Hadoop集群配置及测试
NameNode与SecondaryNameNode最好不在同一服务器
ResourceManager较为消耗资源,因而和NameNode与SecondaryNameNode最好不在同一服务器。
配置文件
| hadoop102 | hadoop103 | hadoop104 | |
|---|---|---|---|
| HDFS | NameNodeDataNode | DataNode | SecondaryNameNodeDataNode |
| YARN | NodeManager | ResourceManagerNodeManager | NodeManager |
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
(1)默认配置文件:
| 要获取的默认文件 | 文件存放在Hadoop的jar包中的位置 |
|---|---|
| [core-default.xml] | hadoop-common-3.1.3.jar/core-default.xml |
| [hdfs-default.xml] | hadoop-hdfs-3.1.3.jar/hdfs-default.xml |
| [yarn-default.xml] | hadoop-yarn-common-3.1.3.jar/yarn-default.xml |
| [mapred-default.xml] | hadoop-mapreduce-client-core-3.1.3.jar/mapred-default.xml |
(2)自定义配置文件:
core-site.xml**、hdfs-site.xml、yarn-site.xml、****mapred-site.xml**四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
(1)核心配置文件
配置core-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/yume/software/hadoop-3.3.4/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>atguigu</value>
</property>
</configuration>
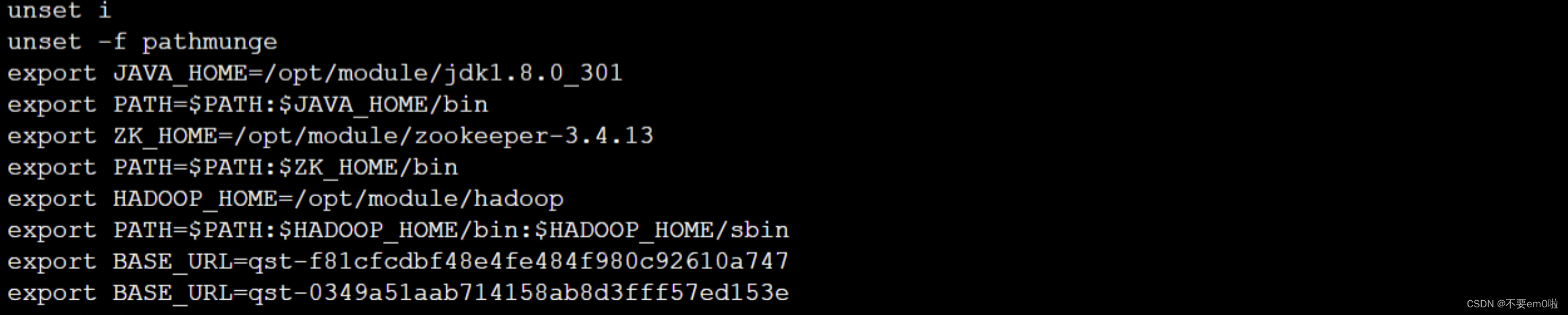
nameNode端口号也可以为9000 9820
(2)HDFS配置文件
配置hdfs-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
(3)YARN配置文件
配置yarn-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
注意:在hadoop3.2.0以上不需要配置环境变量
(4)MapReduce配置文件
配置mapred-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置workers
