Vision-Language Foundation Models as Effective Robot Imitators
使用视觉-语言基础模型对机器人进行有效的模仿
文章目录
-
- Vision-Language Foundation Models as Effective Robot Imitators
- 使用视觉-语言基础模型对机器人进行有效的模仿
- ABSTRACT
- 摘要
- 1 INTRODUCTION
- 1 引言
- 2 RELATED WORK
- 2 相关工作
- 3 BACKGROUND
- 3 背景
- 4 ROBOFLAMINGO
- 5 EXPERIMENTS
- 5 实验
- 6 CONCLUSION AND FUTURE WORK
- 6 结论与未来工作
- ACKNOWLEDGEMENTS
- 致谢
- A ENVIRONMENTAL SETUPS
- A 环境设置
- B EXTENDED EXPERIMENTAL RESULTS
- B 扩展实验结果
ABSTRACT
摘要
Recent progress in vision language foundation models has shown their ability to understand multimodal data and resolve complicated vision language tasks, including robotics manipulation. We seek a straightforward way of making use of existing vision-language models (VLMs) with simple fine-tuning on robotics data. To this end, we derive a simple and novel vision-language manipulation framework, dubbed RoboFlamingo, built upon the open-source VLMs, OpenFlamingo. Unlike prior works, RoboFlamingo utilizes pre-trained VLMs for single-step visionlanguage comprehension, models sequential history information with an explicit policy head, and is slightly fine-tuned by imitation learning only on languageconditioned manipulation datasets. Such a decomposition provides RoboFlamingo the flexibility for open-loop control and deployment on low-performance platforms. By exceeding the state-of-the-art performance with a large margin on the tested benchmark, we show that RoboFlamingo can be an effective and competitive alternative to adapt VLMs to robot control. Our extensive experimental results also reveal several interesting conclusions regarding the behavior of different pre-trained VLMs on manipulation tasks. RoboFlamingo can be trained or evaluated on a single GPU server, and we believe it has the potential to be a cost-effective and easy-to-use solution for robotics manipulation, empowering everyone with the ability to fine-tune their own robotics policy. Codes and model weights are public at roboflamingo.github.io.
近期视觉语言基础模型的研究进展表明,它们能够理解多模态数据并解决复杂的视觉语言任务,包括机器人操纵。我们寻求一种简单直接的方法,利用现有的视觉语言模型(VLMs)并通过简单的在机器人数据上的微调来使用它们。为此,我们开发了一个简单新颖的视觉语言操纵框架,名为RoboFlamingo,建立在开源VLMs OpenFlamingo之上。与之前的工作不同,RoboFlamingo利用预训练的VLMs进行单步视觉语言理解,用一个显式的策略头模型来模拟序列历史信息,并且只通过模仿学习,在语言条件操纵数据集上进行轻微的微调。这种分解使得RoboFlamingo具有在开环控制和低性能平台上部署的灵活性。通过在测试基准上以大幅超过最先进性能,我们展示了RoboFlamingo可以成为一个有效且有竞争力的方法,用于将VLMs适配到机器人控制。我们广泛的实验结果还揭示了关于不同预训练VLMs在操纵任务上的行为的几个有趣结论。RoboFlamingo可以在单个GPU服务器上进行训练或评估,我们相信它有可能成为一个成本效益高且易于使用的机器人操纵解决方案,让每个人都能微调自己的机器人策略。代码和模型权重在roboflamingo.github.io上公开。
1 INTRODUCTION
1 引言
Recent progress in vision-language foundation models (VLM) has presented their exhilarating ability in modeling and aligning the representation of images and words, and the unlimited potential to resolve a wide range of downstream tasks with multi-modality data, for instance, visual questionanswering (Li et al., 2023; Zhou et al., 2022), image captioning (Zeng et al., 2022; Wang et al., 2022; Li et al., 2021), human-agent interactions (Liu et al., 2022b; Oertel et al., 2020; Seaborn et al., 2021). These successes, undeniably, encourage people to imagine a generalist robot equipped with such a vision-language comprehension ability to interact naturally with humans and perform complex manipulation tasks.
在视觉-语言基础模型(VLM)的最新进展中,它们在建模和对齐图像和文字表示方面展现出令人振奋的能力,并在多模态数据下解决各种下游任务中具有无限潜力,例如视觉问答(Li等人,2023; Zhou等人,2022),图像字幕(Zeng等人,2022; Wang等人,2022; Li等人,2021),人-代理互动(Liu等人,2022b; Oertel等人,2020; Seaborn等人,2021)。这些成功无疑激励人们想象一台通用机器人,具备这样的视觉-语言理解能力,能够与人类自然交互并执行复杂的操作任务。
Therefore, we aim to explore integrating vision-language foundation models to serve as robot manipulation policies. While there have been some previous studies that incorporated large language models (LLMs) and vision-language models (VLMs) into robot systems as high-level planners (Ahn et al., 2022; Driess et al., 2023), making use of them directly for low-level control still poses challenges. Most VLMs are trained on static image-language pairs, whereas robotics tasks require video comprehension for closed-loop control. Additionally, VLM outputs primarily consist of language tokens, which significantly differ in representation compared to robot actions. A recent work (Brohan et al., 2023), namely Robotics Transformer 2 (RT-2), has demonstrated a possible solution for adapting VLMs to low-level robot control. However, democratizing such an expensive framework for all robotics practitioners proves difficult as it utilizes private models and necessitates co-fine-tuning on extensive vision-language data to fully showcase its effectiveness. Consequently, there is an urgent need for robot communities to have a low-cost alternative solution that effectively enables a robot manipulation policy with VLMs.
因此,我们的目标是探索将视觉-语言基础模型整合为机器人操作策略。尽管之前有一些研究将大型语言模型(LLMs)和视觉-语言模型(VLMs)纳入机器人系统作为高级规划器(Ahn等人,2022; Driess等人,2023),但直接将它们用于低级控制仍然存在挑战。大多数VLMs是在静态图像-语言对上训练的,而机器人任务则需要对闭环控制的视频理解。此外,VLM的输出主要包括语言标记,与机器人动作相比在表示上存在显著差异。最近的工作(Brohan等人,2023),即Robotics Transformer 2(RT-2),已经展示了一种可能的解决方案,可以将VLMs适应低级机器人控制。然而,让所有机器人领域的从业者都能使用这样昂贵的框架证明是困难的,因为它使用私有模型并需要在广泛的视觉-语言数据上进行协同微调,以充分展示其有效性。因此,机器人社区迫切需要一个低成本的替代方案,能够有效地利用VLM实现机器人操作策略。
To this end, we introduce RoboFlamingo, a novel vision-language manipulation framework that leverages publicly accessible pre-trained VLMs to effectively construct manipulation policies for robotics. Specifically, RoboFlamingo is grounded upon the open-source VLM, OpenFlamingo (Awadalla et al., 2023), and resolves the challenge by decoupling visual-language understanding and decision making. Unlike previous works, RoboFlamingo takes advantage of pre-trained VLMs mainly for understanding vision observations and language instructions at every decision step, models the historical features with an explicit policy head, and is fine-tuned solely on language-conditioned manipulation datasets using imitation learning. With such a decomposition, only a minimal amount of data is required to adapt the model to downstream manipulation tasks, and RoboFlamingo also offers flexibility for open-loop control and deployment on low-performance platforms. Moreover, benefiting from the pretraining on extensive vision-language tasks, RoboFlamingo achieves state-of-the-art performance with a large margin over previous works, and generalizes well to zero-shot settings and environments. It is worth noting that RoboFlamingo can be trained or evaluated on a single GPU server. As a result, we believe RoboFlamingo can be a cost-effective yet high-performance solution for robot manipulation, empowering everyone with the ability to fine-tune their own robots with VLMs.
为此,我们推出了RoboFlamingo,这是一个新颖的视觉-语言操作框架,利用公开可访问的预训练VLMs,有效构建机器人操作策略。具体而言,RoboFlamingo基于开源VLM OpenFlamingo(Awadalla等人,2023),通过解耦视觉-语言理解和决策制定来解决挑战。与先前的工作不同,RoboFlamingo主要利用预训练的VLMs来理解每个决策步骤中的视觉观察和语言指令,用显式策略头模拟历史特征,并仅在使用模仿学习的语言条件操作数据集上进行微调。通过这种分解,只需极小量的数据即可使模型适应下游操作任务,并且RoboFlamingo还为开环控制和在低性能平台上部署提供了灵活性。此外,由于在广泛的视觉-语言任务上进行预训练,RoboFlamingo在性能上取得了领先于先前工作的巨大优势,并且在零样本设置和环境中具有很好的泛化能力。值得注意的是,RoboFlamingo可以在单个GPU服务器上进行训练或评估。因此,我们相信RoboFlamingo可以是机器人操作的经济且高性能的解决方案,使每个人都能够使用VLM微调自己的机器人。
Through extensive experiments, we demonstrate that RoboFlamingo outperforms existing methods by a clear margin. Specifically, we evaluate its performance using the Composing Actions from Language and Vision benchmark (CALVIN) (Mees et al., 2022b), a widely-recognized simulation benchmark for long-horizon language-conditioned tasks. Our findings indicate that RoboFlamingo is an effective and competitive alternative for adapting VLMs to robot control, achieving 2x performance improvements compared with the previous state-of-the-art method. Our comprehensive results also yield valuable insights into the use of pre-trained VLMs for robot manipulation tasks, offering potential directions for further research and development.
