概览
1.Redis核心数据存储结构
2.Redis底层String编码int&embstr&raw
3.Redis底层压缩列表&跳表&哈希表
4.Redis底层Zset实现压缩列表和跳表如何选择
5.基于Redis实现微博&抢红包&12306核心业务
辅助学习:Redis 教程 | 菜鸟教程
1.Redis为什么性能高?
单线程,没有切换线程的时间耗费
基于内存、多路复用
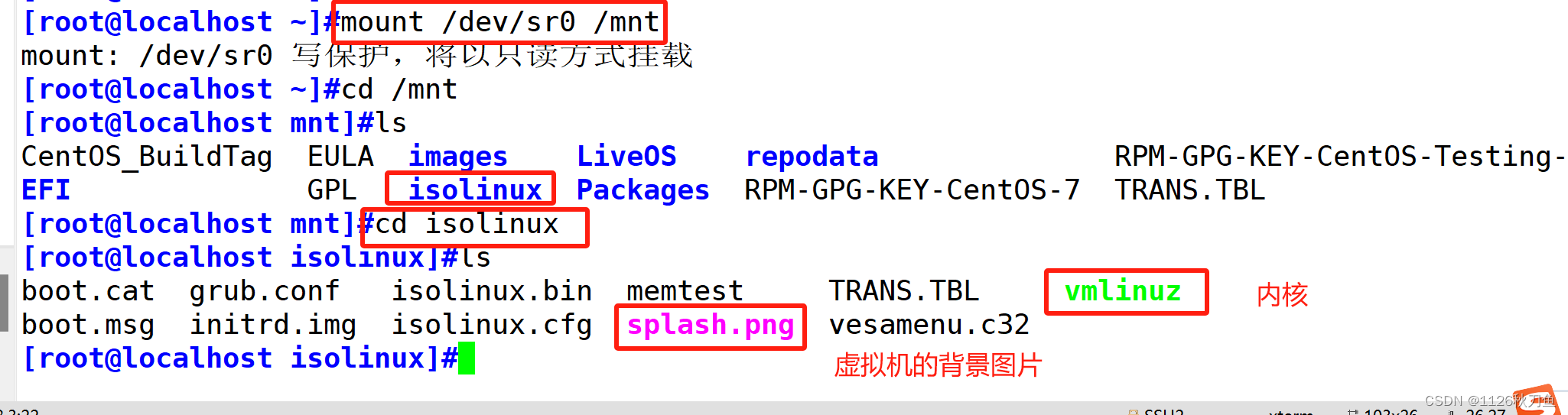
一破机制?涉及其内核级别的设置,多线程的设置,然后它性能就高。
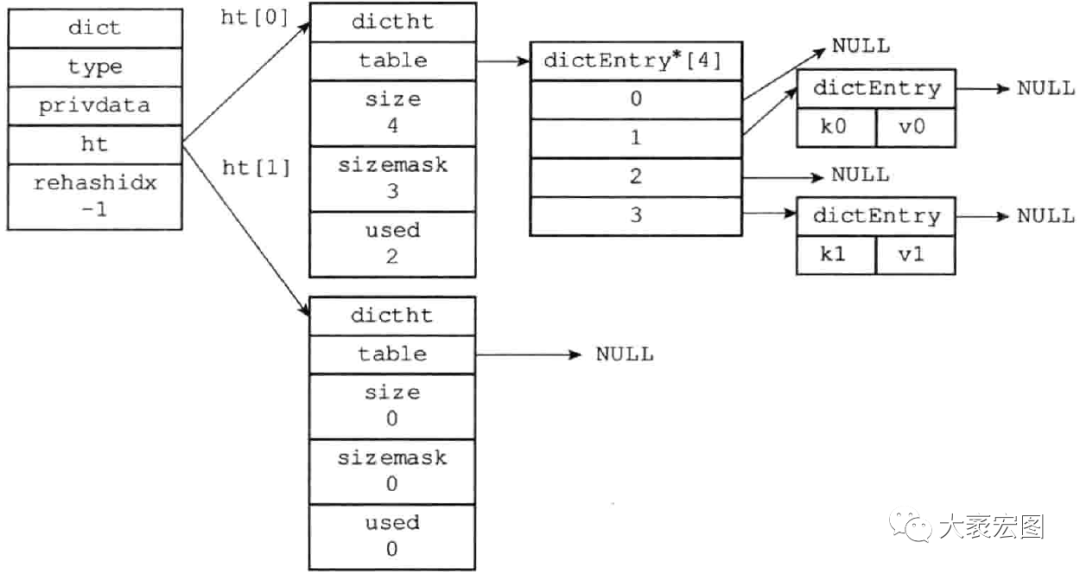
Redis的性能高体现在命令执行时,采用全局Hash表,其存储的时间复杂度O(1),
当发生哈希冲突时,采用rehash机制,使冲突的概率极小。
2.Redis核心数据结构
2.1.1字符串类型

