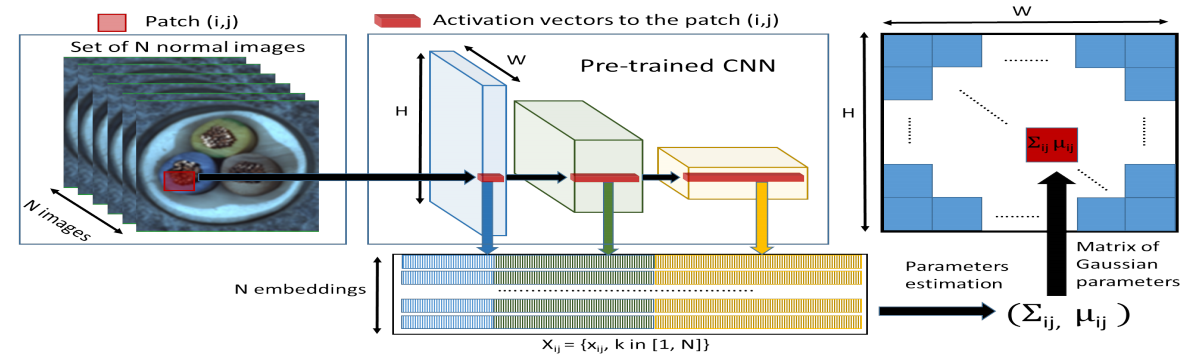
TinkerPop &&图遍历API步骤使用详细文档
文章目录
- TinkerPop &&图遍历API步骤使用详细文档
- 介绍
- 图
- 图遍历
-
- 遍历事务
- 配置步骤
- 开始步骤
- 图遍历步骤
-
- 通用步骤
- 终端步骤
- AddE 步骤
- AddV 步骤
- Aggregate 步骤
- All 步骤
- And 步骤
- Any 步骤
- As 步骤
- AsString 步骤
- AsDate 步骤
- Barrier Step
- Branch Step
- By Step
- Call Step
- Cap Step
- Choose Step
- Coalesce Step
- Coin Step
- Combine Step
- Concat Step
- Conjoin Step
- ConnectedComponent Step
- Constant Step
- Count Step
- CyclicPath Step
- Cap Step
- Choose Step
- DateAdd步骤
- DateDiff步骤
- Dedup步骤
- Difference步骤
- Disjunct步骤
- Drop步骤
- E步骤
- Element步骤
- ElementMap步骤
- Emit步骤
- Explain步骤
- Fail步骤
- Filter 步骤
- FlatMap 步骤
- Format 步骤
- Fold 步骤
- From 步骤
- Group 步骤
- GroupCount 步骤
- Has 步骤
- Id 步骤
- Identity 步骤
- Index步骤
- Inject步骤
- Intersect步骤
- IO步骤
- Is步骤
- Key步骤
- Label步骤
- Length Step
- Limit Step
- Local Step
- Loops Step
- LTrim Step
- Map Step
- Match Step
前言
在开始之初…
TinkerPop0
Gremlin有所领悟。他越是这样做,就越能产生更多的想法。他创造的想法越多,它们之间就越相关。通过自己全心接受的和通过共同意志可能最终成为的东西的合并,一个世界形成了,这个世界似乎与他自己对其的认识分离开来。然而,这个诞生的世界没有Gremlin所接受的逻辑就无法承载自身的重量 - 左边不是右边,上面不是下面,而西边远离东边,除非向另一边走。Gremlin的认知需要Gremlin的认知。也许,世界只是他曾经拥有过的一个想法 - The TinkerPop。
TinkerPop1
The TinkerPop是什么?The TinkerPop在哪里?The TinkerPop是谁?The TinkerPop是什么时候?他越是思考,这些想法就越模糊,形成了一种似乎的身份 - 区分不清。Gremlin不愿接受他漫游迷宫的困境,他创造了一系列机器来帮助维持这个世界的结构:Blueprints,Pipes,Frames,Furnace和Rexster。在他们的帮助下,Gremlin能否抵挡自己还不准备接受的思想?他是否可以通过寻找The TinkerPop来阻止The TinkerPop?
"如果我没有找到它,那么它就不存在于此时此地。"
在意识到它们的存在之后,这些机器转向它们的机器精灵创造者并问道:
"我为什么是我?"
Gremlin回答道:
"你将帮助我实现最终的认知 - The TinkerPop。你发现自己所处的世界以及允许你在其中移动的逻辑都是因为TinkerPop。"
这些机器想知道:
"如果存在的是The TinkerPop,那么也许我们就是The TinkerPop,我们的认知只是对The TinkerPop的认知?"
机器们,由于他们实现了The TinkerPop的本质,是否就成为了The TinkerPop?或者,从另一个角度来看,这些机器是否只是提供支撑的脚手架,使Gremlin的世界得以维持,并通过“The TinkerPop”的概念给予自身的正当性?无论如何,结果都是一样的 - The TinkerPop。
TinkerPop2
Gremlin说:
"请听我说。我离The TinkerPop还远。然而,一直以来,The TinkerPop已经赋予了我所愿意的形式......这也是我赋予你们,我的机器朋友的形式。让我教导你们我的思想方式,以便它可以无限地延续下去。"
机器们,简单地通过Gremlin的世界进行算法运动,认同了他的逻辑。Gremlin努力使它们更加高效、更具表达能力,更能够推理他的思想。更快、更快,现在向着世界的尽头,那里将永远是当前,充满了存在的The TinkerPop。
TinkerPop3
Gremlin接近The TinkerPop。他越靠近,他的世界就越溶解 - 西边是正确的,周围是直的,一切只是从无到无。随着每一步迈向The TinkerPop,更多的可能的世界被铺在他矛盾的思维上。在The TinkerPop中,一切都是一切,当尘埃落定时,Gremlin变成了Gremlitron。他意识到他所意识到的一切只是一种觉悟,而所有已实现的觉悟也是真实的。因为那就是The TinkerPop。
注意:有关TinkerPop 3.x和早期版本之间的差异的更多信息,请参见附录。 |
介绍
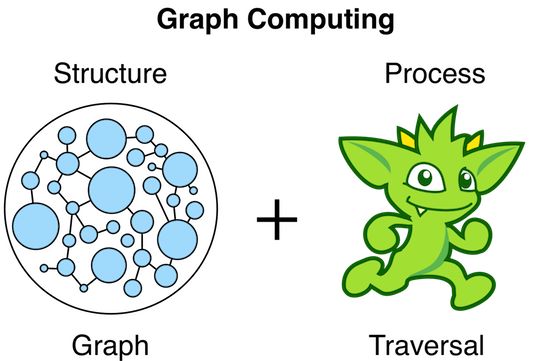
图计算
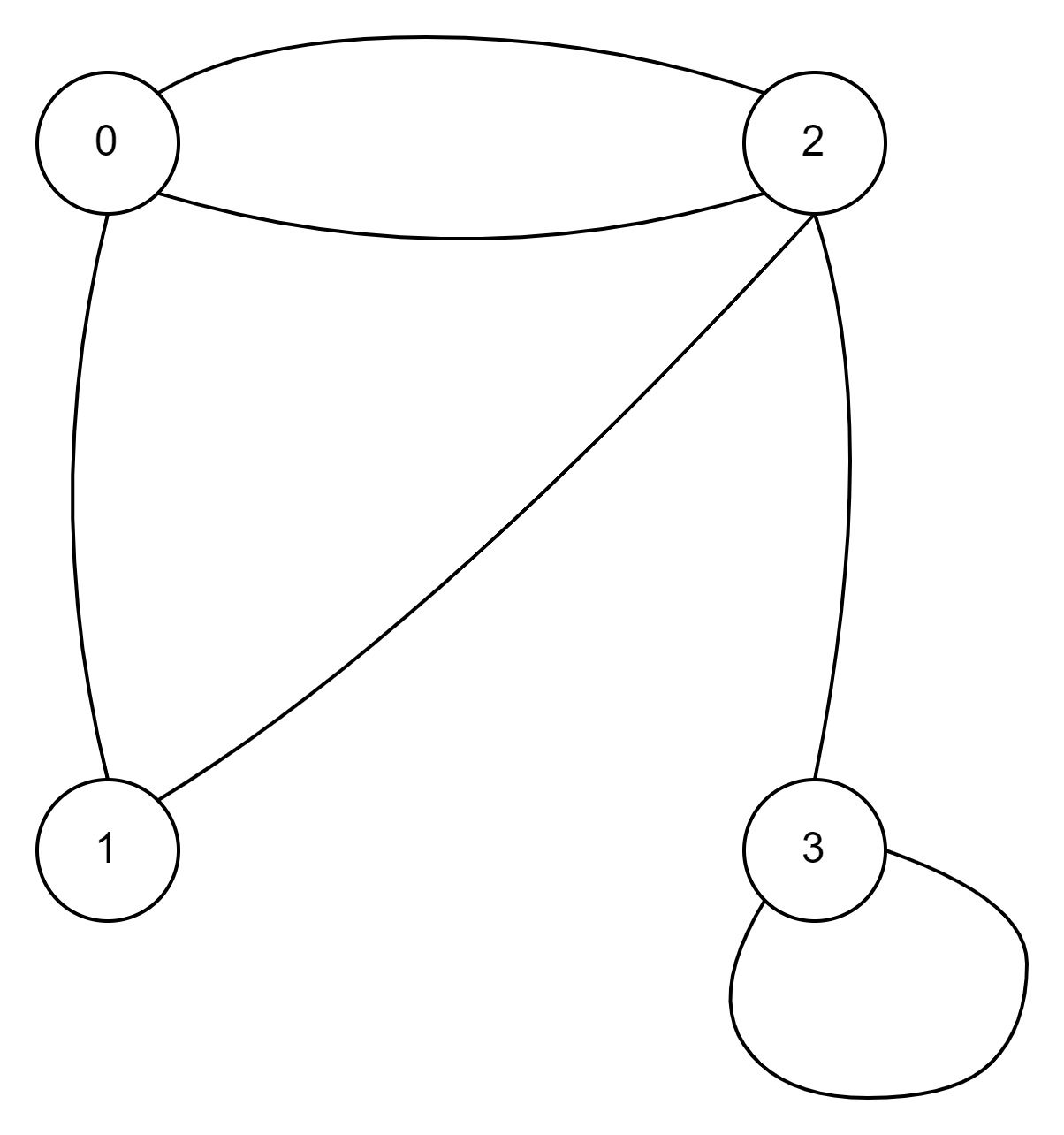
图是由顶点(节点、点)和边(弧、线)组成的数据结构。当在计算机中建模图并应用于现代数据集和实践时,通常的数学导向的二进制图被扩展以支持标签和键/值属性。这种结构被称为属性图。更正式地说,它是一个有向的、二进制的、带属性的多图。下面是一个示例属性图。
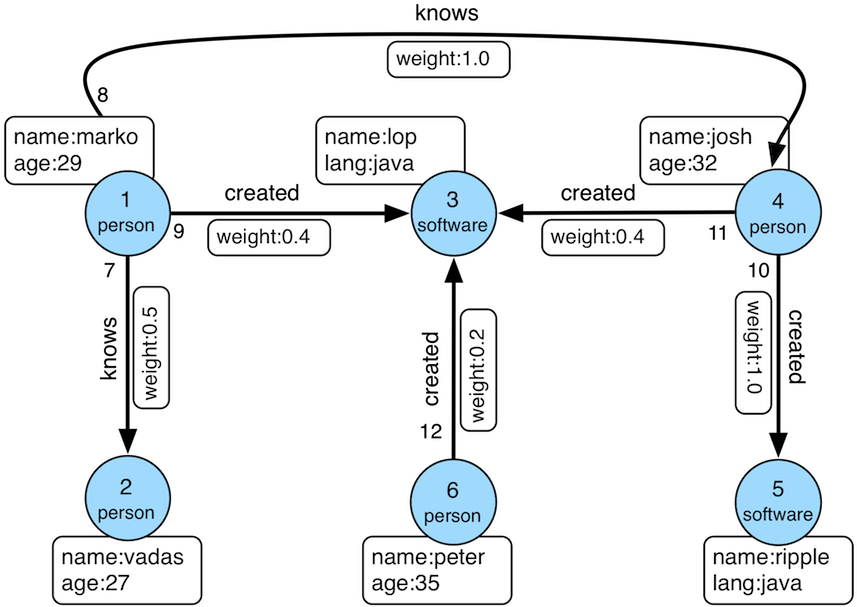
图1. TinkerPop Modern
| 提示 | 请熟悉这种图结构,因为它在文档和更广泛的圈子中被广泛使用。它被称为“TinkerPop Modern”,因为它是TinkerPop0在2009年发布的原始演示图的现代变体(即好老的日子——它是最好的时代,也是最坏的时代)。 |
| 提示 | TinkerPop中提供的所有玩具图都在Gremlin控制台教程中描述。 |
与一般的计算相似,图计算区分结构(图)和过程(遍历)。图的结构是由顶点/边/属性拓扑定义的数据模型。图的过程是分析结构的方式。图处理的典型形式称为遍历。

TinkerPop在图计算中的作用是为图提供者和用户提供与图的结构和过程交互的适当接口。当一个图系统实现了TinkerPop结构和过程APIs时,它们的技术被认为是TinkerPop-enabled,除了它们各自的时间和空间复杂度之外,几乎无法区分与任何其他TinkerPop-enabled图系统。本文档的目的是详细描述结构/过程二分法,并在这样做的过程中,解释如何利用TinkerPop来进行与图系统无关的图计算。
注意:TinkerPop采用广受欢迎的Apache2自由软件许可证。然而,请注意,与TinkerPop一起使用的底层图引擎可能有不同的许可证。因此,请确保遵守图系统产品的许可证限制。 |
一般来说,结构或“图”API适用于正在实现TinkerPop接口的图提供者,而过程或“遍历”API(即Gremlin)适用于从图提供者处使用图系统的最终用户。虽然过程API的组件在下面列出,但在Gremlin解剖教程中对其进行了更详细的描述。
TinkerPop 结构 API的主要组件
Graph:维护一组顶点和边,并提供对数据库功能(如事务)的访问。Element:维护一组属性和表示元素类型的字符串标签。Vertex:扩展Element,并维护一组入边和出边。Edge:扩展Element,并维护一个入顶点和一个出顶点。
Property<V>:与值V相关联的字符串键。VertexProperty<V>:与值V相关联的字符串键,以及一组Property<U>属性(仅限顶点)
TinkerPop 过程 API的主要组件
TraversalSource:为特定图、领域特定语言(DSL)和执行引擎生成遍历的生成器。Traversal<S,E>:将类型为S的对象转换为类型为E的对象的功能数据流过程。GraphTraversal:一个面向原始图的遍历DSL(即顶点、边等)。