通过大量实验,我们展示了RoboFlamingo在性能上明显优于现有方法。具体来说,我们使用Composing Actions from Language and Vision基准(CALVIN)(Mees等人,2022b)评估其性能,这是一个广受认可的用于长时程语言条件任务的仿真基准。我们的研究结果表明,RoboFlamingo是将VLMs适应机器人控制的一种有效且有竞争力的替代方案,相较于先前的最先进方法,性能提高了2倍。我们全面的结果还为利用预训练VLMs进行机器人操作任务提供了有价值的见解,为进一步的研究和开发提供了潜在的方向。
2 RELATED WORK
2 相关工作
Language can be the most intuitive and pivotal interface for human-robot interaction, enabling non-expert humans to seamlessly convey their instructions to robots for achieving diverse tasks. Consequently, the realm of language-conditioned multi-task manipulation has garnered substantial attention in recent years. Intuitively, such tasks require robots to have a good understanding of not only the visual captures of the outside world, but also the instructions represented by words. With the strong representation ability of pre-trained vision and language models, a lot of previous works have incorporated pre-trained models into the learning framework. Among them, we roughly classify them into the following three categories, which is also illustratively compared in Fig. 1.
语言可以成为人机交互的最直观和关键的界面,使非专业人士能够无缝地传达他们的指令,以便机器人完成各种任务。因此,近年来,语言条件的多任务操作领域引起了相当大的关注。直观地说,这些任务要求机器人不仅对外界的视觉捕捉有很好的理解,还要理解由单词表示的指令。借助预训练的视觉和语言模型的强大表示能力,许多先前的工作已经将预训练模型纳入学习框架。其中,我们将它们粗略地分为以下三类,如图1中形象化地比较。
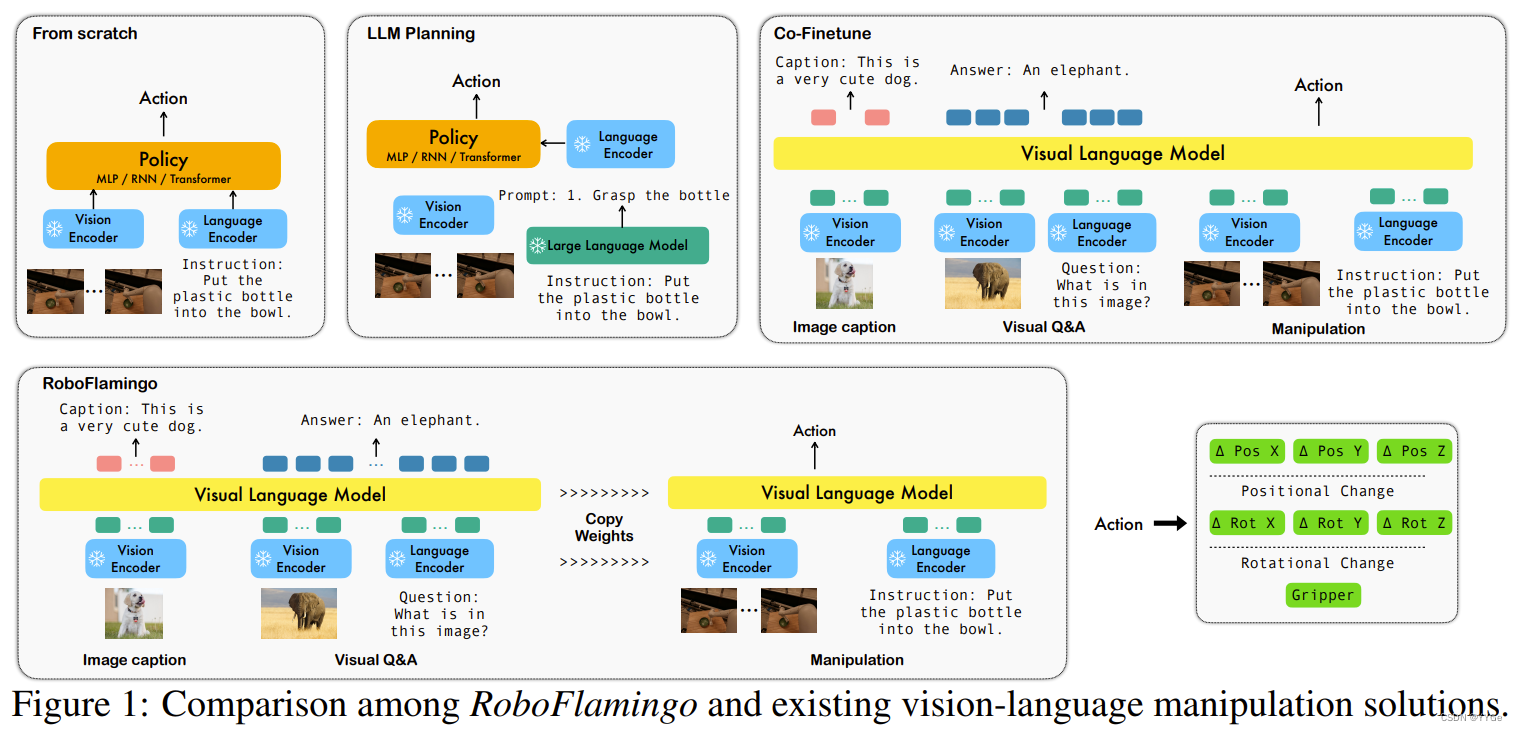
图1:RoboFlamingo与现有的视觉-语言操作解决方案的比较。
Fine-tuning. While some early works such as Jang et al. (2022); Lynch & Sermanet (2020) trained a vision encoder and a language encoder to learn representations for the input language and vision data from manipulation tasks, some recent work directly takes pre-trained models to obtain great representations, then trains the policy model beyond them from scratch or fine-tuning the whole model. For instance, Jiang et al. (2023) utilizes a pre-trained T5 (Raffel et al., 2020) model to encode the multi-modal prompts, and learn the actions by fine-tuning the T5 model and additionally training an object encoder and attention layers. HULC (Mees et al., 2022a) utilizes the vision encoder of Lynch & Sermanet (2020) trained on the CALVIN dataset (Mees et al., 2022b) and some pre-trained language encoder models such as sentence transformer (Reimers & Gurevych, 2019), and their HULC++ (Mees et al., 2023) also fine-tunes these encoders. Besides, Brohan et al. (2022) proposed RT-1, i.e., robotics transformers, a 35M vision-language-action model (VLA) which tokenizes the action and aligns the vision, language, and action in the token space and is trained on a large amount of real-world manipulation dataset, using the Universal Sentence Encoder (Cer et al., 2018) to obtain the language embedding and the pre-trained EfficientNet-B3 (Tan & Le, 2019) as the vision tokenizer.
微调: 一些早期的工作,如Jang等人(2022)和Lynch&Sermanet(2020),训练了一个视觉编码器和一个语言编码器,用于学习来自操作任务的输入语言和视觉数据的表示。而一些最近的工作则直接采用预训练模型来获取出色的表示,然后从头开始训练或对整个模型进行微调以训练策略模型。例如,Jiang等人(2023)利用预训练的T5(Raffel等人,2020)模型对多模态提示进行编码,并通过微调T5模型并额外训练对象编码器和注意力层来学习动作。HULC(Mees等人,2022a)利用了在CALVIN数据集(Mees等人,2022b)上训练的Lynch&Sermanet(2020)的视觉编码器以及一些预训练语言编码器模型,如sentence transformer(Reimers&Gurevych,2019),其HULC++(Mees等人,2023)还对这些编码器进行了微调。此外,Brohan等人(2022)提出了RT-1,即机器人变压器,一个35M视觉-语言-动作模型(VLA),它对动作进行标记并在令牌空间中对齐视觉、语言和动作,并在大量真实世界操作数据集上进行训练,使用Universal Sentence Encoder(Cer等人,2018)获取语言嵌入,以及预训练的EfficientNet-B3(Tan&Le,2019)作为视觉标记器。
LLM planning. Some approaches have exploited large language models (LLMs) as a powerful zero-shot planner, e.g., SayCan Ahn et al. (2022), to generate step-by-step pre-defined plans with human-interactive prompts on given tasks, subsequently instructing different pre-trained low-level skill policies to execute those plans and finish multiple tasks. Compared to other works, the controlling policies do not require any ability to understand instructions, but rely on the pre-trained frozen LLM to select necessary skills.
LLM规划: 一些方法利用大型语言模型(LLMs)作为强大的零射击规划器,例如SayCan Ahn等人(2022),以在给定任务上使用人机交互提示生成逐步预定义的计划,随后指导不同的预训练低级技能策略执行这些计划并完成多个任务。与其他工作相比,控制策略不需要任何理解指令的能力,而是依赖于预训练的固定LLM来选择必要的技能。
Co-Fine-Tuning. Driess et al. (2023) proposed 540B PaLM-E model, showing a different way of utilizing the pre-trained vision and language model. Specifically, they choose different pre-trained models to encoder the input scene, and the PaLM (Chowdhery et al., 2022) model as the base model, train the model to generate pre-defined multi-step plans described by language by co-fine-tuning the whole VLM end-to-end using both mobile manipulation question-answering data and auxiliary vision-language training data such as image captioning and visual question answering data collected from the web. Similar to SayCan (Ahn et al., 2022), they require low-level control policies to execute the generated plans. Motivated by PaLM-E, Brohan et al. (2023) further introduced RT-2, which is based on RT-1 but is adapted to use large vision-language backbones like PaLI-X (Chen et al., 2023) and PaLM-E (Driess et al., 2023), train the policy utilizing robot manipulation data both the web data. Their method reveals that VLMs have the potential to be adapted into robot manipulation, yet their key co-fine-tuning training strategy requires a large amount of both web-scale data vision-language data and low-level robot actions. Additionally, the VLMs and the data they use are private, making it hard for every robotics practitioner to play on such a solution for their own.