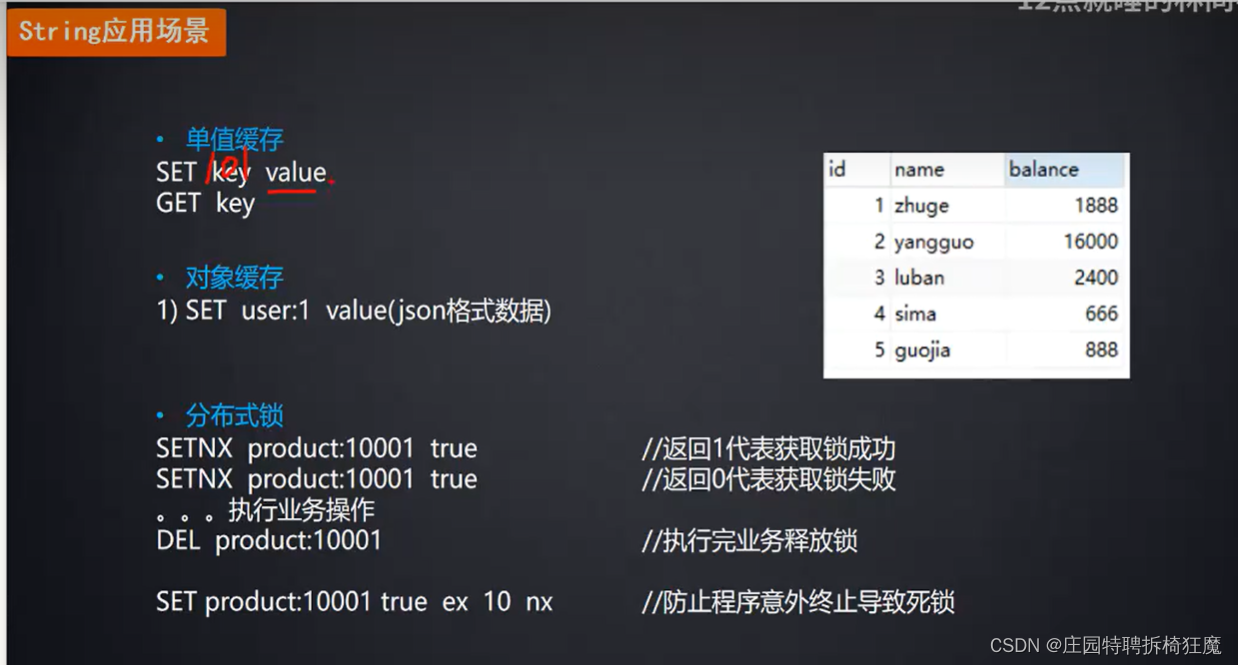
特别的:SETNX(set if not exists)设置值时,若key值存在时,不做操作

