将通过 NLP 中最常见的文本分类任务来学习如何在自己的数据集上利用迁移学习(transfer learning)微调一个预训练的 Transformer 模型—— DistilBERT。DistilBERT 是 BERT 的一个衍生版本,它的优点在它的性能与 BERT 相当,但是体积更小、更高效。所以我们可以在几分钟内训练一个文本分类器。
如果你想尝试一下 BERT,那么只需改一下模型的 checkpoint 就可以了。通常,checkpoint 指的是要加载到给定 Transformer 架构中的一系列模型权重。
数据集
这里我们将使用英文推文情感数据集,这个数据集中包含了:anger,disgust,fear,joy,sadness 和 surprise 六种情感类别。
http://dx.doi.org/10.18653/v1/D18-1404
所以我们的任务是给定一段推文,训练一个可以将其分类成这六种基本情感的其中之一的模型。
现在我们来下载数据集。

为了更好地分析数据,我们可以将 Dataset 对象转成 Pandas DataFrame,然后就可以利用各种高级 API 可视化数据集了。但是这种转换不会改变数据集的底层存储方式(这里是 Apache Arrow)。
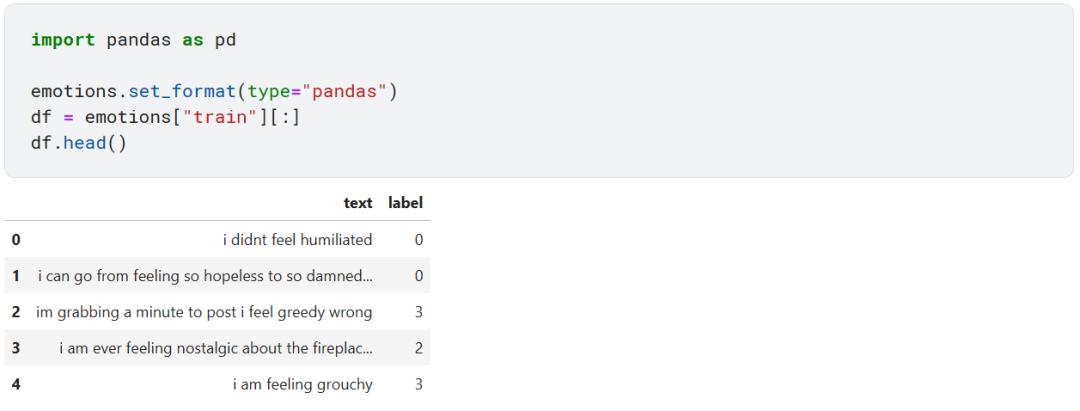
从上面可以看到 text 列中的推文在 label 列都有一个整数对应,显然这个整数和六种情绪是一一对应的。那么怎么去将整数映射成文本标签呢?
如果我们观察一下原始数据集中的每列的数据类型。