协同微调: Driess等人(2023)提出了540B PaLM-E模型,展示了利用预训练视觉和语言模型的不同方式。具体来说,他们选择不同的预训练模型来编码输入场景,以及PaLM(Chowdhery等人,2022)模型作为基础模型,通过对整个VLM进行协同微调,使用移动操作问答数据和辅助视觉-语言训练数据(如从网络收集的图像字幕和视觉问题回答数据)来生成预定义的多步计划的语言进行训练。类似于SayCan(Ahn等人,2022),他们需要低级控制策略来执行生成的计划。受PaLM-E的启发,Brohan等人(2023)进一步引入了RT-2,它基于RT-1,但适应于使用大型视觉-语言骨干(如PaLI-X(Chen等人,2023)和PaLM-E(Driess等人,2023))进行训练的策略,利用了来自网络数据和机器人操作数据的方法。他们的方法揭示了VLMs有望适应机器人操作,然而他们的关键协同微调训练策略需要大量的网络规模数据,视觉-语言数据和低级机器人操作。
Although these previous models somehow bridge the gap between vision and language on robot manipulation tasks, they either reply on low-level skill policies, like SayCan and PaLM-E; or train a whole large model, such as RT-1; or require a huge amount of vision-language data and computational resources to ensure the model learns the manipulation policy without forgetting the great alignment of vision and language. Compared with these works, our proposed RoboFlamingo is a simple and intuitive solution to easily adapt existing VLMs (OpenFlamingo (Alayrac et al., 2022; Awadalla et al., 2023) used in this paper), only requiring fine-tuning on a small number of manipulation demonstrations. We hope RoboFlamingo provides a different perspective on fully leveraging the ability of VLMs, while requiring less data collection costs and computing consumption to make it an open and easy-to-use solution for everyone
与这些工作相比,我们提出的RoboFlamingo是一个简单而直观的解决方案,可以轻松地适应现有的VLMs(本文中使用的是OpenFlamingo(Alayrac等人,2022; Awadalla等人,2023)),只需在少量操纵演示中进行微调。我们希望RoboFlamingo能够提供一种不同的视角,充分利用VLMs的能力,同时减少数据收集成本和计算消耗,使其成为一个对每个人都开放且易于使用的解决方案。
3 BACKGROUND
3 背景
Robot manipulation. In this paper, we mainly consider robot manipulation tasks, where the agent (robot) does not have access to the ground-truth state of the environment, but visual observations from different cameras and its own proprioception states. As for the action space, it often includes the relative target pose and open/closed state of the gripper. For instance, in the testbed of CALVIN (Mees et al., 2022b), the observations consist of simulated camera captures from two different views, and the action is a 7-DoF control of a Franka Emika Panda robot arm with a parallel gripper, and the instructions are reaching goals, i.e., the after-the-fact descriptions.
机器人操作。在本文中,我们主要考虑机器人操作任务,其中代理(机器人)无法访问环境的地面真实状态,但可以获得来自不同摄像机和自身本体感知状态的视觉观察。至于动作空间,通常包括相对目标姿态和夹爪的开/闭状态。例如,在CALVIN的测试平台(Mees等人,2022b)中,观察结果包括来自两个不同视角的模拟摄像机捕捉,动作是对Franka Emika Panda机器人臂和并行夹爪进行的7自由度控制,指令是达到目标,即事后的描述。
Imitation learning. Imitation learning (Pomerleau, 1988; Zhang et al., 2018; Liu et al., 2020; Jang et al., 2022) allows the agent to mimic the manipulation plans from instruction-labeled expert play data D = {(τ, l)i} D i=0, where D is the number of trajectories, l is the language instruction, and τ = {(ot, at)} contains preceding states and actions to reach the goal described by the given instruction. The learning objective can be simply concluded as a maximum likelihood goal-conditioned imitation objective to learn the policy πθ:
模仿学习。模仿学习(Pomerleau,1988; Zhang等人,2018; Liu等人,2020; Jang等人,2022)允许agent 从带有指令标签的专家播放数据 D = {(τ, l)i} D i=0 中模仿操作计划,其中 D 是轨迹数量,l 是语言指令,τ = {(ot, at)} 包含了达到给定指令描述的目标的前述状态和动作。学习目标可以简单地总结为最大似然目标条件的模仿目标,以学习策略πθ:

4 ROBOFLAMINGO
RoboFlamingo, a generalized robotics agent, excels in resolving language-conditioned manipulation tasks. The key idea is to draw help from pre-trained vision-language models (VLMs) and adapt them to manipulation policies, acquiring the ability of object grounding, language comprehension, vision-language alignment, and long-horizon planning. Particularlly, RoboFlamingo look into one of the popular VLMs, Flamingo (Alayrac et al., 2022), and take its open-source model OpenFlamingo (Awadalla et al., 2023) as the backbone. The overview of RoboFlamingo is shown in Fig. 2. To adapt large-scale vision-language models to robotic manipulation, RoboFlamingo simply adds a policy head for end-to-end finetuning. It addresses three main challenges: 1) it adapts visionlanguage models with static image inputs to video observations; 2) it generates robot control signals instead of text-only outputs; 3) it requires a limited amount of downstream robotic manipulation data to achieve high performance and generality with billions of trainable parameters. We will elaborate on the design of RoboFlamingo in this section.
RoboFlamingo,一种通用的机器人代理,在解决语言条件的操作任务方面表现出色。其关键思想是利用预训练的视觉-语言模型(VLMs)并将其调整为操作策略,获得物体定位、语言理解、视觉-语言对齐和长时程规划的能力。具体而言,RoboFlamingo研究了一种流行的VLM,Flamingo(Alayrac等人,2022),并采用其开源模型OpenFlamingo(Awadalla等人,2023)作为骨干。RoboFlamingo的概述如图2所示。为了将大规模的视觉-语言模型适应到机器人操作中,RoboFlamingo简单地添加了一个策略头进行端到端微调。它解决了三个主要挑战:1)将静态图像输入的视觉-语言模型适应到视频观察;2)生成机器人控制信号而不是仅文本输出;3)需要有限量的下游机器人操纵数据以实现具有数十亿可训练参数的高性能和通用性。在本节中,我们将详细介绍RoboFlamingo的设计。
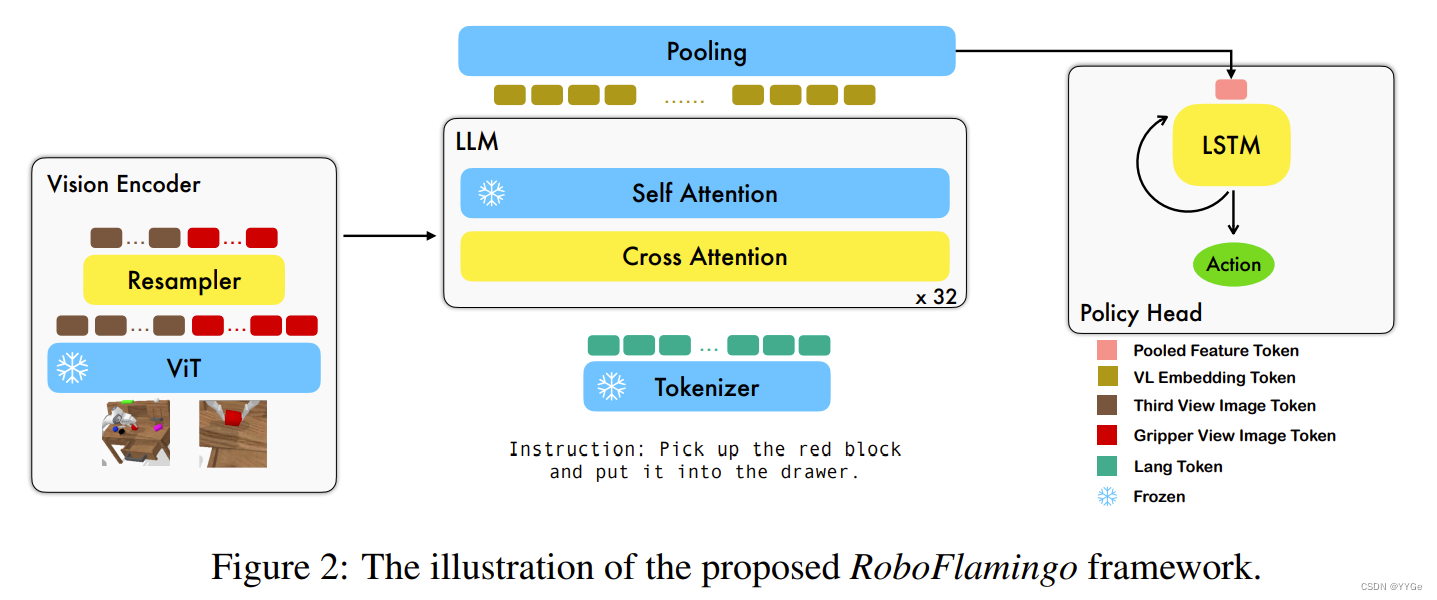
4.1 LANGUAGE-CONDITIONED ROBOT CONTROL
4.1 语言条件的机器人控制
The problem of language-conditioned robot control can be modeled as a goal-conditioned partially observable Markov decision process (GC-POMDP) (Liu et al., 2022a): M = ⟨S, O, A, T , ρ0,L, ϕ, f⟩, where S and O are the set of states and observations separately, A is the action space, T : S ×A → S is the environment dynamics function, ρ0 : S → [0, 1] is the initial state distribution, , ϕ(s) indicate if the task is successful, and f(o|s) : S → O is the observation function. Specifically, for each controlling episode, the robot is given a goal, represented by a length-M free-form language instruction l ∈ L at every time step t, and the observations ot are typically two images It, Gt from a third-perspective camera and a gripper camera. The controlling policy can be modeled as a goal-conditioned policy π(a|o, l) : S × L → A and the action a is typically the desired relative position and pose of the gripper, along with its open/close status
语言条件的机器人控制问题可以建模为一个目标条件的部分可观察马尔可夫决策过程(GC-POMDP)(Liu等人,2022a):M = ⟨S,O,A,T,ρ0,L,ϕ,f⟩,其中 S 和 O 分别是状态和观察的集合,A 是动作空间,T:S × A → S 是环境动态函数,ρ0:S → [0,1] 是初始状态分布,ϕ(s) 表示任务是否成功,f(o|s):S → O 是观察函数。具体而言,对于每个控制的情节,机器人在每个时间步 t 都会得到一个由长度为 M 的自由形式语言指令 l ∈ L 表示的目标,并且通常观察到的 ot 通常是来自第三人称摄像机和夹爪摄像机的两个图像 It, Gt。控制策略可以被建模为目标条件的策略 π(a|o, l):S × L → A,动作 a 通常是夹爪的期望相对位置和姿态,以及其开/闭状态。
In our RoboFlamingo, the policy πθ(a|o, l) is parameterized by θ. It consists of a backbone based on Flamingo fθ and a policy head pθ. The backbone takes visual observations and language-represented goals as the input and provides a latent fused representation at each time step for the policy head: Xt = fθ(ot, l). Then the policy head further predicts the action to fulfill the specified goal for the robot: at = pθ(Xt, ht−1), where ht−1 is the hidden state from the last step that encodes the history information for decision-making. We will introduce each module in detail in the following sections.