2.1.2字符串类型应用场景
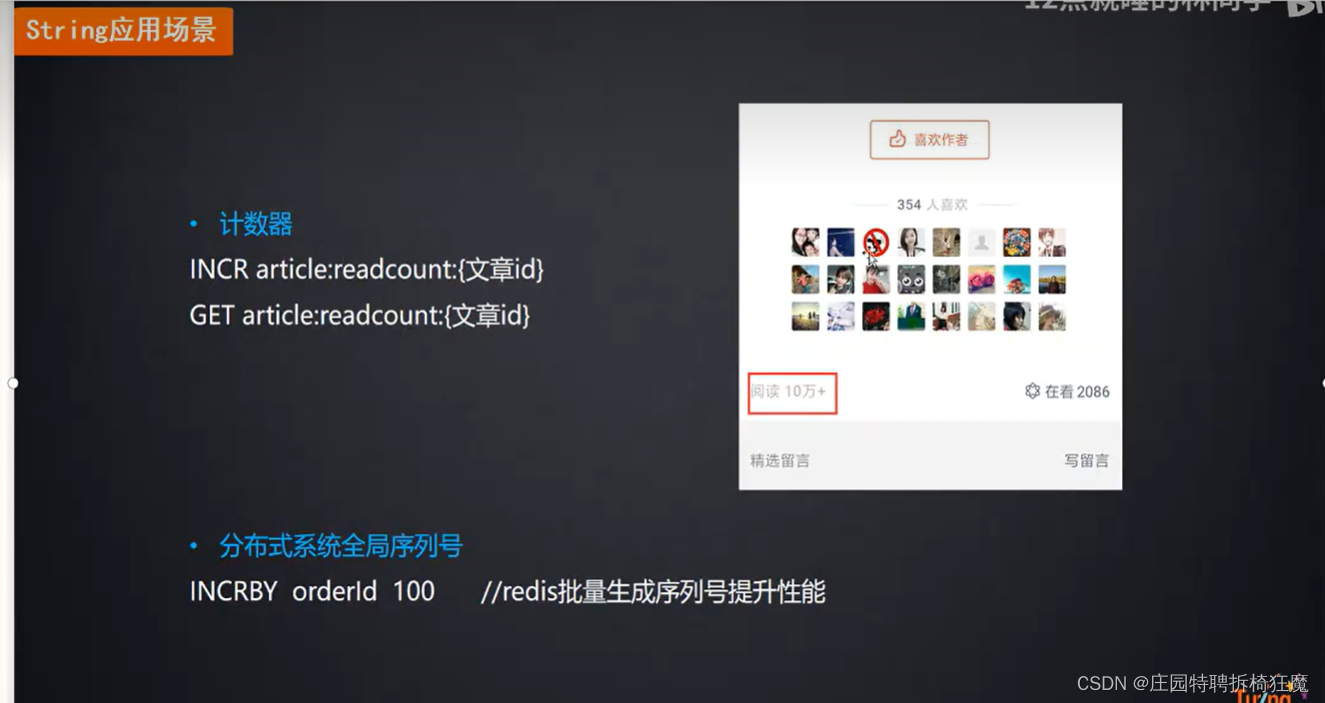
业务场景:文章阅读量
每当一个人阅读,就有一个+1操作。
在redis可以通过incr实现自增操作。
- 一些分库分表设置的数据库,就不能用数据库自带的自增操作生成ID了,可以用redis实现自增操作。
- 但是redis使用的是内存资源,比较宝贵,大数据量的话,不建议。可以采用一个批量自增的操作。取100个,存到java web里暂存,虽然java web程序挂了,会丢失,但是不影响,因为自增上限很大,不会不够用。
- redis批量自增怎么做:INCRBY orderId 100
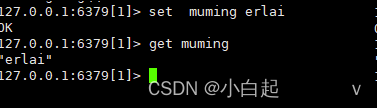
注意: set zhuge 666 //int类型可自增
set tuling 66a//string类型不可自增
//原因在于:获得数据先尝试强转int,能转则int,不能转string
object encoding xx//查看具体存储类型
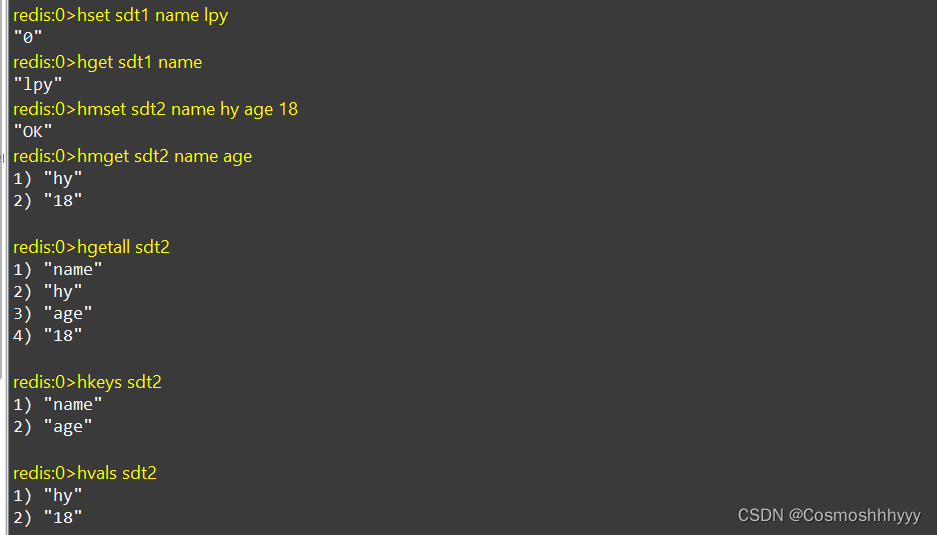
2.2.1Hash类型