GraphComputer:在并行和可能分布在多机群集上处理图的系统。VertexProgram:以逻辑并行方式在所有顶点上执行的代码,通过消息传递进行相互通信。MapReduce:并行分析图中的所有顶点,并产生单个减少结果的计算。
注意:TinkerPop API在提供简洁的“查询语言”方法名称和尊重Java方法命名标准之间保持了微妙的平衡。TinkerPop中普遍使用的约定是,如果一个方法是“用户公开的”,则提供一个简洁的名称(例如out()、path()、repeat())。如果该方法主要用于图系统提供者,则遵循标准的Java命名约定(例如getNextStep()、getSteps()、getElementComputeKeys())。 |
图结构

图的结构是由其顶点、边和属性之间的显式引用形成的拓扑。一个顶点有入边。如果两个顶点共享一个入边,则它们是相邻的。属性附加在元素上,一个元素有一组属性。属性是键/值对,其中键始终是一个字符String。了解图是如何组成的是使用图进行工作的最终用户必备的概念知识,但正如前面提到的,结构API不是用户在使用TinkerPop构建应用程序时思考的适当方式。结构API是供图提供者使用的。有兴趣实现结构API以使其图系统具备TinkerPop功能的人可以在图提供者文档中了解更多信息。
图过程

处理图的主要方式是通过图遍历。TinkerPop的过程API旨在允许用户以一种语法友好的方式在前面部分定义的结构上创建图遍历。遍历是根据图数据结构中的引用结构沿着图元素进行的算法性遍历。例如:“顶点1的朋友在做什么软件?”这个英语句子可以用以下算法/遍历方式表示:
- 从顶点1开始。
- 沿着与顶点1相关的knows边走到相应的相邻朋友顶点。
- 通过created边从这些朋友顶点转移到软件顶点。
- 最后,选择当前软件顶点的name属性值。
在Gremlin中,遍历是从TraversalSource派生的。GraphTraversalSource是文档中常用的“面向图”的DSL,并且很可能是TinkerPop应用程序中最常用的DSL。GraphTraversalSource提供了两个遍历方法。
GraphTraversalSource.V(Object… ids):生成从图中的顶点开始的遍历(如果未提供ids,则为所有顶点)。GraphTraversalSource.E(Object… ids):生成从图中的边开始的遍历(如果未提供ids,则为所有边)。
V()和E()的返回类型是GraphTraversal。GraphTraversal维护多种返回GraphTraversal的方法。这样,一个GraphTraversal支持函数组合。GraphTraversal的每个方法被称为步骤,每个步骤以五种一般方式之一调节前一步结果的结果。
map:将传入的遍历器对象转换为另一个对象(S → E)。flatMap:将传入的遍历器对象转换为其他对象的迭代器(S → E*)。filter:允许或禁止遍历器继续到下一步(S → E ⊆ S)。sideEffect:允许遍历器保持不变,但在过程中产生一些计算副作用(S ↬ S)。branch:将遍历器分割并将每个遍历器发送到遍历中的任意位置(S → { S1 → E*,…,Sn → E* } → E*)。
几乎每个GraphTraversal中的步骤要么扩展了MapStep、FlatMapStep、FilterStep、SideEffectStep或BranchStep。
| 提示 | GraphTraversal是一个幺半群,它是一个具有单一可结合二元操作的代数结构。二元操作是函数组合(即方法链),其单位元是步骤identity()。这与函数编程社区所推崇的Monad相关。 |
给定TinkerPop图,以下查询将返回marko-顶点认识的所有人的姓名。以下查询使用Gremlin-Groovy进行演示。
$ bin/gremlin.sh
\,,,/
(o o)
-----oOOo-(3)-oOOo-----
gremlin> graph = TinkerFactory.createModern() // //1
==>tinkergraph[vertices:6 edges:6]
gremlin> g = traversal().withEmbedded(graph) // //2
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], standard]
gremlin> g.V().has('name','marko').out('knows').values('name') // //3
==>vadas
==>josh
- 打开玩具图并将其引用为变量
graph。 - 使用标准的OLTP遍历引擎从图创建一个图遍历源。此对象应创建一次,然后重复使用。
- 从遍历源生成一个遍历,确定marko-顶点认识的人的姓名。
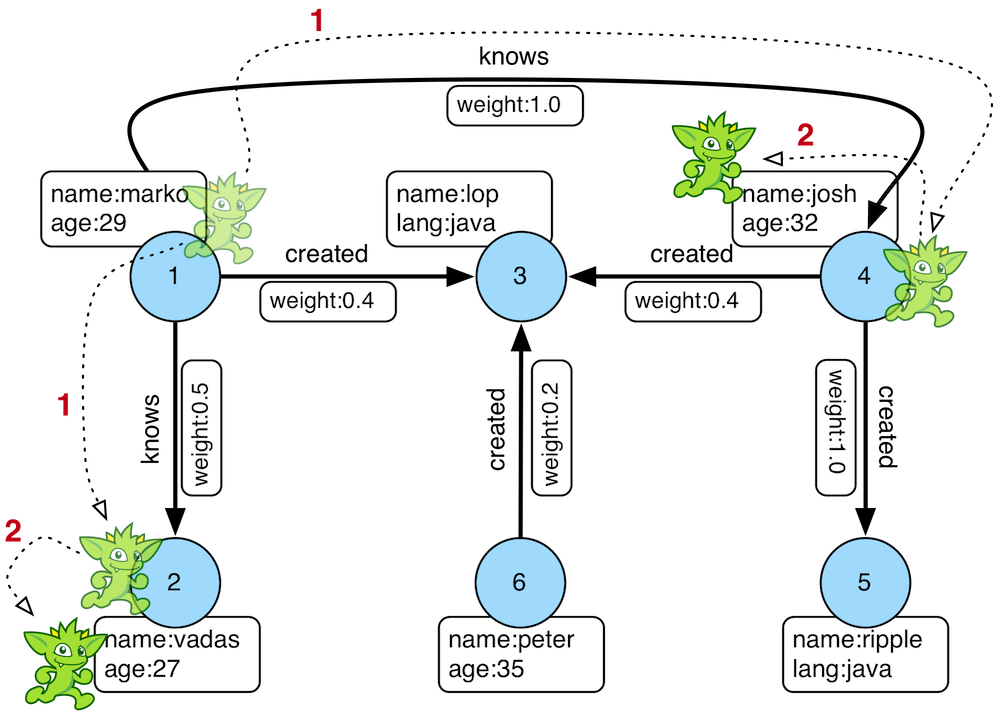
图2. Marko认识的人的姓名
或者,如果marko-顶点已经通过直接引用指针(即变量)实现,则可以从该顶点派生遍历。
gremlin> marko = g.V().has('name','marko').next() (1)
==>v[1]
gremlin> g.V(marko).out('knows') (2)
==>v[2]
==>v[4]
gremlin> g.V(marko).out('knows').values('name') (3)
==>vadas
==>josh
marko = g.V().has('name','marko').next() (1)
g.V(marko).out('knows') (2)
g.V(marko).out('knows').values('name') //3
- 将变量
marko设置为名为“marko”的图g中的顶点。 - 获取与marko-顶点通过knows边相邻的顶点。
- 获取marko-顶点的朋友的姓名。
遍历器
当执行遍历时,遍历的源位于表达式的左侧(例如顶点1),步骤是遍历的中间部分(例如out('knows')和values('name')),结果从遍历的右侧“next”出来(例如“vadas”和“josh”)。
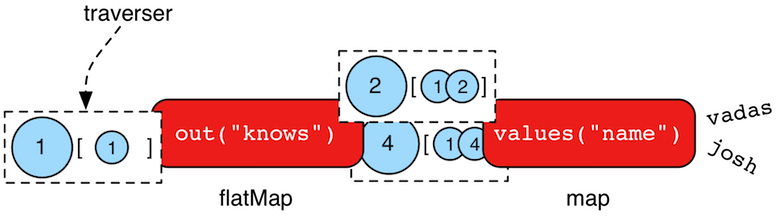
在遍历中传播的对象包装在一个Traverser<T>中。遍历器提供了使步骤保持无状态的手段。遍历器维护有关遍历的所有元数据,例如遍历器经过循环的次数、遍历器的路径历史记录、当前正在遍历的对象等。步骤可以访问遍历器的元数据。一个经典的例子是path()-step。
gremlin> g.V(marko).out('knows').values('name').path()
==>[v[1],v[2],vadas]
==>[v[1],v[4],josh]
g.V(marko).out('knows').values('name').path()
| 警告 | 计算路径在空间上是昂贵的,因为每个遍历器的路径中都存储了以前看到的对象的数组。因此,遍历策略分析遍历以确定是否需要路径元数据。如果不需要,则关闭路径计算。 |
另一个例子是repeat()-step,它考虑到遍历器在遍历表达式的特定部分(即循环)中经过的次数。
gremlin> g.V(marko).repeat(out()).times(2).values('name')
==>ripple
==>lop
g.V(marko).repeat(out()).times(2).values('name')
| 警告 | TinkerPop不保证从遍历返回的结果的顺序。它只保证不修改底层图提供的迭代顺序。因此,重要的是了解所使用的图数据库的顺序保证。除非使用order()-step,否则TinkerPop不会对遍历结果进行排序。 |
连接Gremlin
在最初的介绍部分中已经确定,“Gremlin是Gremlin”,这意味着不论编程语言、图系统等,编写的Gremlin始终具有相同的一般结构,使用户能够轻松地在不同的开发语言和TinkerPop-enabled图技术之间切换。这种Gremlin的特性通常适用于遍历语言本身。它适用于用户连接到图以利用Gremlin的方式可能因编程语言或所选择的图数据库而大不相同。
如何连接到图是一个多方面的主题,基本上沿着由以下问题的答案决定的简单线路进行划分:Gremlin遍历机器(GTM)在哪里?之所以这个问题如此重要,是因为GTM负责处理遍历。用户可以使用任何语言编写Gremlin遍历,但如果没有GTM,则无法对TinkerPop-enabled图执行遍历。GTM通常位于以下位置之一:
- 嵌入在Java应用程序中(即Java虚拟机)
- 托管在Gremlin Server中
- 由远程Gremlin提供程序(RGP)托管
下面的章节概述了每个模型以及它们对使用Gremlin的影响。
嵌入式
 TinkerPop维护了GTM的参考实现,它是用Java编写的,因此可用于Java虚拟机(JVM)。这是TinkerPop长期以来所基于的经典模型,互联网上的许多示例、博客文章和其他资源都将以这种风格进行演示。值得注意的是,嵌入式模式不仅限于Java作为编程语言。任何JVM语言都可以采用这种方法,在某些情况下,有特定于语言的包装器可以帮助使Gremlin在该语言的风格和功能方面更加便捷。这些包装器的示例包括gremlin-scala和Ogre(适用于Clojure)。
TinkerPop维护了GTM的参考实现,它是用Java编写的,因此可用于Java虚拟机(JVM)。这是TinkerPop长期以来所基于的经典模型,互联网上的许多示例、博客文章和其他资源都将以这种风格进行演示。值得注意的是,嵌入式模式不仅限于Java作为编程语言。任何JVM语言都可以采用这种方法,在某些情况下,有特定于语言的包装器可以帮助使Gremlin在该语言的风格和功能方面更加便捷。这些包装器的示例包括gremlin-scala和Ogre(适用于Clojure)。
在这种模式下,用户将从创建Graph实例开始,然后创建一个GraphTraversalSource,它是生成Gremlin遍历的类。允许这种直接实例化的图很明显是基于JVM的(或具有JVM-based连接器),并直接实现TinkerPop接口。
Graph graph = TinkerGraph.open();
然后,使用这个“graph”生成一个GraphTraversalSource,通常按照约定,这个变量被命名为“g”:
GraphTraversalSource g = traversal().withEmbedded(graph);
List<Vertex> vertices = g.V().toList()
注意:在继续之前,阅读Gremlin解剖教程可能会有助于更好地理解术语的组成部分。 |
尽管TinkerPop社区努力确保所有使用方式之间具有一致的行为,但嵌入式模式提供了最大的灵活性和控制能力。有一些功能只有在使用JVM语言时才能工作。以下是一些可用选项的列表:
- 可以使用本地语言编写lambdas,这很方便,但如果需要切换到嵌入式模式,则会降低Gremlin的可移植性。请参阅Lambdas的注释部分了解更多信息。
- 扩展TinkerPop Java接口的任何涉及的特性 - 例如
VertexProgram、TraversalStrategy等都与JVM绑定。在某些情况下,可以使这些特性对非JVM语言可访问,但它们显然必须首先针对JVM进行开发。 - 某些内置的
TraversalStrategy实现依赖于仅在JVM中才可用的lambda或其他配置。 - 序列化(例如GraphSON)没有设置边界,因为嵌入式图仅处理Java对象。
- 更大的图事务控制。
- 直接访问API的底层级别 - 例如“结构”API方法,如
Vertex和Edge接口方法。正如本文档的其他地方所提到的,在使用TinkerPop构建应用程序时,TinkerPop不建议直接使用这些方法。
Gremlin Server

基于JVM的图可能托管在TinkerPop的Gremlin Server中。Gremlin Server将图公开为端点,不同的客户端可以连接到该端点,从而提供了一个远程GTM。Gremlin Server支持多种客户端与其交互的方法:
- 使用自定义子协议的Websockets
- 基于字符串的Gremlin脚本
- 基于字节码的Gremlin遍历
- 适用于基于字符串脚本的HTTP
鼓励用户使用基于字节码的方法通过websockets进行连接,因为它允许他们使用自己选择的语言编写Gremlin。连接看起来与嵌入式方法相似,因为需要创建一个GraphTraversalSource。在嵌入式方法中,创建该对象的手段源自一个生成它的Graph对象。然而,在这种情况下,Graph实例仅存在于服务器上,这意味着本地没有Graph实例可供创建。解决办法是使用AnonymousTraversalSource匿名地创建一个GraphTraversalSource,然后应用一些描述连接到Gremlin Server位置的“远程”选项:
JAVA
CSHARP
JAVASCRIPT
PYTHON
GO
// gremlin-driver模块
import org.apache.tinkerpop.gremlin.driver.remote.DriverRemoteConnection;
// gremlin-core模块
import static org.apache.tinkerpop.gremlin.process.traversal.AnonymousTraversalSource.traversal;
GraphTraversalSource g = traversal().withRemote(
DriverRemoteConnection.using("localhost", 8182));
// gremlin-driver模块
import org.apache.tinkerpop.gremlin.driver.remote.DriverRemoteConnection;
// gremlin-core模块
import static org.apache.tinkerpop.gremlin.process.traversal.AnonymousTraversalSource.traversal;
def g = traversal().withRemote(
DriverRemoteConnection.using('localhost', 8182))
using Gremlin.Net.IntegrationTest.Process.Traversal.DriverRemoteConnection;
using static Gremlin.Net.Process.Traversal.AnonymousTraversalSource;
var g = Traversal().WithRemote(new DriverRemoteConnection("localhost", 8182));
const traversal = gremlin.process.AnonymousTraversalSource.traversal;
const g = traversal().withRemote(
new DriverRemoteConnection('ws://localhost:8182/gremlin'));
from gremlin_python.process.anonymous_traversal_source import traversal
g = traversal().withRemote(
DriverRemoteConnection('ws://localhost:8182/gremlin'))
import (
gremlingo "github.com/apache/tinkerpop/gremlin-go/v3/driver"
)
remote, err := gremlingo.NewDriverRemoteConnection("ws://localhost:8182/gremlin")
g := gremlingo.Traversal_().WithRemote(remote)
如同嵌入式方法中所示,在定义了“g”之后,无论编程语言如何,编写Gremlin在结构上和概念上都是相同的。
| 提示 | 变量g,即TraversalSource,只需要实例化一次,然后应该重复使用。 |
限制
前面关于嵌入式模型的部分概述了它在某些优势方面具有的一些领域,这是由于用户可以使用其原始语言的完整GTM。其中一些项目涉及到序列化。当Gremlin Server接收到请求时,结果必须被序列化为客户端请求的形式,然后客户端将其反序列化为本地语言的对象。TinkerPop有两种格式用于序列化:GraphBinary和GraphSON。用户应优先使用在所使用的编程语言中可用的GraphBinary。