进入hadoop(文件路径)/etc/hadoop/workers,并对起进行修改,将其默认的localhost替换成hadoop102至104.并修改每一个服务器上的workers
启动集群
(1)如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)
hdfs namenode -format
我们可以在新创建的data文件夹一直往下寻找到一个VERSION的文件,这之中包含着namespace等数据。

进行集群
sbin/start-dfs.sh
我们可以使用jps来查看当前的启动项。jps是jdk提供的一个查看当前java进程的小工具。
我们当前可以打开浏览器,进入hadoop102:9870.及我们在之前所配置的对外端口。
启动正确服务器的yarn
及启动我们在配置文件中所配置yarn(resourceManager)的服务器。
sbin/start-yarn.sh
如果jps没有resourceManager可以尝试以下
cd etc/hadoop/
vim yarn-env.sh
添加:
export YARN_RESOURCEMANAGER_OPTS="--add-opens java.base/java.lang=ALL-UNNAMED"
export YARN_NODEMANAGER_OPTS="--add-opens java.base/java.lang=ALL-UNNAMED"
yarn所展示的web链接,进入hadoop103:8088
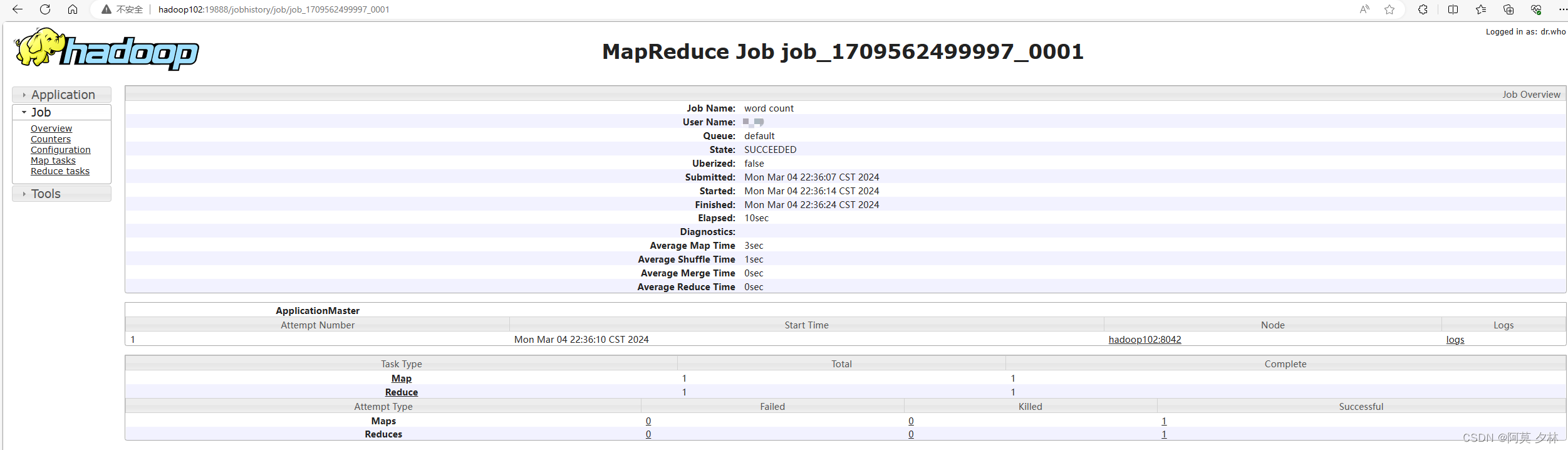
集群基本测试
上传
创建集群文件夹
hadoop fs -mkdir /wcinput
将本地word.txt上传到/wcinput文件夹
hadoop fs -put $HADOOP_HOME/test/word.txt /wcinput
然后我们可以在hadoop102:9870中上方的utilities中的Browse the file system来查询进程,如果你使用的是jdk11以上的版本就会出现Failed to retrieve data from /webhdfs/v1/?op=LISTSTATUS: Server Error的错误。
TIP
hadoop fs -mkdir -p /your dir :这个命令是帮助你在Hadoop的FS上面创建目录
hadoop fs -rm -r -skipTrash /your file path: 这个命令是帮助你删除文件和目录
hadoop fs -ls /your path : 这个命令是帮助你查看对应目录下的文件和文件夹
hadoop fs -get /your path /file name : 这个命令帮助你下载文件到本地机器上
hadoop fs -put /file name /your targer path: 这个命令帮助你上传文件到指定的目录
hadoop jar xxx.jar /input /output : 这个命令帮你提交hadoop作业到集群中去运行