我们发现 text 列就是普通的 string 类型,label 列是 ClassLabel 类型。ClassLabel 中包含了 names 属性,我们可以利用 ClassLabel 附带的 int2str 方法来将整数映射到文本标签。
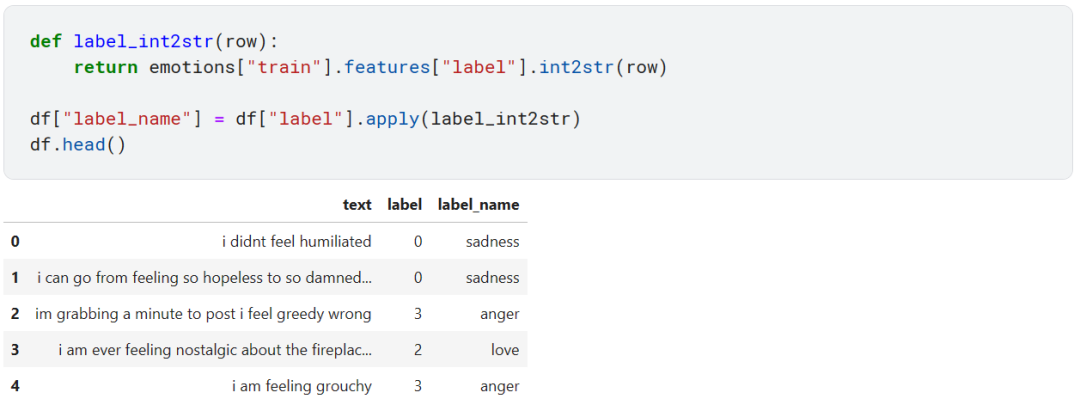
现在看起来就清楚多了。
处理任何分类任务之前,都要看一下样本的类别分布是否均衡,不均衡类别分布的数据集在训练损失和评估指标方面可能需要与平衡数据集做不同的处理。
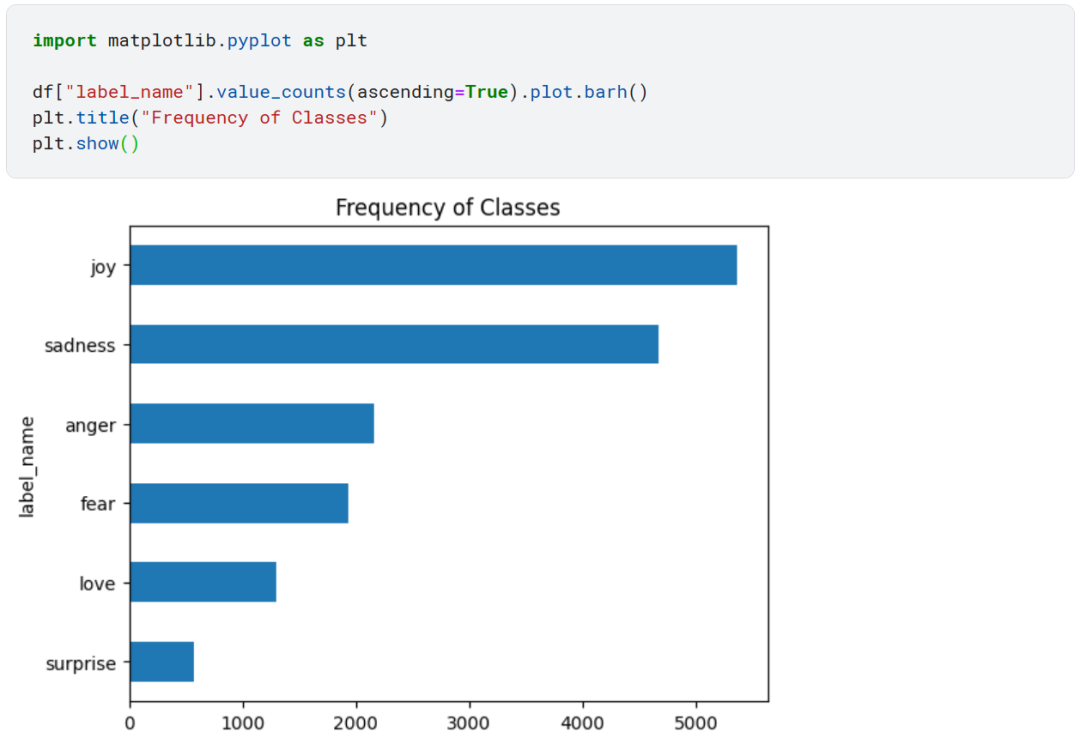
类别分布严重不均衡!joy 和 sadness 类样本数量最多,而 love 和 surprise 类的样本数量几乎要少 5-10 倍。
有好几种方法可以处理类别不均衡问题:
对样本数量少的类别进行随机上采样。
对样本数量少的类别进行随机下采样。
对于样本数量不足的类别收集更多样本。
限于篇幅,我们这里不做任何处理。
最后一件事,也是最重要的。无论是哪个 Transformer 模型,它都有上下文长度限制(maximum context size)。GPT-4 Turbo 的上下文长度已经达到了 128k 个 token!不过 DistilBERT 只有 512。
token 指的是不能再被拆分的文本原子,我们将在后面学习,这里就简单理解为单词就好。