在我们的RoboFlamingo中,策略 πθ(a|o, l) 由参数 θ 参数化。它包括一个基于Flamingo的骨干 fθ 和一个策略头 pθ。骨干将视觉观察和语言表示的目标作为输入,并在每个时间步为策略头提供一个潜在的融合表示:Xt = fθ(ot, l)。然后策略头进一步预测动作以实现机器人的指定目标:at = pθ(Xt, ht−1),其中 ht−1 是来自上一步的隐藏状态,用于编码决策制定的历史信息。我们将在以下各节详细介绍每个模块。
4.2 THE FLAMINGO BACKBONE
4.2 FLAMINGO 骨干
We adopt the flamingo backbone fθ for understanding the vision and language inputs at every decision step. The vision observations are encoded by the vision encoder to the latent state and are further fused with language goals through the feature fusion decoder, which is initialized by a pre-trained language model.
我们采用 flamingo 骨干 fθ 来理解每个决策步骤的视觉和语言输入。视觉观察通过视觉编码器编码为潜在状态,然后通过特征融合解码器与语言目标进一步融合,该解码器由预训练语言模型初始化。
4.2.1 VISION ENCODER
4.2.1 视觉编码器
The vision encoder consists of a vision transformer (ViT) (Yuan et al., 2021) and a perceiver resampler (Alayrac et al., 2022). At every time step t, the two-view camera images It, Gt are encoded to Xˆ t, consisting of a visual token sequence, through the ViT module:
视觉编码器包括一个视觉变换器(Vision Transformer,ViT)(Yuan等人,2021)和一个感知重采样器(Perceiver Resampler)(Alayrac等人,2022)。在每个时间步 t,两个视角摄像机图像 It, Gt 被编码为 Xˆ t,通过 ViT 模块形成一个视觉标记序列:
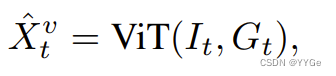
where Xˆ v t = (ˆx v t1 , · · · , xˆ v tN ) represents the visual token sequence at t, N represents the token number of the encoded output. After encoding, RoboFlamingo utilizes a perceiver resampler to compress the number of visual tokens from N to K. In other words, the resampler maintains a set of learnable parameters and utilizes the attention mechanism to reduce the number of token sequences to K. Formally, the resampler is formulated as:
其中 Xˆ v t = (ˆx v t1 , · · · , xˆ v tN ) 表示时间步 t 处的视觉标记序列,N 表示编码输出的标记数量。编码后,RoboFlamingo 利用感知重采样器将视觉标记的数量从 N 压缩到 K。换句话说,重采样器维护一组可学习的参数,并利用注意机制将标记序列的数量减少到 K。具体而言,重采样器被公式化为:

where QR ∈ R K×d corresponds to the learnable parameters of the resampler and serves as the query vector, d is the hidden dimension size, WR K , WR V ∈ R dv×d represents the linear transformation matrix of key and value, dv is the feature dimension of the visual token, KR and VR are the transformed key and value vector of vision input V
其中 QR ∈ R K×d 对应于重采样器的可学习参数,充当查询向量,d 是隐藏维度大小,WR K ,WR V ∈ R dv×d 表示密钥和值的线性变换矩阵,dv 是视觉标记的特征维度,KR 和 VR 是视觉输入 V 的转换密钥和值向量。
4.2.2 FEATURE FUSION DECODER
4.2.2 特征融合解码器
The compressed visual tokens output from the resampler Xv t ∈ R K×d are further passed to the feature fusion decoder, which is designed to generate the vision-language joint embedding by fusing the language instruction with the encoded vision feature Xv t . In RoboFlamingo, we utilize the pre-trained decoder from OpenFlamingo (Awadalla et al., 2023) and fine-tune the decoder module following the way as in Awadalla et al. (2023). Specifically, the decoder consists of L layers, each of which involves a transformer decoder layer and a cross-attention layer. The transformer layers are directly copied from a pre-trained language model (such as LlaMA (Touvron et al., 2023), GPT-Neox (Black et al., 2022) and MPT (Team et al., 2023)) and are frozen during the whole training process; the cross-attention layer takes the language token as query, and the encoded visual token as key and value, which is fine-tuned by imitation learning objectives on manipulation data (see following sub-sections). Formally, if we denote xi ∈ R d the i−th embedded token of the instruction, M the instruction length, and X ∈ RM×d is the embedded matrix of the instruction, then the embedded natural language instruction should be X = (x1, x2, · · · , xM) and output X l+1 t of the l-th decoder layer given the input Xl t is computed by:
从重采样器输出的压缩视觉标记 Xv t ∈ R K×d 进一步传递到特征融合解码器,该解码器旨在通过将语言指令与编码的视觉特征 Xv t 融合来生成视觉-语言联合嵌入。在 RoboFlamingo 中,我们利用来自 OpenFlamingo(Awadalla等人,2023)的预训练解码器,并按照 Awadalla 等人(2023)的方式对解码器模块进行微调。具体而言,解码器包括 L 层,每层包括一个变压器解码层和一个交叉注意层。变压器层直接复制自预训练的语言模型(如 LlaMA(Touvron等人,2023),GPT-Neox(Black等人,2022)和 MPT(Team等人,2023)),在整个训练过程中保持冻结;交叉注意层将语言标记作为查询,编码的视觉标记作为键和值,通过在操作数据上的模仿学习目标进行微调(见后面的小节)。形式上,如果我们用 xi ∈ R d 表示指令的第 i 个嵌入标记,M 表示指令长度,X ∈ RM×d 表示指令的嵌入矩阵,那么嵌入的自然语言指令应该是 X = (x1, x2, · · · , xM),给定输入 Xl t,第 l 层解码器层的输出 X l+1 t 计算如下:
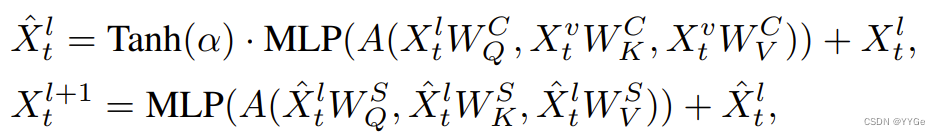
where X1 t = X, Xˆl t corresponds to the output of the gated cross-attention layer at time instant t, WC Q , WC K , WC V ∈ R d×d represents the learnable parameters of the cross-attention layer. α ∈ R is a learnable gate parameter to control the mixing weights for stability. WS Q, WS K, WS V ∈ R d×d represents the parameters of the self-attention layer and MLP represents a multi-layer perceptron network. With the deep interaction of the vision and language token, we expect the output Xt = XL t = {x L t,1 , xL t,2 , · · · , xL t,M} at time step t to be an informative vision-language joint embedding for robot manipulation.