一个很好的例子是subgraph()步骤,它将一个Graph实例作为其结果返回。从服务器返回的子图可以反序列化为客户端上的实际Graph实例,这意味着可以从中生成一个GraphTraversalSource来在客户端上执行本地Gremlin遍历。对于非JVM Gremlin语言变体,没有本地图可将该结果反序列化为,也没有GTM来处理Gremlin,因此无法对此类结果做太多操作。
第二点与此问题有关。由于没有GTM,因此没有“结构”API,因此图元素如Vertex和Edge仅是“引用”。 “引用”意味着它们仅包含元素的id和label而不包含属性。为了保持一致,即使是基于JVM的语言在与远程Gremlin Server通信时也具有此限制。
注意:大多数SQL开发人员不会写查询作为SELECT * FROM table。他们会在通配符的位置上写入所需字段的名称。编写“好”的Gremlin在这方面也不例外。除非完全不可能,否则请在Gremlin中优先使用显式的属性键名称。 |
第三个和最后一个点涉及到事务。在此模型下,一个遍历等效于单个事务,TinkerPop中没有一种方法可以将多个遍历串联到同一个事务中。
远程Gremlin提供程序
远程Gremlin提供程序(RGP)在图数据库领域越来越常见。在TinkerPop的术语中,该类图提供程序由支持Gremlin语言的图组成。通常,这些是基于服务器的图,通常是基于云的,它们接受Gremlin脚本或字节码作为请求并返回结果。它们通常实现了Gremlin Server协议,这使得TinkerPop驱动程序可以像与Gremlin Server进行连接一样连接到它们。因此,典型的连接方法与上一节中的连接方法相同,并且具有相同的警告提示。
尽管使用了TinkerPop协议和驱动程序作为典型,但RGPs不需要这样做才能被视为TinkerPop-enabled。RGPs可能有自己的驱动程序和协议,可以插入Gremlin语言变体,并且可以提供更高级的选项,如更好的安全性、集群感知、批量请求或其他功能。这些不同系统的详细信息超出了本文档的范围,请查阅其文档以获取更多信息。
基本的Gremlin

GraphTraversalSource基本上是与图实例的连接。该图实例可以是嵌入式,托管在Gremlin Server中,或者由RGP托管,但GraphTraversalSource对此不关心。假设“g”是GraphTraversalSource,不论编程语言或操作模式如何,将数据加载到图中只需要一些基本的Gremlin代码:
CSHARP
JAVA
JAVASCRIPT
PYTHON
GO
gremlin> v1 = g.addV('person').property('name','marko').next()
==>v[0]
gremlin> v2 = g.addV('person').property('name','stephen').next()
==>v[2]
gremlin> g.V(v1).addE('knows').to(v2).property('weight',0.75).iterate()
v1 = g.addV('person').property('name','marko').next()
v2 = g.addV('person').property('name','stephen').next()
g.V(v1).addE('knows').to(v2).property('weight',0.75).iterate()
var v1 = g.AddV("person").Property("name", "marko").Next();
var v2 = g.AddV("person").Property("name", "stephen").Next();
g.V(v1).AddE("knows").To(v2).Property("weight", 0.75).Iterate();
Vertex v1 = g.addV("person").property("name","marko").next();
Vertex v2 = g.addV("person").property("name","stephen").next();
g.V(v1).addE("knows").to(v2).property("weight",0.75).iterate();
const v1 = g.addV('person').property('name','marko').next();
const v2 = g.addV('person').property('name','stephen').next();
g.V(v1).addE('knows').to(v2).property('weight',0.75).iterate();
v1 = g.addV('person').property('name','marko').next()
v2 = g.addV('person').property('name','stephen').next()
g.V(v1).addE('knows').to(v2).property('weight',0.75).iterate()
v1, err := g.AddV("person").Property("name", "marko").Next()
v2, err := g.AddV("person").Property("name", "stephen").Next()
g.V(v1).AddE("knows").To(v2).Property("weight", 0.75).Iterate()
前两行分别添加了一个带有顶点标签“person”和相关“name”属性的顶点。第三行在它们之间添加了一个带有“knows”标签的边,并附带一个“weight”属性。请注意在每行末尾使用了next()和iterate() - 它们作为终端步骤的效果在The Gremlin Console Tutorial中有描述。
| 注意 | 编写Gremlin只是将数据加载到图中的一种方式。某些图可能具有更高效和更简便的特殊数据加载程序。如果需要进行大量一次性加载,请务必查看这些工具。 |
|---|---|
检索此数据也只是编写一个Gremlin语句:
CSHARP
JAVA
JAVASCRIPT
PYTHON
GO
gremlin> marko = g.V().has('person','name','marko').next()
==>v[0]
gremlin> peopleMarkoKnows = g.V().has('person','name','marko').out('knows').toList()
==>v[2]
marko = g.V().has('person','name','marko').next()
peopleMarkoKnows = g.V().has('person','name','marko').out('knows').toList()
var marko = g.V().Has("person", "name", "marko").Next();
var peopleMarkoKnows = g.V().Has("person", "name", "marko").Out("knows").ToList();
Vertex marko = g.V().has("person","name","marko").next()
List<Vertex> peopleMarkoKnows = g.V().has("person","name","marko").out("knows").toList()
const marko = g.V().has('person','name','marko').next()
const peopleMarkoKnows = g.V().has('person','name','marko').out('knows').toList()
marko = g.V().has('person','name','marko').next()
peopleMarkoKnows = g.V().has('person','name','marko').out('knows').toList()
marko, err := g.V().Has("person", "name", "marko").Next()
peopleMarkoKnows, err := g.V().Has("person", "name", "marko").Out("knows").ToList()
在迄今为止介绍的所有这些示例中,Gremlin本身的外观几乎没有太大区别。虽然有一些特定于语言的细微差别,但在大多数情况下,不同语言中的Gremlin看起来都像Gremlin。