特别的应用:如一个对象类型:name:zhuge balance:1888
可以将其处理为:双层map结构,把字段分开放在hash结构里,然后用一个hashset来存储。
和json相比,可以直接操作某个字段,处理起来更快、更好。
2.2.2Hash类型应用场景

应用场景:电商购物车
获得购物车所有商品,根据id, 对商品数量做添加、删除,展示商品总量
可以通过redis来操作
- 通过hset cart:1001 10088 1 添加指定商品,只保留商品ID信息,通过ID来操作,更轻便,更快捷。
- 已知商品ID, 获取商品全量信息可以用id在数据库总查询。
2.3.1list类型


关于队列,可以使用list来实现先进先出。FIFO
特别的: BRPOP其中B表示Blocking的意思,当队列没有数据时,会阻塞。适用于分布式结构。
2.3.2list类型的应用
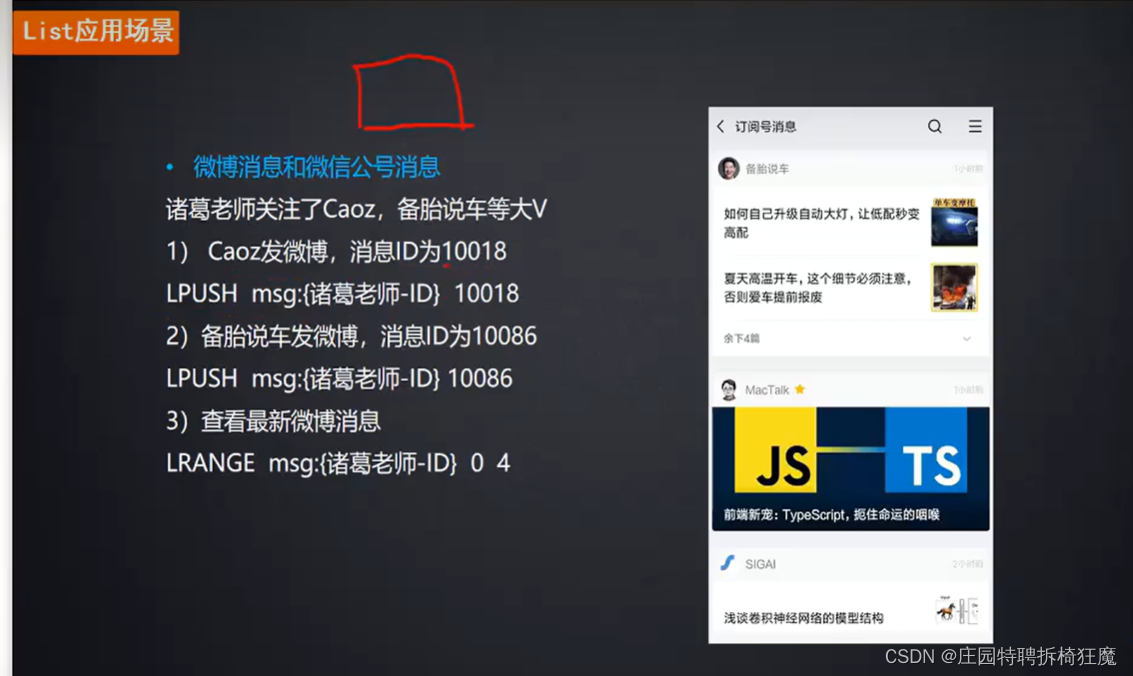
应用场景:微博|微信消息
对于这种大量的消息来说,用oder By来排序,性能很低。可以用redis的list来实现,其本身就是按时间顺序排列的,其可以LRANGE XX 0 4 通过下标来取一部分数,且支持负向索引
- 发消息,根据ID插入对应博文的list里即可
2.4.1set类型

 注意:set里的数据是无序的
注意:set里的数据是无序的
2.4.2set类型的应用

应用场景:微信小程序抽奖
将参与抽奖的人的ID放入Set,然后抽取指定数量,set本身是无序的,所以可以实现随机抽取。
有两种抽法:抽取放回
抽取不放回:可以设置多个奖励等级