其中 X1 t = X,Xˆl t 对应于时间点 t 的门控交叉注意层的输出,WC Q , WC K , WC V ∈ R d×d 表示交叉注意层的可学习参数。α ∈ R 是一个可学习的门参数,用于控制混合权重以提高稳定性。WS Q, WS K, WS V ∈ R d×d 表示自注意层的参数,MLP 表示多层感知器网络。通过视觉和语言标记的深度交互,我们期望在时间步 t 的输出 Xt = XL t = {x L t,1 , xL t,2 , · · · , xL t,M} 是一个信息丰富的视觉-语言联合嵌入,用于机器人操作。
4.3 POLICY HEAD
4.3 策略头
The output XL t from the feature fusion decoder is trained as the representation of the vision observation and language instruction, which will be further translated into low-level control signals. To achieve this, we simply adopt an additional policy head pθ to predict the action, e.g., the 7 DoF end-effector pose and gripper status. We test various strategies to model the historical observation sequences and behave as the policy head, e.g., a long short-term memory (LSTM) (Hochreiter & Schmidhuber, 1997) network with an MLP for the final prediction; a decoder-only transformer (Brown et al., 2020) similarly with an MLP; or a single MLP that only models single-step information (see Section 5 for more details). Taking the LSTM version as an example, with the vision-language joint embedding sequence XL t , we obtain an aggregated embedding through a max-pooling operation over the token dimension and predict the action as:
where ht represents the hidden state at t, and a pose t , a gripper t are the predicted end-effector pose and gripper status.
从特征融合解码器输出的 XL t 被训练为视觉观察和语言指令的表示,将进一步转化为低级别的控制信号。为了实现这一点,我们简单地采用了一个额外的策略头 pθ 来预测动作,例如 7 个自由度的末端执行器姿态和夹持器状态。我们测试了多种策略来建模历史观察序列并充当策略头,例如,一个带有 MLP 的长短时记忆(LSTM)(Hochreiter&Schmidhuber,1997)网络,用于最终预测;一个仅具有 MLP 的仅解码器变压器(Brown等人,2020);或者仅建模单步信息的单个 MLP(详见第 5 节以获取更多详细信息)。以 LSTM 版本为例,通过视觉-语言联合嵌入序列 XL t,我们通过对标记维度进行最大池操作获得聚合嵌入,并预测动作:

其中 ht 表示时间步 t 的隐藏状态,a pose t ,a gripper t 分别是预测的末端执行器姿态和夹持器状态。
4.4 TRAINING OBJECTIVE
4.4 训练目标
We utilize maximum likelihood imitation learning objectives to fine-tune the proposed pre-trained backbone and the policy head. Concretely, the desired relative pose is optimized via regression loss (we use mean squared error (MSE) loss) and the gripper status uses classification loss (we use binary cross-entropy (BCE) loss):
where aˆ pose t , aˆ gripper t is the demonstration for end effector pose and gripper status at timestep t, λgripper corresponds to the weight of gripper loss.
In the training procedure, we follow the fine-tuning paradigm of OpenFlamingo by only training the parameters of the resampler, the gated cross-attention module of each decoder layer, and the policy head while freezing all other parameters.
我们利用最大似然模仿学习目标来微调提出的预训练骨干和策略头。具体而言,通过回归损失(我们使用均方误差(MSE)损失)优化所需的相对姿态,夹持器状态使用分类损失(我们使用二元交叉熵(BCE)损失):
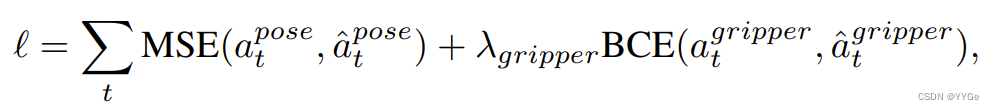
其中 aˆ pose t ,aˆ gripper t 是时间步 t 处末端执行器姿态和夹持器状态的演示,λgripper 对应于夹持器损失的权重。
在训练过程中,我们遵循 OpenFlamingo 的微调范例,仅训练重采样器的参数,每个解码器层的门控交叉注意模块和策略头,同时冻结所有其他参数。
5 EXPERIMENTS
5 实验
We conduct extensive experiments to examine the proposed RoboFlamingo solution, and answer how pre-trained VL models (VLMs) benefit language-conditioned robotic manipulation. In short, we investigate RoboFlamingo from the following perspectives:
1.Effectiveness. We wonder the imitation learning performance of RoboFlamingo by training it on the given demonstration data.
2.Zero-shot Generalization. We focus on generalization on unseen tasks. In other words, we wonder how the model will behave given unseen vision contexts like different objects, even with unseen instructions.
3.Ablation Studies. We further explore the essential factors that matter in adapting VLMs to robot control policy in the framework of RoboFlamingo.
我们进行了大量实验来检验提出的 RoboFlamingo 解决方案,并回答了预训练的 VL 模型(VLMs)如何有益于语言条件的机器人操作。简而言之,我们从以下几个角度研究了 RoboFlamingo:
有效性。 我们关注 RoboFlamingo 在给定演示数据上的模仿学习性能。
零样本泛化。 我们关注在未见任务上的泛化能力。换句话说,我们想知道模型在未见的视觉上下文(如不同的对象,甚至是未见的指令)下的行为如何。
消融研究。 我们进一步探讨在 RoboFlamingo 框架中将 VLMs 转化为机器人控制策略的关键因素。
5.1 BENCHMARK AND BASELINES
5.1 基准和基线
We choose CALVIN (Mees et al., 2022b), an open-source simulated benchmark to learn long-horizon language-conditioned tasks, as our testbed, and the corresponding datasets as our imitation learning demonstration data. CALVIN encompasses a total of 34 distinct tasks and evaluates 1000 unique instruction chains for sequential tasks. In each experiment, the robot is required to successfully complete sequences of up to five language instructions consecutively. The policy for each consecutive task is dependent on a goal instruction, and the agent advances to the subsequent goal only if it successfully accomplishes the current task. The dataset contains four splits for environments A, B, C, and D. Each consists of 6 hours of human-teleoperated recording data (more than 2 million trajectories) that might contain suboptimal behavior, and only 1% of that data is annotated with language instructions (∼24 thousand trajectories). See Fig. 4 in Appendix A.1 for a more detailed description and visualized examples of the benchmark.
我们选择 CALVIN(Mees et al., 2022b),一个用于学习长时序语言条件任务的开源模拟基准,作为我们的测试平台,并选择相应的数据集作为我们的模仿学习演示数据。CALVIN 包含总共 34 个不同的任务,为顺序任务评估了 1000 个独特的指令链。在每个实验中,机器人需要成功完成连续最多五个语言指令的序列。每个连续任务的策略取决于一个目标指令,仅当成功完成当前任务时,代理才会前进到下一个目标。数据集包含 A、B、C 和 D 四个环境的分割。每个分割包含 6 小时的人工远程操作记录数据(超过 200 万个轨迹),可能包含次优的行为,只有 1% 的数据用语言指令进行注释(约 2 万 4 千个轨迹)。有关基准的更详细描述和基准的可视化示例,请参见附录 A.1 中的图 4。
We compare a set of well-performed baselines in CALVIN: (1) MCIL (Lynch & Sermanet, 2020): a scalable framework combining multitask imitation with free-form text conditioning, which learns language-conditioned visuomotor policies, and is capable of following multiple human instructions over a long horizon in a dynamically accurate 3D tabletop setting. (2) HULC (Mees et al., 2022a): a hierarchical method that combines different observation and action spaces, auxiliary losses, and latent representations, which achieved the SoTA performance on CALVIN. (3) RT-1 (Brohan et al., 2022): robotics transformer, which directly predicts the controlling actions by action tokens, as well as vision and language inputs. RT-2 (Brohan et al., 2023) is not experimentally compared since we have no access of their code, data and model weights.
我们比较了 CALVIN 中一组表现良好的基线:(1) MCIL(Lynch & Sermanet, 2020):一个可扩展的框架,将多任务模仿与自由形式文本条件结合,学习语言条件的视觉运动策略,在动态准确的 3D 桌面设置中能够按照多个人的指令执行长时序的任务。 (2) HULC(Mees et al., 2022a):一个层次方法,结合不同的观察和动作空间、辅助损失和潜在表示,实现了在 CALVIN 上的 SoTA 性能。 (3) RT-1(Brohan et al., 2022):机器人变压器,通过动作令牌直接预测控制动作,以及视觉和语言输入。RT-2(Brohan et al., 2023)由于我们无法访问其代码、数据和模型权重,因此在实验中未进行比较。
5.2 IMITATION PERFORMANCE
5.2 模仿性能
We train RoboFlamingo using demonstrations only with language annotation from all 4 splits (A, B, C, and D), and evaluate the imitation performance on episodes sampled on split D (ABCD → D).The performance comparison is shown in Tab. 1. RoboFlamingo outperforms all baseline methods over all metrics by a large margin, even for those methods that are trained on the full set of data. This demonstrates the effectiveness of RoboFlamingo as the solution for robotics manipulation, enabling VLMs to become effective robot imitators.
