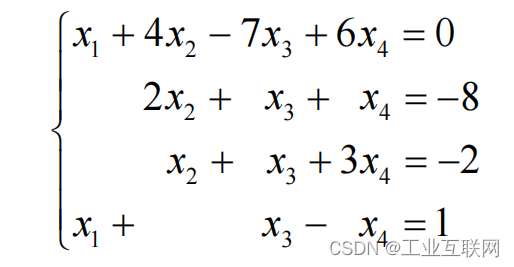Vision Transformer with Deformable Attention
多头自注意力公式化为:

第l层transformer模块公式化为:

在Transformer模型中简单地实现DCN是一个non-trivial的问题。在DCN中,特征图上的每个元素都单独学习其偏移,其中H×W×C特征图上3×3可变形卷积的空间复杂度为9HW C。如果我们在注意力模块中直接应用相同的机制,空间复杂度将急剧上升到NqNkC,其中Nq,Nk是查询和密钥的数量,通常具有与特征图大小HW相同的比例,带来近似双二次复杂度。尽管Deformable DETR已经通过在每个尺度上设置较低数量的密钥(Nk=4)来减少这种开销,并且作为检测头工作得很好,但由于信息的不可接受的丢失,在骨干网络中处理如此少的密钥是不好的(见附录中的详细比较)。同时,不同的查询在视觉注意力模型中具有相似的注意力图。因此,我们选择了一种更简单的解决方案,为每个查询共享移位的键和值,以实现有效的权衡。