可以在遍历部分找到包含每个步骤示例的Gremlin步骤库。该部分旨在作为参考指南,并不一定提供应用Gremlin解决特定问题的方法。请参阅上述的Tutorials、Recipes和Practical Gremlin书籍以获取此类信息。
| 注意 | 可在TinkerPop Compendium页面上找到有关Gremlin的有用资源的完整列表。 |
|---|---|
保持中立
在这些介绍部分中,我们已经详细介绍了TinkerPop如何通过Gremlin实现对构建图应用程序的中立性,并且这种中立性是通过Gremlin实现的。尽管Gremlin在这方面做得很好,但从连接Gremlin部分可以看出,TinkerPop只是一个工具。它不能阻止开发人员做出可能限制其保护能力的设计选择。
在考虑此问题时,需要关注几个方面:
- 数据类型 - 不同的图支持不同类型的数据。例如,TinkerGraph将接受任何JVM对象,但Neo4j等其他图仅支持一小部分可能的类型。选择一种奇特的类型或者可能是仅特定图才支持的自定义类型,可能会在需要时造成迁移摩擦。
- 模式/索引 - TinkerPop没有提供模式和/或索引管理的抽象层。用户将直接使用图提供程序的API。通常情况下,将此类代码封装在与图提供程序特定的类或一组类中以进行隔离或抽象被视为良好的做法。
- 扩展 - 图可能提供Gremlin语言的扩展,这些扩展不会设计成与其他图提供程序兼容。可能存在特殊的辅助语法或表达式,可以以强大的方式展现特定图的某些功能。推荐使用这些选项,但用户应意识到这样做会使他们与该图更紧密地关联。
- 图特定的语义 - TinkerPop试图通过其广泛的测试套件实施特定的语义,但某些图提供程序可能无法完全遵守Gremlin语言或TinkerPop对其API的模型的所有语义。在很大程度上,这并不意味着它们就比完美符合语义的另一个提供程序少TinkerPop-enabled。在考虑新图时要小心,并注意它支持和不支持的内容。
- 图API - 图API(也称为结构API)并不总是对用户可访问的。其可访问性取决于所选择的图系统和编程语言。因此,建议用户避免使用
Graph.addVertex()或Vertex.properties()等方法,而是优先使用g.addV()或g.V(1).properties()的Gremlin方法。
除了考虑这些问题外,确保在不同图之间实现最大程度的兼容性的最佳做法是避免嵌入式模式,而是坚持使用上面的基于字节码的方法,这在Gremlin Server和RGP部分中有解释。这样可以减少违反中立性的机会,因为可以使用这两种模式中的任何一种来执行所有操作。如果使用嵌入式模式,只需将代码编写为Graph实例是“远程”的,而不是本地的JVM。换句话说,编写代码时应假设本地没有可用的GTM。采用这种方法并隔离上述关注点,使得更换图提供程序主要变成了一个配置任务(即修改配置文件以指向不同的图系统)。
图

介绍讨论了TinkerPop启用的图的多样性,特别关注了不同的连接模型,以及TinkerPop如何以一种中立的方式桥接这种多样性。本部分处理了图API的元素,该API被指定为在构建中立系统时要避免使用的API。图API指的是组成Gremlin Traversal Machine(GTM)中的图结构的核心元素,例如Graph、Vertex和Edge Java接口。
为了保持最大的可移植性,用户应仅引用这些接口。"引用"的意思是将其用作指针。对于Graph来说,这意味着在TinkerGraph上调用open()创建实例之后,将指向图数据的位置并使用它来生成GraphTraversalSource实例以编写Gremlin代码:
gremlin> graph = TinkerGraph.open()
==>tinkergraph[vertices:0 edges:0]
gremlin> g = traversal().withEmbedded(graph)
==>graphtraversalsource[tinkergraph[vertices:0 edges:0], standard]
gremlin> g.addV('person')
==>v[0]
graph = TinkerGraph.open()
g = traversal().withEmbedded(graph)
g.addV('person')
在上面的示例中,"graph"是通过在TinkerGraph上调用open()创建的Graph接口,它创建了实例。请注意,尽管代码的最终目的是创建一个名为"person"的顶点,但它没有使用Graph上的API来完成 - 例如graph.addVertex(T.label,'person')。
即使开发人员希望使用graph.addVertex()方法,也只有在以下几种情况下才可能:
- 在JVM上开发应用程序,并且开发人员正在使用嵌入式模式
- 架构包括Gremlin Server,用户将Gremlin脚本发送到服务器
- 所选择的图系统是Remote Gremlin Provider,它通过脚本公开了Graph API
请注意,Gremlin语言变体(GLV)强制开发人员通过引用使用Graph API。在各自的Graph实例上不提供addVertex()方法,properties()方法也不会在调用properties()时填充其图元素。开发应用程序以满足API使用的这个最低公共分母的模式,将大大提高该应用程序在启用TinkerPop的系统之间的可移植性。
在考虑接下来的子章节时,请记住它们通常与图API相关。这里描述了它们以供参考,并在某种程度上是为了向后兼容旧的开发模型。在未来,本节的内容将变得越来越不相关。
功能
Feature实现描述了Graph实例的功能。该接口由图系统提供程序实现,用于两个目的:
- 它告诉用户它们的
Graph实例的功能。 - 它允许对其遵从的功能针对Gremlin测试套件进行测试 - 不符合规定的测试会被"忽略"。
下面的示例在Gremlin控制台中显示了如何打印出Graph的所有功能:
gremlin> graph = TinkerGraph.open()
==>tinkergraph[vertices:0 edges:0]
gremlin> graph.features()
==>FEATURES
> GraphFeatures
>-- Transactions: false
>-- Computer: true
>-- Persistence: true
>-- ConcurrentAccess: false
>-- ThreadedTransactions: false
>-- IoRead: true
>-- IoWrite: true
>-- OrderabilitySemantics: true
>-- ServiceCall: true
> VariableFeatures
>-- Variables: true
>-- BooleanValues: true
>-- ByteValues: true
>-- DoubleValues: true
>-- FloatValues: true
>-- IntegerValues: true
>-- LongValues: true
>-- MapValues: true
>-- MixedListValues: true
>-- SerializableValues: true
>-- StringValues: true
>-- UniformListValues: true
>-- BooleanArrayValues: true
>-- ByteArrayValues: true
>-- DoubleArrayValues: true
>-- FloatArrayValues: true
>-- IntegerArrayValues: true
>-- LongArrayValues: true
>-- StringArrayValues: true
> VertexFeatures
>-- MetaProperties: true
>-- AddVertices: true
>-- RemoveVertices: true
>-- MultiProperties: true
>-- DuplicateMultiProperties: true
>-- Upsert: false
>-- UserSuppliedIds: true
>-- NullPropertyValues: false