从上图可以看到最长的推文长度也没超过 512,大多数长度在 15 左右。完全符合 DistilBERT 的要求。比模型最长上下文限制还要长的文本需要被截断,如果截断的文本包含关键信息,这可能会导致性能损失,不过我们这里没有这个问题。
分析完数据集之后,别忘了将数据集格式从 DataFrame 转回来。

Token
像 DistilBERT 这样的 Transformer 模型无法接受原始的字符串作为输入,我们必须将文本拆分成一个个 token(这一过程称为 tokenized),然后编码成数值向量表示。
将文本拆分成模型可用的原子单位的步骤称为 tokenization。对于英文来说有 character tokenization 和 word tokenization。我们这里简单地见识一下,不深入探讨。
以英文为例,对于 character tokenization 来说。
将原始文本拆分成一个个字符,也就是 26 个大小写字母加标点符号。
建立一个字符到唯一整数映射的映射关系表。
将字符映射到唯一的整数表示 input_ids。
将 input_ids 转成 2D 的 one-hot encoding 向量。

character-level tokenization 忽略了文本的结构,将字符串看成是一连串的字符流,尽管这种方法可以处理拼写错误和罕见的单词。其主要缺点是需要从数据中学习单词等语言结构。这需要大量的计算、内存和数据。因此,这种方法在实践中很少使用。
word tokenization 就是按照单词维度来拆分文本。

其余步骤和 character tokenization 都一样。不过 character tokenization 的词汇表最多只有几百个(对英文来说,26 个大小写字母和标点符号)。但是 word tokenziation 形成的词汇表可能有数千甚至数万之多,尤其是英文这种每个单词还有不同的形式变化的语言。
subword tokenization 可以看成是 character tokenization 和 word tokenization 的折中方法。
NLP 中有不少算法可以实现 subword tokenization,BERT 和 DistilBERT 都是采用 WordPiece 算法。
每个模型都有自己 tokenization 方法,所以要从对应模型的 checkpoint 下载预训练过的 tokenizer。
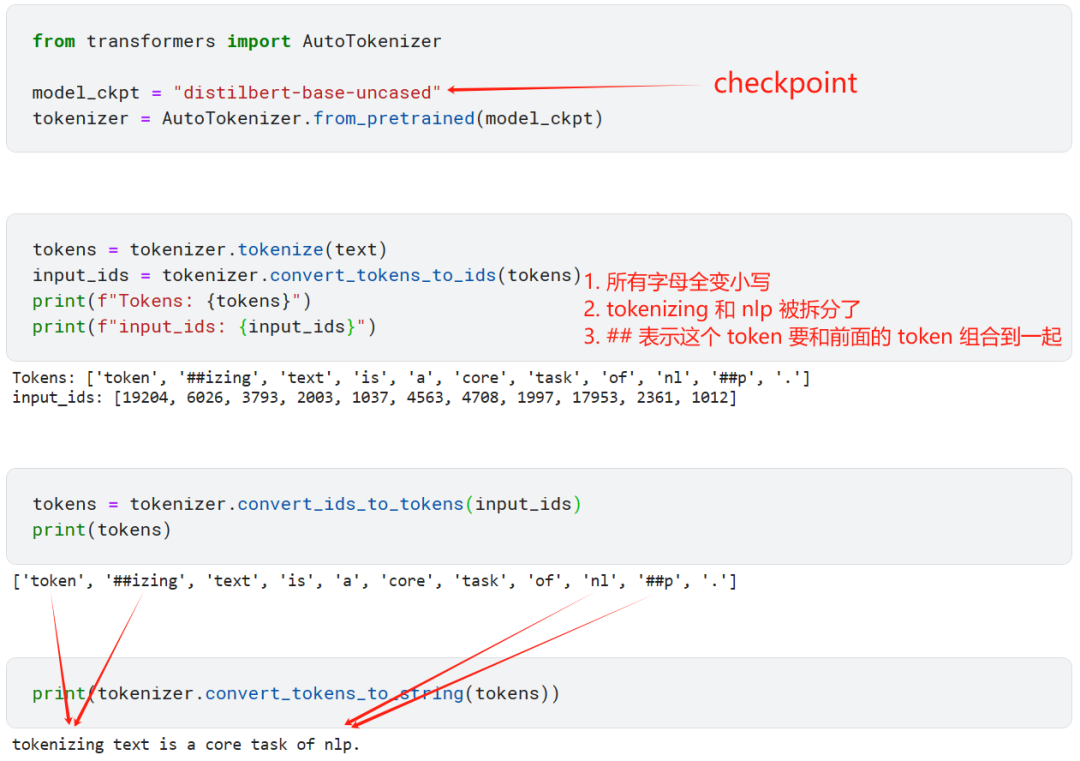
我们还能获取像最大上下文长度等基本的 tokenizer 信息。