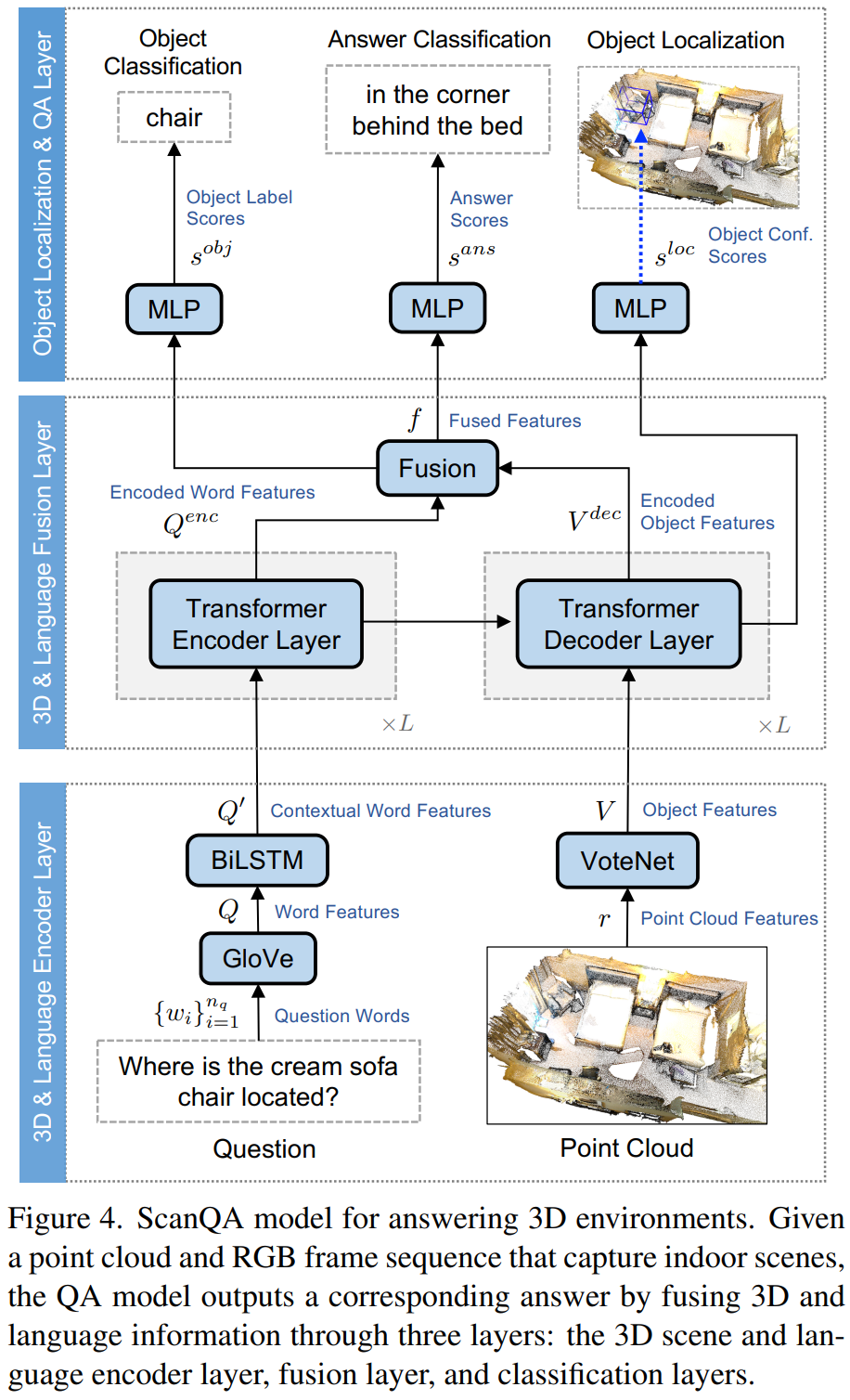
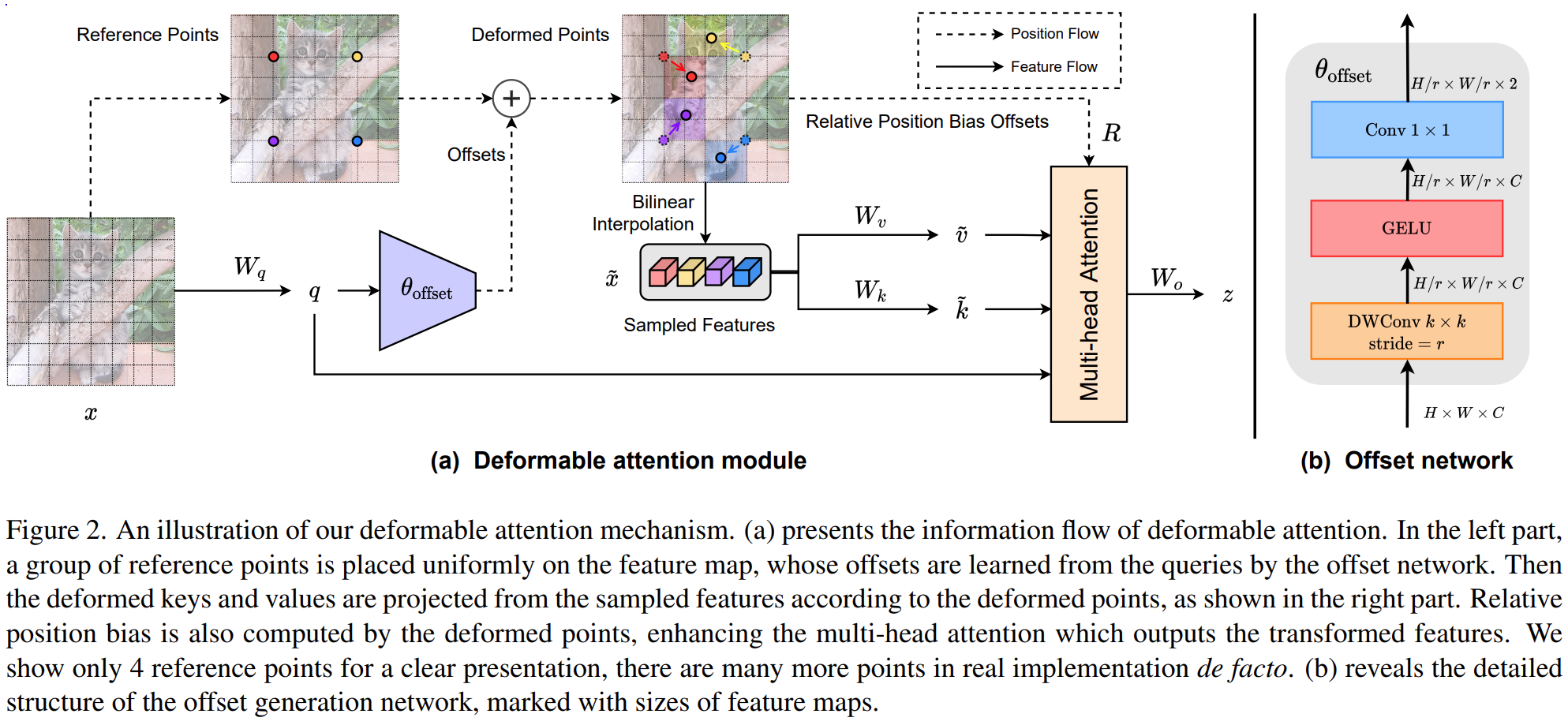
我们提出了可变形注意力,以在特征图中重要区域的指导下有效地对tokens之间的关系进行建模。这些聚焦区域由偏移网络从查询中学习的多组变形采样点确定。采用双线性插值得到采用特征,然后这些采样特征映射为可变形keys and values。然后使用MHSA。可变形点也提供了相对位置偏差。
如图,给一个特征图![]() ,给一个均匀网格
,给一个均匀网格![]() 作为references,网格大小从输入特征图大小向下采样因子r,
作为references,网格大小从输入特征图大小向下采样因子r,![]()
![]() ,然后把这个网格的位置值归一化到(-1,-1),(+1,+1)。通过offset网络得到网格每个位置的偏移量,然后,在变形点的位置对特征进行采样,作为关键点和值,再进行映射:
,然后把这个网格的位置值归一化到(-1,-1),(+1,+1)。通过offset网络得到网格每个位置的偏移量,然后,在变形点的位置对特征进行采样,作为关键点和值,再进行映射:

![]() ,
,![]() ,s是为了训练稳定。
,s是为了训练稳定。![]() 是使用双线性插值的采样函数。
是使用双线性插值的采样函数。

在q,k,v上使用多头注意力和相对位置偏移。
每个参考点覆盖一个局部s×s区域(s是偏移的最大值),偏移生成网络也应该具有对局部特征的感知,以学习合理的偏移。因此,我们将子网络简化为具有非线性激活的两个卷积模块,如图2(b)所示。输入特征首先通过5×5深度卷积来捕获局部特征。然后,采用GELU激活和1×1卷积来获得2D偏移。还值得注意的是,1×1卷积中的偏差被降低,以减轻所有位置的强制偏移。
为了促进变形点的多样性,我们在MHSA中遵循类似的范式,并将特征通道划分为G组。来自每组的特征使用共享子网络来分别生成相应的偏移。在实践中,注意力模块的头数M被设置为偏移组G的大小的倍数,从而确保多个注意力头被分配给一组变形的键和值。

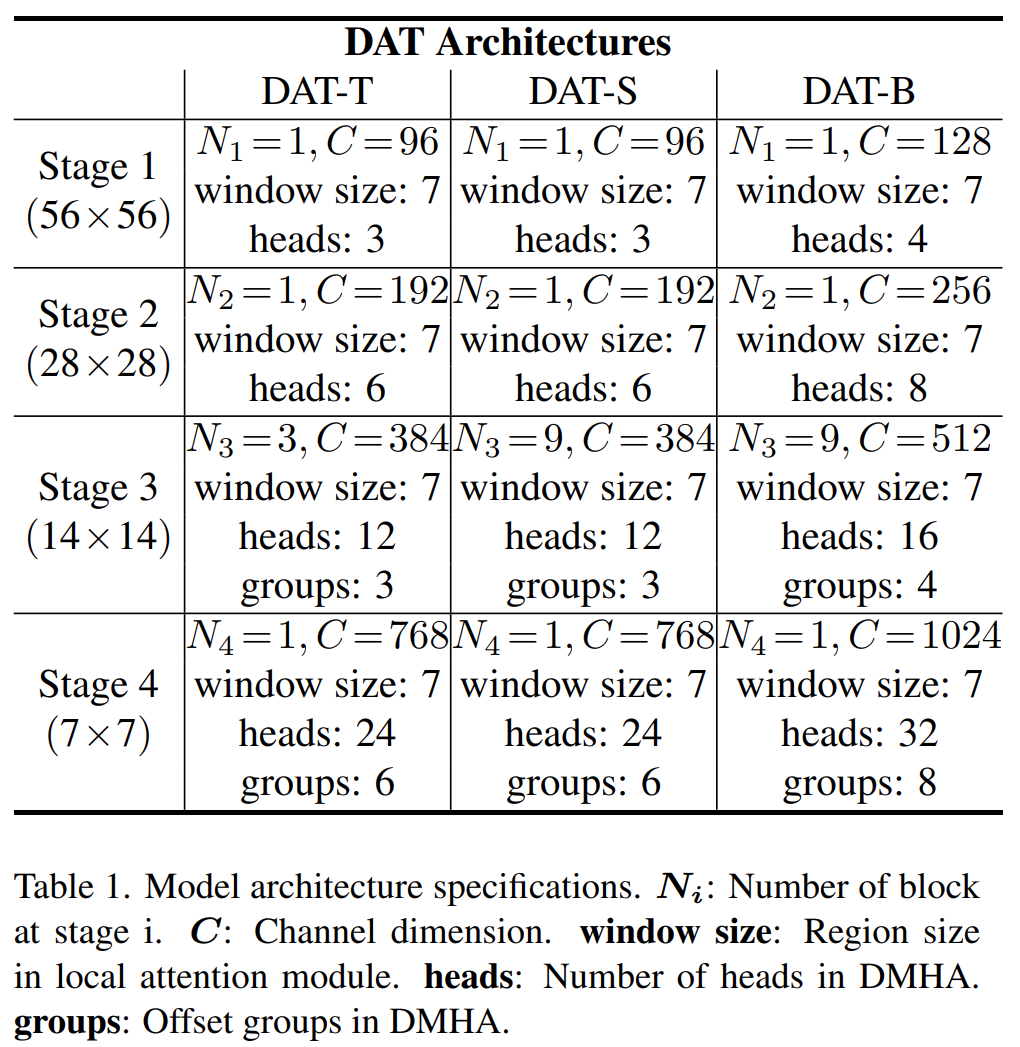

补充资料:
DAT and Deformable DETR区别
首先,我们的可变形注意力充当视觉主干中的特征提取器,而可变形DETR中的可变形注意扮演检测头的角色,它用线性可变形注意取代了DETR中的普通注意。其次,在具有单尺度的可变形DETR中,查询q的第m个头被公式化为:
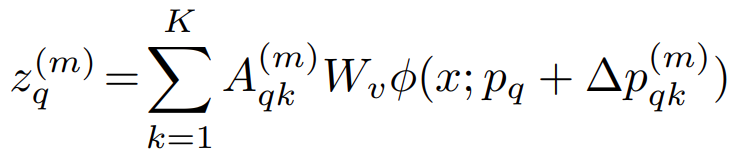
其中从输入特征中采样K个关键点,通过![]() 进行映射,然后通过注意力权重
进行映射,然后通过注意力权重![]() 进行聚合。与我们的可变形注意力(Eq.(9)在本文中)相比,该注意力权重是通过线性投影从
进行聚合。与我们的可变形注意力(Eq.(9)在本文中)相比,该注意力权重是通过线性投影从![]() 学习的,即
学习的,即![]() ,其中
,其中![]() 是预测每个头部上每个键的权重的权重矩阵,之后将softmax函数σ应用于K个键的维度以归一化注意力得分。事实上,注意力权重是通过查询直接预测的,而不是测量查询和关键字之间的相似性。如果我们将σ函数更改为sigmoid,这将是调制可变形卷积的变体[53],因此这种可变形注意力更类似于卷积,而不是注意力。
是预测每个头部上每个键的权重的权重矩阵,之后将softmax函数σ应用于K个键的维度以归一化注意力得分。事实上,注意力权重是通过查询直接预测的,而不是测量查询和关键字之间的相似性。如果我们将σ函数更改为sigmoid,这将是调制可变形卷积的变体[53],因此这种可变形注意力更类似于卷积,而不是注意力。