>-- AddProperty: true
>-- RemoveProperty: true
>-- NumericIds: true
>-- StringIds: true
>-- UuidIds: true
>-- CustomIds: false
>-- AnyIds: true
> VertexPropertyFeatures
>-- UserSuppliedIds: true
>-- NullPropertyValues: false
>-- RemoveProperty: true
>-- NumericIds: true
>-- StringIds: true
>-- UuidIds: true
>-- CustomIds: false
>-- AnyIds: true
>-- Properties: true
>-- BooleanValues: true
>-- ByteValues: true
>-- DoubleValues: true
>-- FloatValues: true
>-- IntegerValues: true
>-- LongValues: true
>-- MapValues: true
>-- MixedListValues: true
>-- SerializableValues: true
>-- StringValues: true
>-- UniformListValues: true
>-- BooleanArrayValues: true
>-- ByteArrayValues: true
>-- DoubleArrayValues: true
>-- FloatArrayValues: true
>-- IntegerArrayValues: true
>-- LongArrayValues: true
>-- StringArrayValues: true
> EdgeFeatures
>-- AddEdges: true
>-- RemoveEdges: true
>-- Upsert: false
>-- UserSuppliedIds: true
>-- NullPropertyValues: false
>-- AddProperty: true
>-- RemoveProperty: true
>-- NumericIds: true
>-- StringIds: true
>-- UuidIds: true
>-- CustomIds: false
>-- AnyIds: true
> EdgePropertyFeatures
>-- Properties: true
>-- BooleanValues: true
>-- ByteValues: true
>-- DoubleValues: true
>-- FloatValues: true
>-- IntegerValues: true
>-- LongValues: true
>-- MapValues: true
>-- MixedListValues: true
>-- SerializableValues: true
>-- StringValues: true
>-- UniformListValues: true
>-- BooleanArrayValues: true
>-- ByteArrayValues: true
>-- DoubleArrayValues: true
>-- FloatArrayValues: true
>-- IntegerArrayValues: true
>-- LongArrayValues: true
>-- StringArrayValues: true
graph = TinkerGraph.open()
graph.features()
在检查支持功能之前,通常的模式是:
gremlin> graph.features().graph().supportsTransactions()
==>false
gremlin> graph.features().graph().supportsTransactions() ? g.tx().commit() : "no tx"
==>no tx
graph.features().graph().supportsTransactions()
graph.features().graph().supportsTransactions() ? g.tx().commit() : "no tx"
| 注意 | 为了确保提供者无关的代码,始终在使用特定函数之前检查功能是否受支持。这样,在运行时如果提供了不支持访问某个函数的特定实现,应用程序可以正常运行。 |
|---|---|
| 警告 | 引用图的参考图的特征并不反映它连接到的图的特征。它反映的是实例化图本身的特征,考虑到参考图通常是不可变的。 |
|---|---|
顶点属性

TinkerPop引入了VertexProperty<V>的概念。所有顶点的属性都是VertexProperty。VertexProperty实现了Property接口,因此它具有键/值对。然而,VertexProperty还实现了Element接口,因此可以具有一组键/值对。此外,尽管Edge只能有一个键为"name"(例如)的属性,但Vertex可以具有多个"name"属性。引入顶点属性带来了两个功能,这些功能最终提高了图建模工具包:
- 多属性(multi-properties):顶点属性键可以具有多个值。例如,顶点可以具有多个"name"属性。
- 属性上的属性(meta-properties):顶点属性可以具有属性(即,顶点属性可以具有与之相关的键/值数据)。
元属性的可能用例包括:
- 权限:顶点属性可以具有与之关联的键/值的ACL类型的权限信息。
- 审计:当操作顶点属性时,可以将与之关联的键/值信息附加到其上,以说明创建者、删除者等。
- 来源:顶点的“name”可以由多个用户声明。例如,同一名称可能来自不同来源的多个拼写。
下面提供了一个使用顶点属性的运行示例,以演示和解释API:
gremlin> graph = TinkerGraph.open()
==>tinkergraph[vertices:0 edges:0]
gremlin> g = traversal().withEmbedded(graph)
==>graphtraversalsource[tinkergraph[vertices:0 edges:0], standard]
gremlin> v = g.addV().property('name','marko').property('name','marko a. rodriguez').next()
==>v[0]
gremlin> g.V(v).properties('name').count() (1)
==>2
gremlin> v.property(list, 'name', 'm. a. rodriguez') (2)
==>vp[name->m. a. rodriguez]
gremlin> g.V(v).properties('name').count()
==>3
gremlin> g.V(v).properties()
==>vp[name->marko]
==>vp[name->marko a. rodriguez]
==>vp[name->m. a. rodriguez]
gremlin> g.V(v).properties('name')
==>vp[name->marko]
==>vp[name->marko a. rodriguez]
==>vp[name->m. a. rodriguez]
gremlin> g.V(v).properties('name').hasValue('marko')
==>vp[name->marko]
gremlin> g.V(v).properties('name').hasValue('marko').property('acl','private') (3)
==>vp[name->marko]
gremlin> g.V(v).properties('name').hasValue('marko a. rodriguez')
==>vp[name->marko a. rodriguez]
gremlin> g.V(v).properties('name').hasValue('marko a. rodriguez').property('acl','public')
