导师姓名 | 导师电话 |
|---|---|---|---|---|---|
| 001 | 张三 | 数学 | 85 | 李教授 | 1234567890 |
| 001 | 张三 | 物理 | 90 | 李教授 | 1234567890 |
| 002 | 李四 | 化学 | 78 | 王教授 | 0987654321 |
现在每个字段都只包含单一值,满足了1NF。
第二范式(2NF):
为了达到2NF,我们需要确保表中的所有非主属性完全依赖于主键(而不是部分依赖于复合主键的一部分)。首先,我们确定主键是学生ID和选修课程的组合。然后,我们将导师信息移到一个单独的表中,因为导师信息依赖于学生ID而不是选修课程。
学生课程表:
| 学生ID | 选修课程 | 成绩 |
|---|---|---|
| 001 | 数学 | 85 |
| 001 | 物理 | 90 |
| 002 | 化学 | 78 |
导师信息表:
| 学生ID | 导师姓名 | 导师电话 |
|---|---|---|
| 001 | 李教授 | 1234567890 |
| 002 | 王教授 | 0987654321 |
现在,学生课程表满足2NF,因为所有非主属性(成绩)都完全依赖于整个主键。
第三范式(3NF):
为了满足3NF,我们需要确保表中的所有非主属性只依赖于主键,不存在传递依赖。我们发现,导师电话依赖于导师姓名,而不是学生ID。为了消除传递依赖,我们将导师信息再次分离成独立的表。
学生课程表(保持不变):
| 学生ID | 选修课程 | 成绩 |
|---|---|---|
| 001 | 数学 | 85 |
| 001 | 物理 | 90 |
| 002 | 化学 | 78 |
学生导师关系表:
| 学生ID | 导师姓名 |
|---|---|
| 001 | 李教授 |
| 002 | 王教授 |
导师信息表:
| 导师姓名 | 导师电话 |
|---|---|
| 李教授 | 1234567890 |
| 王教授 | 0987654321 |
现在,每个表都满足3NF,因为所有的非主属性都直接依赖于主键,不存在非主属性对主键之外的其他非主属性的依赖。通过这些步骤,我们实现了数据的规范化,减少了数据冗余,并提高了数据的完整性。