第三,可变形DETR中的可变形注意力与本文第3.2节中提到的点积注意力不兼容,因为它消耗了巨大的内存。因此,使用线性预测注意力来避免计算点积,并且还采用较小数量的密钥K=4来降低存储器成本。
为了通过实验验证我们的说法,我们用[54]中的模块替换了DAT中的可变形注意力模块,以验证初始适应对视觉主干的影响较小。比较结果如表8所示。比较第一行和最后一行,我们可以看到,在较小的内存预算下,可变形DETR模型的密钥数量设置为16,以减少内存老化,并实现1.4%的性能降低。通过比较第三行和最后一行,我们可以看到,与DAT具有相同密钥数量的D-DETR注意力消耗2.6×内存和1.3×FLOP,但性能仍低于DAT。
更多可视化结果

在图6中,采样点被描绘在对象检测框和实例分割掩码的顶部,从中我们可以看到这些点被移动到目标对象。在左列中,变形的点收缩为两个目标长颈鹿,而其他点则保持几乎均匀的网格,偏移较小。在中间列上,变形点在两个阶段都密集分布在人体和冲浪板之间。右栏显示了六个甜甜圈中每个甜甜圈的变形点,这表明我们的模型即使有多个目标,也能够更好地模拟几何形状。上述可视化结果表明,DAT学习有意义的偏移量,以采样更好的关键点,从而提高各种视觉任务的性能。
我们还提供了给定特定查询令牌的注意力图的可视化结果,并与图7中的Swin-Trans-former[26]进行了比较。我们展示具有最高关注值的关键令牌。可以观察到,我们的模型侧重于更相关的部分。作为展示,我们的模型将大部分注意力集中在前景对象上,例如,第一排的两个长颈鹿。另一方面,Swin Transformer中的兴趣区域相当局部,无法区分前景和背景,这在最后一块冲浪板中有所描述。




![[<span style='color:red;'>论文</span><span style='color:red;'>阅读</span>]DETR](https://img-blog.csdnimg.cn/direct/e8df1ed8695749d1b661ff6ad6833838.png)
![[<span style='color:red;'>论文</span><span style='color:red;'>阅读</span>]BEVFusion](https://img-blog.csdnimg.cn/direct/65697d2df3dc47d2a67baf3c2e53c330.png)