我们使用来自所有 4 个分割(A、B、C 和 D)的带语言注释的演示数据训练 RoboFlamingo,并在分割 D 上评估模仿性能(ABCD → D)。性能比较如表 1 所示。RoboFlamingo在所有指标上均大幅优于所有基线方法,即使对于那些在完整数据集上进行训练的方法也是如此。这证明了 RoboFlamingo 作为机器人操作的解决方案的有效性,使 VLMs 成为有效的机器人模仿者。
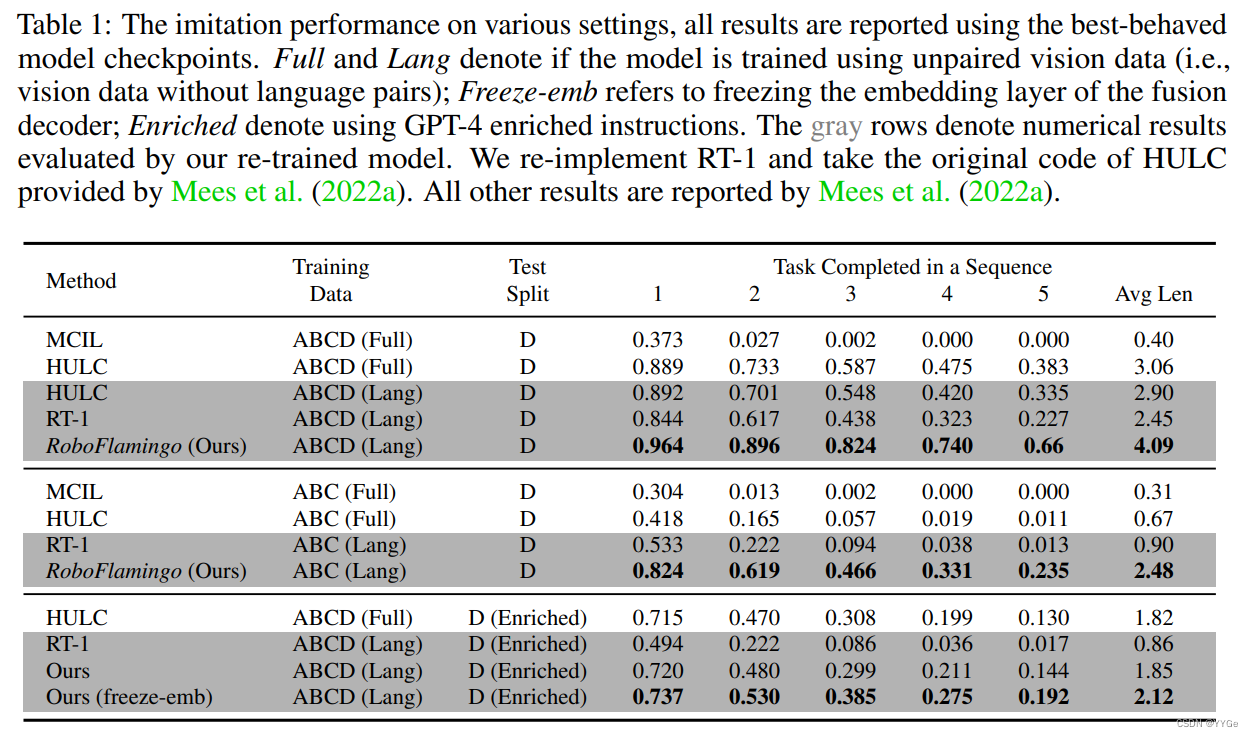
表1:各种设置下的模仿性能,所有结果都是使用表现最佳的模型检查点报告的。Full 和 Lang 表示模型是否使用未配对的视觉数据(即,没有语言配对的视觉数据)进行训练; Freeze-emb 指的是冻结融合解码器的嵌入层; Enriched 表示使用 GPT-4 丰富的指令。灰色行表示通过我们重新训练的模型评估的数值结果。我们重新实现了 RT-1,并采用了 Mees 等人提供的 HULC 的原始代码(Mees et al., 2022a)。所有其他结果均由 Mees 等人报告(Mees et al., 2022a)。
In addition, the success rate of the subsequent tasks can be regarded as a notion of the generalizability of the manipulation policies, since the initial state of a subsequent task highly relies on the ending state of its former task. The later a task is arranged in the task sequence, the more diverse its initial state is, which will need more powerful visual-language alignment abilities to successfully complete the task. Among all methods, RoboFlamingo achieves the highest success rate over the latter tasks. This demostrates that RoboFlamingo is able to utilize the visual-language grounding ability of pre-trained VLMs.
此外,后续任务的成功率可以被视为操纵策略的泛化能力的一个概念,因为后续任务的初始状态高度依赖于其前一个任务的结束状态。任务序列中安排的任务越晚,其初始状态的差异就越大,这将需要更强大的视觉语言对齐能力才能成功完成任务。在所有方法中,RoboFlamingo在后期任务上实现了最高的成功率。这表明 RoboFlamingo 能够利用预训练 VLMs 的视觉语言基础能力。
5.3 ZERO-SHOT GENERALIZATION
5.3 零样本泛化
To assess the zero-shot generalization ability, we evaluate RoboFlamingo in two aspects: vision and language
为了评估零样本泛化能力,我们从两个方面评估 RoboFlamingo:视觉和语言。
For vision generalization, we train models on splits A, B, and C and test on split D, which presents a different vision context. Our method significantly outperforms baselines in this vision generalization scenario (ABC → D), as shown in Table Tab. 1. Regarding language generalization, we enrich the language setting by generating 50 synonymous instructions for each task using GPT-4 (OpenAI, 2023). We then randomly sample instructions during evaluation. Our method exhibits superior performance compared to all baselines in this language generalization setting.
对于视觉泛化,我们在分割 A、B 和 C 上训练模型,并在分割 D 上进行测试,呈现了不同的视觉背景。在这个视觉泛化的情景中,我们的方法在表 Tab. 1 中明显优于基线。关于语言泛化,我们通过使用 GPT-4(OpenAI, 2023)生成每个任务的 50 条同义指令,丰富了语言设置。然后在评估过程中随机抽样指令。我们的方法在这种语言泛化设置中相对于所有基线表现出更好的性能。
It’s important to note that the success rate of our method on subsequent tasks shows a more noticeable drop compared to HULC. This may be due to our approach directly using word tokens as input during training, which can result in larger variations for synonymous sentences compared to HULC using a frozen sentence model for embedding instructions. To address this, we freeze the embedding layer of the feature fusion decoder in our method, leading to improved generalization and reduced performance drop.
值得注意的是,我们方法在后续任务上的成功率下降比 HULC 更为明显。这可能是因为我们的方法在训练期间直接使用单词标记作为输入,这可能导致与 HULC 使用冻结的句子模型嵌入指令相比,同义句子的变化更大。为了解决这个问题,我们冻结了我们方法中特征融合解码器的嵌入层,从而改善了泛化效果并减少了性能下降。
5.4 ABLATION STUDIES
5.4 消融研究
In this section, we conduct ablation studies for RoboFlamingo to answer the following questions:
1)How does RoboFlamingo perform with different heads?
2)Does vision-language (VL) pre-training improve downstream robotic tasks?
3)How do critical factors in VL pre-training affect robotic tasks?
在这一部分,我们对RoboFlamingo进行了消融研究,以回答以下问题:
RoboFlamingo使用不同的头部表现如何?
视觉-语言(VL)预训练是否改善下游机器人任务?
VL预训练中的关键因素如何影响机器人任务?
5.4.1 HOW DOES RoboFlamingo PERFORM WITH DIFFERENT HEADS?
5.4.1 RoboFlamingo使用不同头部的表现如何?
We validate the performance of RoboFlamingo with different policy heads. In particular, we compare 4 different implementations: (a) MLP w/o hist takes only the current observation as input to predict actions, which ignores the observation history. (b) MLP w hist takes the history frames into the vision encoder with position embedding, and encodes the history information through the cross-attention layers in the feature fusion decoder. © GP T and (d) LSTM both utilize the VLM backbone to process single-frame observation and integrate the history with the policy head. GP T explicitly takes the visual history as input to predict the next action. LSTM implicitly maintains a hidden state to encode memory and predict the action. We compare their best performance on the ABCD → D test setting in Fig. 3 (a). MLP w/o hist performs the worst, indicating the importance of the history information in the manipulation task. MLP w hist performs better than MLP w/o hist, but is still much worse than GP T and LSTM. We hypothesize that this may stem from the fact that the VLM we use (OpenFlamingo) has only seen image-text pairs during pre-training and cannot process consequent frames effectively. Further, the performance of GP T and LSTM are similar, we choose LSTM as the default choice due to its simplicity
我们验证了RoboFlamingo在不同策略头下的性能。具体而言,我们比较了4种不同的实现:(a) MLP w/o hist仅使用当前观察作为输入来预测动作,忽略了观察历史。(b) MLP w hist将历史帧与位置嵌入一起输入到视觉编码器中,并通过特征融合解码器中的交叉注意层对历史信息进行编码。© GPT和(d) LSTM都利用VLM骨干处理单帧观察,并通过策略头将历史集成进去。GPT明确将视觉历史作为输入来预测下一个动作。LSTM隐式地保持一个隐藏状态来编码内存并预测动作。我们比较了它们在ABCD → D测试设置中的最佳性能,如图3(a)所示。MLP w/o hist的性能最差,表明在操作任务中历史信息的重要性。MLP w hist的性能比MLP w/o hist好,但远远不如GPT和LSTM。我们假设这可能是因为我们使用的VLM(OpenFlamingo)只在预训练期间看到了图像-文本对,并且不能有效处理连续的帧。此外,GPT和LSTM的性能相
似,我们选择LSTM作为默认选择,因为它更简单。
Table 2: 在VLM的不同变体上进行的测试。Pre-train表示VLM在预训练的VL数据集上的原始性能,Best Avg. Len.表示VLM在5个epoch内平均成功长度的最佳性能,Mean Avg. Len.表示VLM在CALVIN的最后3个epoch上平均成功长度的平均性能。

5.4.2 DOES VL PRE-TRAINING IMPROVE DOWNSTREAM ROBOTIC TASKS?
5.4.2 VL预训练是否改善下游机器人任务?
To verify the necessity of VL pre-training, we train the same model without loading the pre-trained parameters of the cross-attention layers (denoted as No VL Pre-train). Besides, we also conduct an ablation study to freeze the pre-trained VLM and only train the policy head (denoted as No VL Finetune). As shown in Fig. 3 (b), we can see that vision-langauge pre-training crucially improves the downstream robotic manipulation by a large margin. Besides, tuning on the VL model itself on robotic tasks is indispensable due to limited capacity of the policy head.