最后一个看起来有点懵,其实在实际工作中我们一般这样做。

首先 input_ids 字段还是 token 对应的整数,但是首尾增加了标识序列开头和结尾的特殊 token:[CLS] 和 [SEP]。
现在再来看看 attention_mask 字段。当批量处理文本时,每个文本的长度都不一样。
如果最长的文本超过模型的最长上下文限制,则直接截断多余的部分。
在其余短文本后面附加 padding token,使它们的长度都一致。

attention mask 为 0 的部分表示对应的 token 是为了扩展长度而引入的 padding token,模型无需理会。
现在对整个数据集进行 tokenization。
模型架构
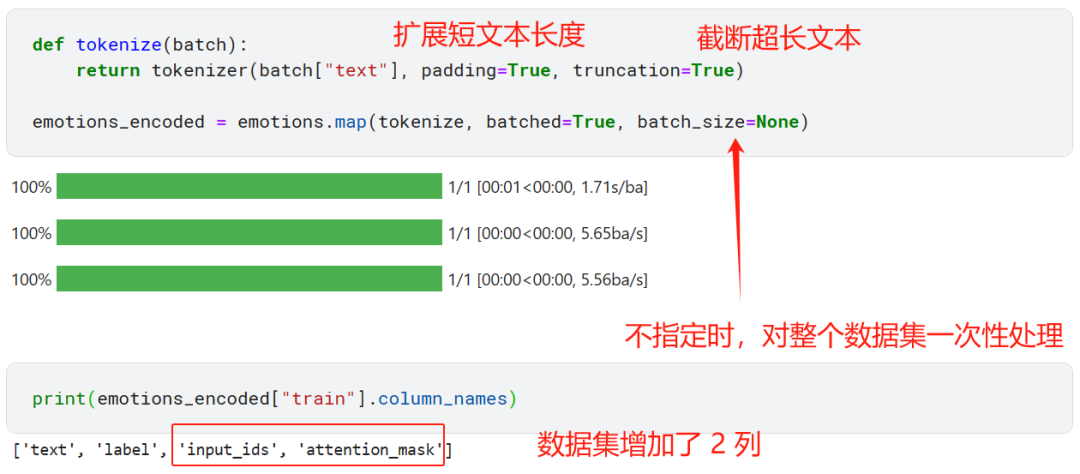
像 DistilBERT 这样的模型的预训练目标是预测文本序列中的 mask 词,所以我们并不能直接拿来做文本分类任务。像 DistilBERT 这种 encoder-based Transformer 模型架构通常由一个预训练的 body 和对应分类任务的 head 组成。
首先我们将文本进行 tokenization 处理,形成称为 token encodings 的 one-hot 向量。tokenizer 词汇表的大小决定了 token encodings 的维度,通常在 20k-30k。