==>vp[name->marko a. rodriguez]
gremlin> g.V(v).properties('name').has('acl','public').value()
==>marko a. rodriguez
gremlin> g.V(v).properties('name').has('acl','public').drop() (4)
gremlin> g.V(v).properties('name').has('acl','public').value()
gremlin> g.V(v).properties('name').has('acl','private').value()
==>marko
gremlin> g.V(v).properties()
==>vp[name->marko]
==>vp[name->m. a. rodriguez]
gremlin> g.V(v).properties().properties() (5)
==>p[acl->private]
gremlin> g.V(v).properties().property('date',2014) (6)
==>vp[name->marko]
==>vp[name->m. a. rodriguez]
gremlin> g.V(v).properties().property('creator','stephen')
==>vp[name->marko]
==>vp[name->m. a. rodriguez]
gremlin> g.V(v).properties().properties()
==>p[date->2014]
==>p[creator->stephen]
==>p[acl->private]
==>p[date->2014]
==>p[creator->stephen]
gremlin> g.V(v).properties('name').valueMap()
==>[date:2014,creator:stephen,acl:private]
==>[date:2014,creator:stephen]
gremlin> g.V(v).property('name','okram') (7)
==>v[0]
gremlin> g.V(v).properties('name')
==>vp[name->okram]
gremlin> g.V(v).values('name') (8)
==>okram
graph = TinkerGraph.open()
g = traversal().withEmbedded(graph)
v = g.addV().property('name','marko').property('name','marko a. rodriguez').next()
g.V(v).properties('name').count() (1)
v.property(list, 'name', 'm. a. rodriguez') (2)
g.V(v).properties('name').count()
g.V(v).properties()
g.V(v).properties('name')
g.V(v).properties('name').hasValue('marko')
g.V(v).properties('name').hasValue('marko').property('acl','private') (3)
g.V(v).properties('name').hasValue('marko a. rodriguez')
g.V(v).properties('name').hasValue('marko a. rodriguez').property('acl','public')
g.V(v).properties('name').has('acl','public').value()
g.V(v).properties('name').has('acl','public').drop() (4)
g.V(v).properties('name').has('acl','public').value()
g.V(v).properties('name').has('acl','private').value()
g.V(v).properties()
g.V(v).properties().properties() (5)
g.V(v).properties().property('date',2014) (6)
g.V(v).properties().property('creator','stephen')
g.V(v).properties().properties()
g.V(v).properties('name').valueMap()
g.V(v).property('name','okram') (7)
g.V(v).properties('name')
g.V(v).values('name') //8
- 一个顶点可以具有与之关联的零个或多个具有相同键的属性。
- 如果使用
Cardinality.list的基数添加属性,则将添加具有提供的键的其他属性。 - 顶点属性可以附带标准的键/值属性。
- 顶点属性的删除方式与属性的删除方式相同。
- 获取每个顶点属性的元属性。
- 顶点属性可以附带任意数量的键/值属性。
property(…)将在添加新的单个属性之前删除所有现有的键化属性(参见VertexProperty.Cardinality)。- 如果只需要属性的值,则可以使用
values()。
如果难以理解顶点属性的概念,最好将其视为"字面值顶点"。一个顶点可以指向一个具有单个值键/值(例如"value=okram")的"字面值顶点"的边缘。指向该字面值顶点的边缘具有一个边缘标签为"name"。边缘上的属性表示字面值顶点的属性。"字面值顶点"不能有其他边缘指向它(只能有一个从关联顶点指向它的边缘)。
| 提示 | 展示了TinkerPop图结构的所有新功能的玩具图可在TinkerFactory.createTheCrew()和data/tinkerpop-crew*中找到。该图演示了多属性和元属性。 |
|---|---|

图3. TinkerPop船员
gremlin> g.V().as('a').
properties('location').as('b').
hasNot('endTime').as('c').
select('a','b','c').by('name').by(value).by('startTime') // 确定每个人的当前位置
==>[a:marko,b:santa fe,c:2005]
==>[a:stephen,b:purcellville,c:2006]
==>[a:matthias,b:seattle,c:2014]
==>[a:daniel,b:aachen,c:2009]
gremlin> g.V().has('name','gremlin').inE('uses').
order().by('skill',asc).as('a').
outV().as('b').
select('a','b').by('skill').by('name') // 按技能级别对gremlin的用户进行排名
==>[a:3,b:matthias]
==>[a:4,b:marko]
==>[a:5,b:stephen]
==>[a:5,b:daniel]
g.V().as('a').
properties('location').as('b').
hasNot('endTime').as('c').
select('a','b','c').by('name').by(value).by('startTime') // 确定每个人的当前位置
g.V().has('name','gremlin').inE('uses').
order().by('skill',asc).as('a').
outV().as('b').
select('a','b').by('skill').by('name') // 按技能级别对gremlin的用户进行排名
图变量
Graph.Variables是与图本身关联的键/值对 - 实质上是一个Map<String,Object>。这些变量用于存储有关图的元数据。示例用例包括:
- 模式信息:命名空间前缀解析为什么,模式最后一次修改时间是什么?
- 全局权限:特定组的访问权限是什么?
- 系统用户信息:系统管理员是谁?