为验证VL预训练的必要性,我们训练相同的模型,而不加载交叉注意层的预训练参数(表示为No VL Pre-train)。此外,我们还进行了一个消融研究,冻结了预训练的VLM,只训练策略头(表示为No VL Finetune)。如图3(b)所示,我们可以看到,视觉语言预训练大幅改善了下游机器人操作的性能。此外,在机器人任务本身对VL模型进行微调是不可或缺的,因为策略头的容量有限。
5.4.3 HOW DO CRITICAL FACTORS IN VL PRE-TRAINING AFFECT ROBOTIC TASKS?
5.4.3 VL预训练中的关键因素如何影响机器人任务?
Model Size. A larger model usually results in better VL performance. Yet, with full training data in CALVIN, we find that the smaller model is competitive with the larger model (see comparison in Tab. 2 and Appendix B.2). To further validate the impact of model size on downstream robotic tasks, we train different variants with 10% of language annotated data in CALVIN, which is only 0.1% of the full data. From Tab. 3 we can observe that with limited training data, the performance of VLMs is highly related to the model size. The larger model achieves much higher performance, indicating that a larger VLM can be more data-efficient.
模型大小。较大的模型通常会导致更好的VL性能。然而,在CALVIN的完整训练数据中,我们发现较小的模型与较大的模型竞争激烈(请参见表2和附录B.2中的比较)。为了进一步验证模型大小对下游机器人任务的影响,我们使用CALVIN中10%的语言注释数据训练了不同的变体,这仅占全套数据的0.1%。从表3中我们可以看到,对于有限的训练数据,VLM的性能与模型大小密切相关。较大的模型能更有效地利用数据。

Instruction Fine-Tuning. We have shown the performance of RoboFlamingo based on VL backbones with or without instruction fine-tuning in Table 2 and Appendix B.2. We can see that instruction fine-tuning in LLM can improve the performance of the policy in both seen and unseen scenarios by comparing the performance of M-3b-IFT against M-3b, and G-4b-IFT against G-4b.
指令微调。我们已经在表2和附录B.2中展示了基于VL骨干进行指令微调与否的RoboFlamingo的性能。我们可以看到,在看到和未看到的情况下,LLM中进行指令微调可以提高策略的性能,通过比较M-3b-IFT和M-3b,以及G-4b-IFT和G-4b的性能。
5.5 FLEXIBILITY OF DEPLOYMENT
5.5 部署的灵活性
Since our RoboFlamingo adopts a structure that separates the perception and policy module and leaves the main computation on the perception module, we could perform open loop control to accelerate the inference of RoboFlamingo. Through predicting several further step actions by the policy head without calling the perception module, the inference speed of RoboFlamingo can be largely boosted. Specifically, as illustrated in our Figure, the policy head is designed to predict the next three steps of actions, which are then fed into the perception module to update the hidden state. By bypassing repeated calls to the perception module for each action prediction, the inference speed of RoboFlamingo effectively tripled. However, as indicated in Fig. 3 ©, directly implementing open loop control without re-training may lead to deteriorated performance, retraining the model with jump step demonstration could alleviate the performance drop.
由于我们的RoboFlamingo采用了分离感知和策略模块的结构,并将主要计算留在感知模块上,我们可以执行开环控制以加速RoboFlamingo的推断。通过策略头预测若干步的行动而不调用感知模块,可以大大提高RoboFlamingo的推断速度。具体而言,如我们的图中所示,策略头被设计为预测接下来的三个步骤的行动,然后将其输入到感知模块以更新隐藏状态。通过避免为每个动作预测重复调用感知模块,RoboFlamingo的推断速度有效地提高了三倍。然而,正如图3©所示,直接实施开环控制而不重新训练可能会导致性能下降,通过使用跳步演示重新训练模型可以缓解性能下降。
6 CONCLUSION AND FUTURE WORK
6 结论与未来工作
This paper explores the potential of pre-trained vision-language models in advancing languageconditioned robotic manipulation. Our proposed RoboFlamingo, based on the pre-trained OpenFlamingo model, showcases state-of-the-art performance on a benchmark dataset. Moreover, our experimental findings highlight the benefits of pre-trained models in terms of data efficiency and zero-shot generalization ability. This research contributes to the ongoing efforts to develop intelligent robotic systems that can seamlessly understand and respond to human language instructions, paving the way for more intuitive and efficient human-robot collaboration. Due to the lack of real-robot data, this paper does not deploy on real-world robotics. To our delight, recent progress on large-scale real robotics data (Padalkar et al., 2023) has shown the potential of fine-tuning large VLMs for real robots, and the most exciting future work is to see how RoboFlamingo will behave in real-world tasks combined with such amount of data.
本文探讨了预训练视觉语言模型在推动语言条件下的机器人操作方面的潜力。我们提出的基于预训练的OpenFlamingo模型的RoboFlamingo在基准数据集上展示了最先进的性能。此外,我们的实验结果强调了预训练模型在数据效率和零样本泛化能力方面的优势。这项研究为开发能够无缝理解并响应人类语言指令的智能机器人系统的持续努力做出了贡献,为更直观高效的人机协作铺平了道路。由于缺乏真实机器人数据,本文并未在真实世界的机器人上进行部署。令人欣慰的是,最近在大规模真实机器人数据方面取得的进展(Padalkar et al., 2023)展示了使用大型VLM对真实机器人进行微调的潜力,最激动人心的未来工作是看看在结合如此大量数据的情况下RoboFlamingo将如何表现在真实世界的任务中。
ACKNOWLEDGEMENTS
致谢
The Shanghai Jiao Tong University team is supported by National Key R&D Program of China (2022ZD0114804), Shanghai Municipal Science and Technology Major Project (2021SHZDZX0102) and National Natural Science Foundation of China (62076161). The author Minghuan Liu is also supported by the ByteDance Scholarship and Wu Wen Jun Honorary Doctoral Scholarship.
上海交通大学团队获得中国国家重点研发计划(2022ZD0114804)、上海市科技重大专项项目(2021SHZDZX0102)和中国国家自然科学基金(62076161)的支持。作者Minghuan Liu还获得字节跳动奖学金和吴文俊荣誉博士奖学金的支持。
A ENVIRONMENTAL SETUPS
A 环境设置
A.1 THE CALVIN BENCHMARK
A.1 CALVIN基准
CALVIN (Mees et al., 2022b) is an open-source simulated benchmark for evaluating long-horizon language-conditioned tasks.
As shown in Fig. 4, CALVIN includes four different environments A, B, C, and D, each of which consists of 6 hours of human-teleoperated recording data (more than 2 million trajectories) that might contain sub-optimal behavior, and only 1% of that data is annotated with language instructions (around 24 thousand trajectories). Each split is settled with different settings of objects and environments, aiming to validate the performance, robustness, and generality of policies trained with different data combinations.
CALVIN(Mees等,2022b)是一个用于评估长时序语言条件任务的开源模拟基准。

如图4所示,CALVIN包括四个不同的环境A、B、C和D,每个环境都包含6小时的人类远程操作记录数据(超过200万条轨迹),其中可能包含次优行为,只有1%的数据带有语言说明(约2.4万条轨迹)。每个拆分都采用不同的对象和环境设置,旨在验证使用不同数据组合训练的策略的性能、鲁棒性和通用性。
This benchmark requires a 7-DOF Franka Emika Panda robot arm with a parallel gripper, utilizing onboard sensors and images from two camera views to successfully complete sequences of up to five language instructions consecutively. This setup further challenges the robot’s ability to transition between various goals. CALVIN encompasses a total of 34 distinct tasks and evaluates 1000 unique instruction chains for sequences. The robot is reset to a neutral position after each sequence to prevent any policy bias resulting from its initial pose. This neutral initialization eliminates any correlation between the initial state and the task, compelling the agent to rely solely on language cues to comprehend and solve the given task. The policy for each consecutive task is dependent on the instruction of the current goal, and the agent advances to the subsequent goal only if it successfully
这个基准要求使用具有平行夹爪的7自由度Franka Emika Panda机械臂,利用板载传感器和两个摄像机视图的图像来成功完成最多五个语言说明的任务序列。这个设置进一步挑战了机器人在各种目标之间转换的能力。 CALVIN包含34个不同的任务,评估1000个唯一的指令链,用于序列任务。每个序列后机器人被重置到中性位置,以防止由于其初始姿势而导致的任何策略偏差。这种中性初始化消除了初始状态和任务之间的任何相关性,迫使代理仅依赖于语言提示来理解和解决给定的任务。每个连续任务的策略取决于当前目标的指令,只有在成功完成当前任务后,代理才能进入下一个目标。
A.2 EXAMPLES OF ENRICHED INSTRUCTIONS
A.2 丰富指令的示例
To validate the performance of the policies over diversified language expressions, we utilize ChatGPT to augment the language instruction in CALVIN. We showcase the enriched language instructions in Tab. 4. We can see that the enriched instructions do have the same meaning as the original one, yet they are organized with different words. As shown in Table 1, RoboFlamingo can still achieve better performance compared to HULC.