然后,token encodings 被转成更低维度的 token embeddings 向量,比如 768 维,在 embedding 空间中,意思相近的 token 的 embedding 向量表示的距离也会更相近。
然后 token embeddings 经过一系列的 encoder 层,最终每个 token 都生成了一个 hidden state。
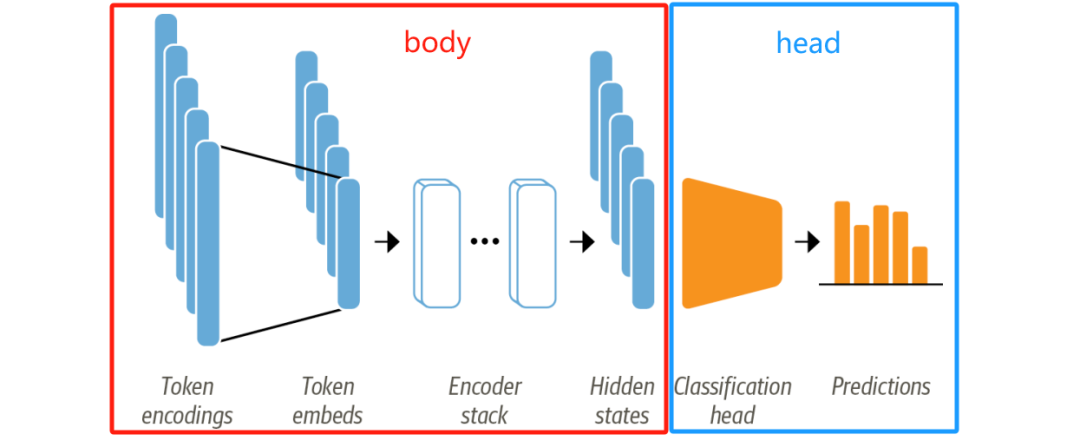
现在我们有两种选择:
将 Transformer 模型视为特征抽取模型,我们不改变原模型的权重,仅仅将 hidden state 作为每个文本的特征,然后训练一个分类模型,比如逻辑回归。
所以我们需要在训练时冻结 body 部分的权重,仅更新 head 的权重。
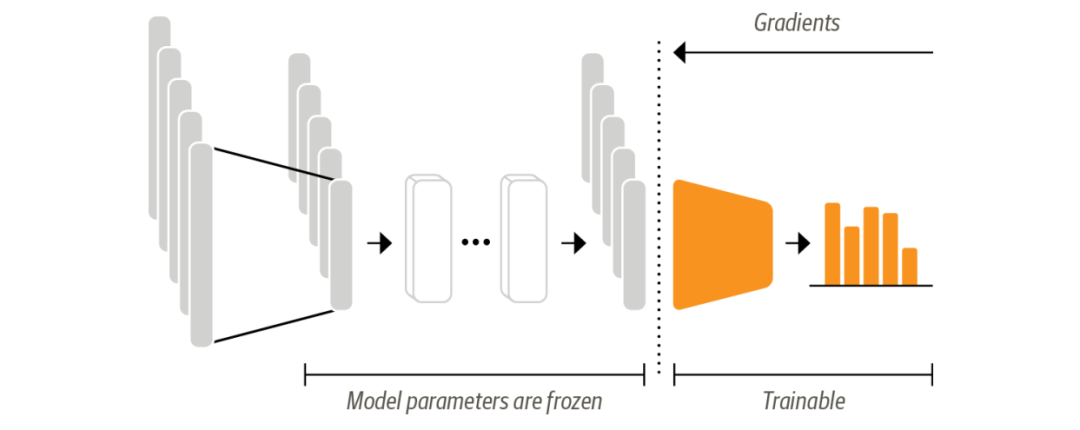
这样做的好处是即使 GPU 不可用时我们也可以快速训练一个小模型。
让我们先下载模型。
这个模型就会将 token encoding 转成 embedding,再经过若干 encoder 层输出 hidden state。