应用场景:微博微信点赞、收藏、标签
实现:将用户ID维护到一个list里。

关注模型:共同关注|推荐关注

摘自:https://www.cnblogs.com/mike-mei/p/14663635.html
应用场景:共同关注
实现:将关注列表维护成set集合,通过交际|并集,获得指定集合数据。
2.5.1Zset类型

2.5.2Zset类型的应用

Zset是有序的结构,能支撑有序数据的展示。
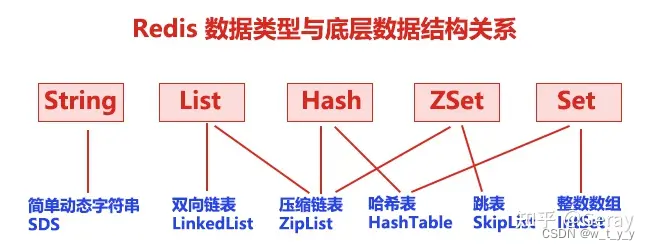
3.Redis的数据结构的存储格式

Redis 的存储结构: key:value
其中key是string 类型,value的类型有:string、hash、list、set、Zset
接下来分别介绍各个数据类型的结构及应用:
| 数据类型 | 存储结构 |
| string | 简单动态字符串SDS |
| hash | 哈希表O(1)、压缩列表O(N) |
| list | 压缩列表O(N)、双向链表O(N) |
| set | 哈希表O(1)、整数数组O(N) |
| Zset(有序) | 压缩列表O(N)、跳表 |
跳表:
其实,简单来说,跳表其实是一种多层的有序链表。跳表来源于链表,在链表的基础上结合了二分的思想进行改造,我们把改造之后的数据结构叫做跳表(Skip list)。
我们知道:二分查找针对的有序数组,时间复杂度是o(logn)。如果是有序链表,查询和插入的的时间复杂度是o(n)。跳表就是链表的“二分查找”。redis的有序集合用的就是跳表算法。
跳表中查询一个数据的时间复杂度就是 O(m*logn)
压缩列表和跳表:
压缩表的底层存储是是数组,查找快,但是增删慢,是一种以时间换空间的存储方式。

跳表最开始是由有序链表优化而来,增删快,查找慢。其保存冗余索引,但是不是B树、B+树,但是性能接近折半查找。是一种以空间换时间的存储方式。
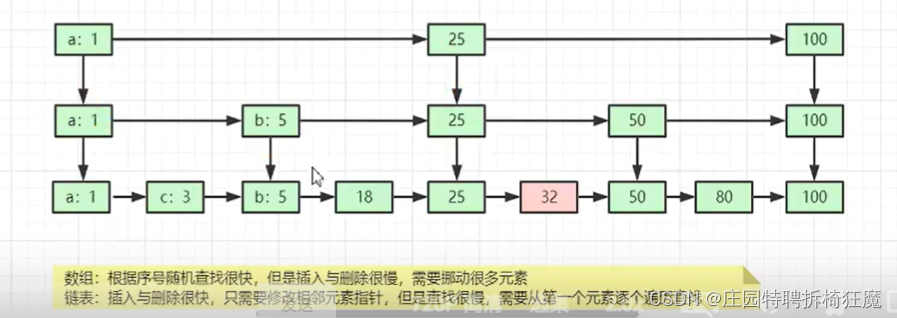

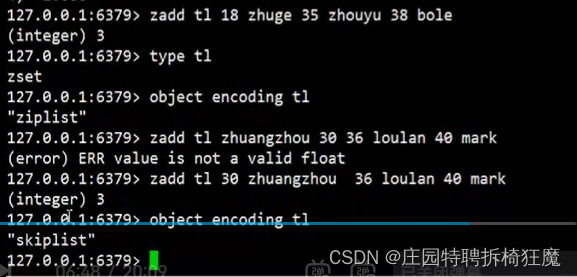
什么时候用?什么样的场景用什么样的数据结构。
对于时间有要求用跳表;对于空间有要求用压缩数组;可以通过在配置文件配置redis.conf优先使用哪种存储结构。




















![无重复字符的最长子串[中等]](https://img-blog.csdnimg.cn/direct/997518163c9e43ed99cec5f28cbb2ed1.webp)