为了验证策略在多样化的语言表达上的性能,我们使用ChatGPT来增强CALVIN中的语言指令。我们在表4中展示了丰富的语言指令。我们可以看到,丰富的指令与原始指令具有相同的含义,但它们使用不同的词汇组织。正如在表1中所示,RoboFlamingo仍然可以比HULC取得更好的性能。

表4:CALVIN基准测试中原始指令和增强指令的示例
A.3 COMPUTING RESOURCE
A.3 计算资源
All experiments involved in this paper are conducted on a single GPU server with 8 NVIDIA Tesla A100 GPUs.
本文中涉及的所有实验均在一台具有8个NVIDIA Tesla A100 GPU的单个GPU服务器上进行。
B EXTENDED EXPERIMENTAL RESULTS
B 扩展实验结果
B.1 QUALITATIVE EXAMPLES
B.1 定性示例
We visualize the task frames and analyze how RoboFlamingo achieve such a great performance. As the example shown in Fig. 5, where RoboFlamingo successfully finishes the entire task sequence, while HULC stucks at the third one. RoboFlamingo only takes a dozen steps to locate and move to the top of the drawer, and simultaneously releases the gripper to complete the task; while HULC keeps moving above the desktop for hundreds of steps and fails to locate the drawer. Furthermore, although both methods are successful for the first two tasks, RoboFlamingo uses significantly fewer steps. This representative episode vividly illustrates that our method is much more effective and efficient and could better generalize to unseen vision context.
我们可视化任务帧并分析RoboFlamingo如何取得如此出色的性能。如图5所示的示例,RoboFlamingo成功完成了整个任务序列,而HULC在第三个任务中卡住了。RoboFlamingo只需数十步就能定位并移动到抽屉顶部,并同时释放夹爪以完成任务;而HULC在桌面上方移动数百步,无法找到抽屉。此外,尽管两种方法对于前两个任务都成功,但RoboFlamingo使用的步骤显著更少。这个代表性的示例生动地说明了我们的方法更加有效和高效,能够更好地推广到未见的视觉环境。
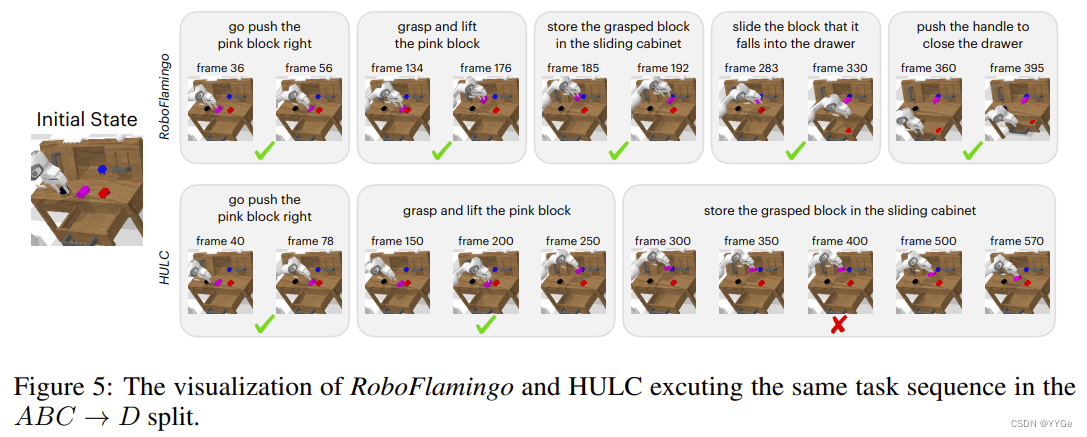
图5:RoboFlamingo和HULC在ABC → D分割中执行相同任务序列的可视化
B.2 EVALUATION CURVES OF DIFFERENT BACKBONES
B.2 不同VLM骨干的评估曲线
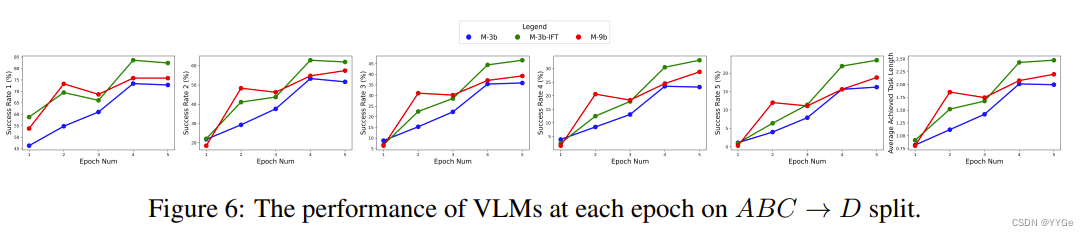
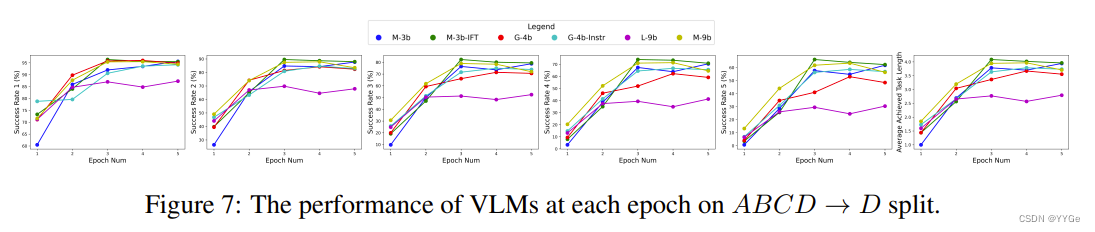
As shown in Fig. 6 and Fig. 7, we further train RoboFlamingo with the different VLMs on both ABC → D and ABCD → D split with 5 epochs, and evaluate their performances at each epoch. We can see that most variants converge in 5-epoch training and achieve high performance, benefiting from the pretraining on extensive vision-language tasks.
如图6和图7所示,我们在ABC → D和ABCD → D拆分上使用不同的VLM对RoboFlamingo进行了5个epoch的训练,并在每个epoch评估它们的性能。我们可以看到,大多数变体在5个epoch的训练中收敛并取得了高性能,这得益于在广泛的视觉语言任务上的预训练。
B.3 DETAILED IMITATION PERFORMANCES ON EACH TASK
B.3 每个任务的详细模仿性能
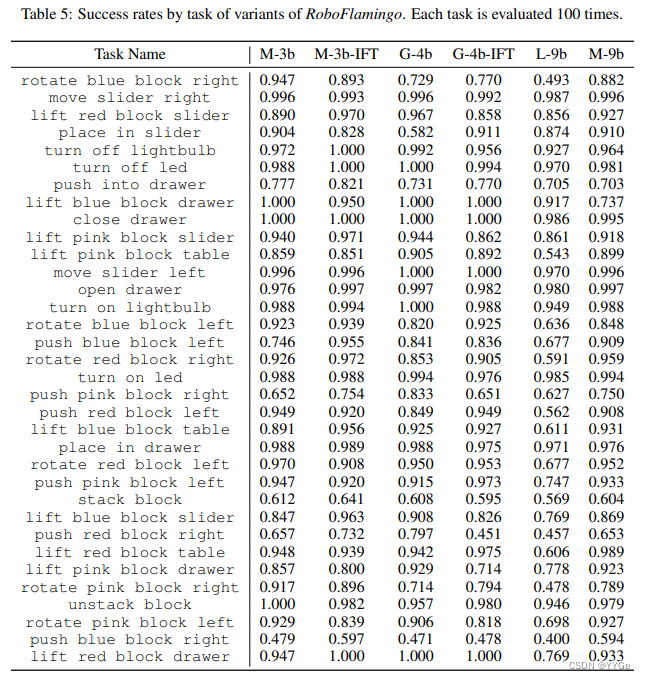
We present the detailed imitation performances by tasks in Tab. 5. All model are reported by their best checkpoint.
我们在表5中按任务呈现了详细的模仿性能。所有模型都报告了它们的最佳检查点。
B.4 ROLLOUT EXAMPLES
B.4 展开示例
We present some rollout examples of RoboFlamingo on the ABCD → D split.
我们展示了RoboFlamingo在ABCD → D分拆上的一些展开

























![[Python进阶] 正则表达式的验证](https://img-blog.csdnimg.cn/direct/37279c61d41d4da792dd8ee0c7311a72.png)