在分类任务中,习惯用 [CLS] token 对应的 hidden state 作为句子特征,所以我们先写一个特征抽取函数。

然后抽取我们这个数据集的特征。
然后我们可以训练一个逻辑回归模型去预测推文情绪类别。

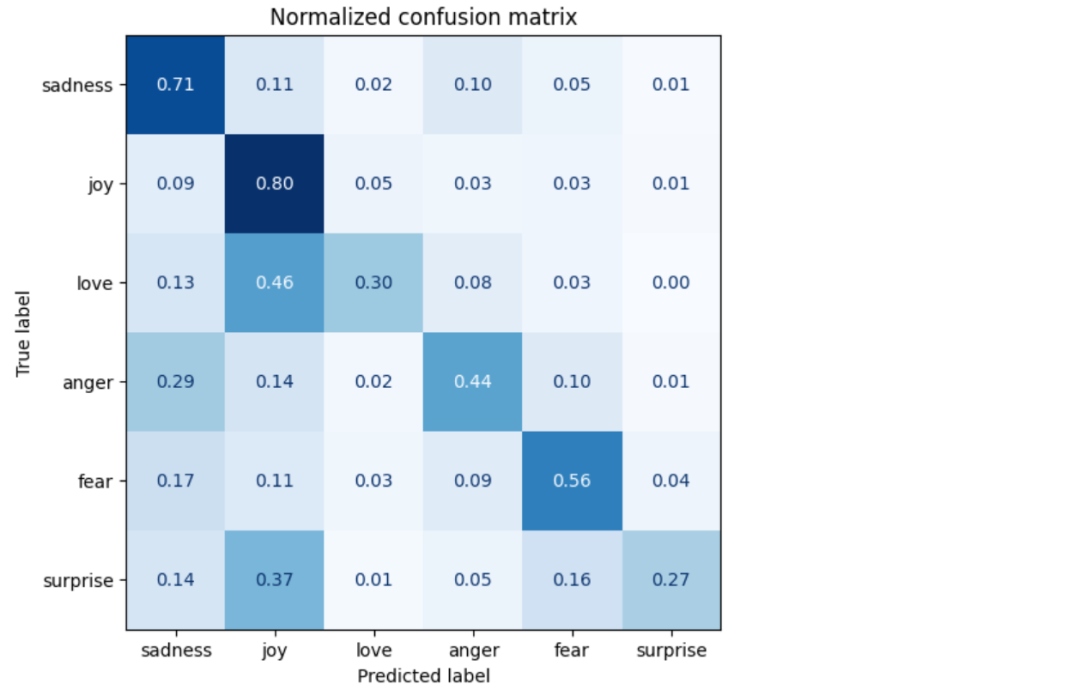
从混淆矩阵可以看到 anger 和 fear 通常会被误分类成 sadness,love 和 surprise 也总会被误分类成 joy。
微调 Transformer 模型
此时我们不再将预训练的 Transformer 模型当作特征抽取器了,我们也不会将 hidden state 作为固定的特征了,我们会从头训练整个整个 Transformer 模型,也就是会更新预训练模型的权重。
如下图所示,此时 head 部分要可导了,不能使用逻辑回归这样的机器学习算法了,我们可以使用神经网络。
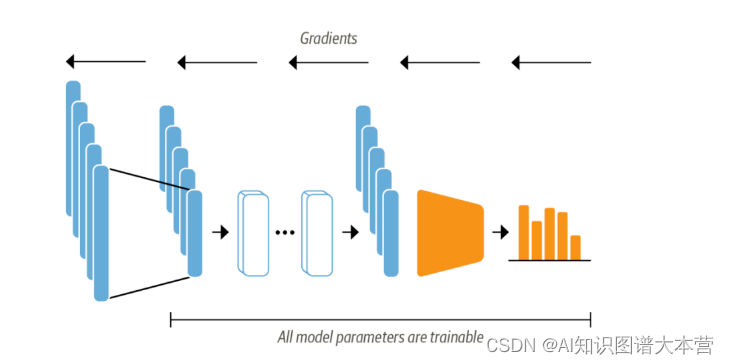 首先我们加载预训练模型,从下方的警告信息可以看到此时模型一部分参数是随机初始化的。
首先我们加载预训练模型,从下方的警告信息可以看到此时模型一部分参数是随机初始化的。
接下来再定义 F1-score 和准确率作为微调模型时的性能衡量指标。

然后就是定义一些训练模型时的超参数设定。
全部就绪后,就可以训练模型了,我们这里训练 2 个 epoch。
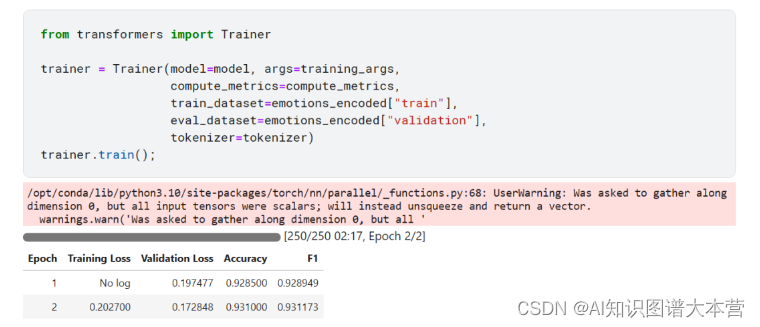 可以看到仅仅训练了 2 个 epoch,模型在验证集上的 F1-score 就达到了 93%。
可以看到仅仅训练了 2 个 epoch,模型在验证集上的 F1-score 就达到了 93%。
我们再看一下模型在验证集上的混淆矩阵。


可以看到此时的混淆矩阵已经十分接近对角矩阵了,比之前的好多了。
最后我们看一下微调过的模型是如何预测推文情绪的。
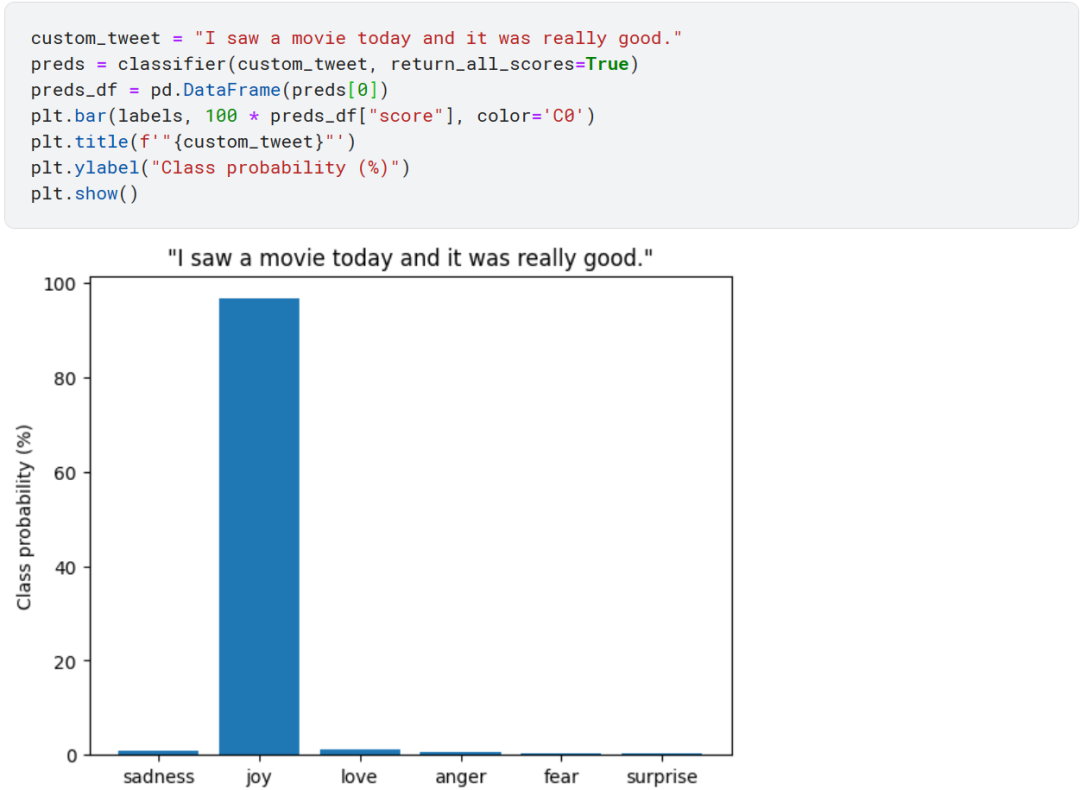




























![[论文阅读]DeepFusion](https://img-blog.csdnimg.cn/direct/2b6ad8a8d2fd479eb49521c3d44a102b.png)