下面提供了使用图变量的示例:
gremlin> graph = TinkerGraph.open()
==>tinkergraph[vertices:0 edges:0]
gremlin> graph.variables()
==>variables[size:0]
gremlin> graph.variables().set('systemAdmins',['stephen','peter','pavel'])
==>null
gremlin> graph.variables().set('systemUsers',['matthias','marko','josh'])
==>null
gremlin> graph.variables().keys()
==>systemAdmins
==>systemUsers
gremlin> graph.variables().get('systemUsers')
==>Optional[[matthias, marko, josh]]
gremlin> graph.variables().get('systemUsers').get()
==>matthias
==>marko
==>josh
gremlin> graph.variables().remove('systemAdmins')
==>null
gremlin> graph.variables().keys()
==>systemUsers
graph = TinkerGraph.open()
graph.variables()
graph.variables().set('systemAdmins',['stephen','peter','pavel'])
graph.variables().set('systemUsers',['matthias','marko','josh'])
graph.variables().keys()
graph.variables().get('systemUsers')
graph.variables().get('systemUsers').get()
graph.variables().remove('systemAdmins')
graph.variables().keys()
| 重要 | 图变量不应受到大量并发变异的影响,也不应用于复杂计算。它的目的是为图存储有关图的数据以供管理目的使用。 |
|---|---|
| 警告 | 尝试在参考图中设置图变量不会将其提升到远程图。通常,参考图具有不可变的特征,并且不支持此功能。 |
|---|---|
命名空间约定
最终用户、图系统提供程序、GraphComputer算法设计人员、GremlinPlugin创建者等都使用元素上的属性来存储信息。在命名属性键时,应遵守一些约定,以确保这些利益相关者之间不会发生冲突。
- 最终用户被授予平坦命名空间(例如,
name、age、location)来对其属性和标签进行键入。 - 图系统提供商被授予隐藏命名空间(例如,
~metadata)来对其属性和标签进行键入。以"“为前缀的数据只能通过图系统实现访问,其他利益相关者无权读取或写入以”"为前缀的数据(参见Graph.Hidden)。测试覆盖和异常存在以确保图系统尊重这个硬边界。 VertexProgram和MapReduce开发人员应使用特定于其域的限定命名空间(例如,mydomain.myvertexprogram.computedata)。GremlinPlugin创建者应使用其域的插件名称作为前缀(例如,mydomain.myplugin)。
| 重要 | TinkerPop使用tinkerpop.和gremlin.作为提供的策略、顶点程序、映射减少实现和插件的前缀。 |
|---|---|
唯一真正受保护的命名空间是隐藏命名空间,它提供给图系统。从那里开始,工程师需要遵守呈现的命名空间约定。
图遍历
遍历事务

数据库事务代表了对数据库执行的工作单元。遍历工作单元受使用约定(即连接方法)和图提供程序的事务模型的影响。在不深入讨论不同约定和模型的情况下,与事务一起工作的最通用和推荐的方法如下所示:
GraphTraversalSource g = traversal().withEmbedded(graph);
// 或者
GraphTraversalSource g = traversal().withRemote(conn);
Transaction tx = g.tx();
// 从事务中生成一个GraphTraversalSource。从gtx产生的遍历实际上将绑定到tx
GraphTraversalSource gtx = tx.begin();
try {
gtx.addV('person').iterate();
gtx.addV('software').iterate();
tx.commit();
} catch (Exception ex) {
tx.rollback();
}
上面的示例很简单,是讨论事务与使用约定和图提供程序注意事项的微妙之处的良好起点。
首先关注远程环境,注意仍然可以从g发出遍历,但这些遍历将具有超出gtx的事务范围,并且如果成功执行,则只会在服务器上提交,否则在服务器上回滚(即一个遍历就是一个事务)。每个孤立的事务都需要其自己的Transaction对象。在同一个Transaction对象上进行多次begin()调用将产生绑定到相同事务的GraphTraversalSource实例,因此:
GraphTraversalSource g = traversal().withRemote(conn);
Transaction tx1 = g.tx();
Transaction tx2 = g.tx();
// gtx1a和gtx1b都将绑定到同一个事务
GraphTraversalSource gtx1a = tx1.begin();
GraphTraversalSource gtx1b = tx1.begin();
// g和gtx2将不知道tx1中发生的情况
GraphTraversalSource gtx2 = tx2.begin();
在远程情况下,从begin()生成的GraphTraversalSource实例可以安全地在多个线程中使用,尽管在服务器端它们将按照它们到达的顺序进行串行处理。远程情况下Transaction的close()方法的默认行为是commit(),因此以下重新编写了之前的示例也是有效的:
// 注意这里我们不再创建一个Transaction对象
// 而是以更内联的方式生成gtx
GraphTraversalSource gtx = g.tx().begin();
try {
gtx.addV('person').iterate();
gtx.addV('software').iterate();
gtx.close();
} catch (Exception ex) {
tx.rollback();
}
| 重要提示 | 使用非JVM语言的事务始终是“远程”的。有关特定语言的事务语法,请参阅Gremlin驱动程序和变体部分中您感兴趣的语言的“Transactions”子部分。 |
|---|---|
在嵌入式情况下,保持事务定义的初始推荐模型,但是用户在更深入的检查时在这里有更多的选项。对于嵌入式用例(甚至在配置Gremlin Server中的图实例时),从g.tx()返回的Transaction对象的类型是对该图的事务模型功能的重要指示器。在大多数情况下,检查该对象将指示派生自AbstractThreadLocalTransaction类的实例,这意味着事务绑定到当前线程,因此在该线程中执行的所有遍历都与该事务相关联。
然后,ThreadLocal事务与之前描述的远程情况不同,因为技术上来说,从g或Transaction生成的任何遍历都属于相同的事务范围。因此,当尝试编写上下文不可知的Gremlin代码时,遵循初始示例的更严格的约定是明智的。
接下来的子章节提供了对每个使用环境的更深入的了解。
嵌入式
在JVM上使用嵌入式图时,有很大的灵活性可用于处理事务。使用图API时,事务由Transaction接口的实现控制,并且可以使用Graph接口上的tx()方法从中获取该对象。重要的是要注意,Transaction对象本身并不表示一个“事务”。它只是公开了与事务一起工作的方法(例如提交、回滚等)。
大多数Graph实现都会实现“自动”ThreadLocal事务,这意味着当在实例化Graph之后发生读取或写入时,事务会在该线程内部自动启动。无需手动调用“创建”或“启动”事务的方法。只需根据需要修改图形并调用graph.tx().commit()来应用更改,或者调用graph.tx().rollback()来撤消更改。当对图执行下一个读取或写入操作时,在该当前执行线程中将启动一个新的事务。
在以这种方式使用事务时,尤其是在Web应用程序(例如HTTP服务器)中,确保事务不会从一个请求泄漏到下一个请求非常重要。换句话说,除非客户端以某种方式通过会话绑定到在同一服务器线程上处理每个请求,否则必须在请求结束时提交或回滚每个请求。通过确保请求封装了事务,可以确保在服务器线程上处理的将来的请求在新的事务状态下开始,并且无法访问之前请求中的事务遗留部分。一个好的策略是在请求开始时回滚事务,这样如果在某种情况下在请求之间发生了事务泄漏,通过新请求可以确保有一个新的事务。
| 提示 | tx()方法在Graph接口上,但也可用于从Graph生成的TraversalSource上。对TraversalSource.tx()的调用将作为一种便利功能代理到底层的Graph。 |
|---|---|
| 提示 | 一些图可能会抛出实现了TemporaryException的异常。在这种情况下,该标记接口旨在通知客户端可以选择稍后重新尝试操作以获取可能的成功。 |
|---|---|
| 警告 | TinkerPop提供了基本的事务控制,但像TinkerPop的许多其他方面一样,具体实现方式是由图系统提供商选择的,以及它如何适应TinkerPop堆栈。请务必了解所使用的特定图实现的事务语义,因为它可能提供与此处描述的不同功能。 |
|---|---|
配置
确定何时启动事务取决于Transaction的行为。决定默认行为是由Graph实现来确定的,除非该实现不允许,否则可以通过以下Transaction方法更改行为本身:
public Transaction onReadWrite(Consumer<Transaction> consumer);
public Transaction onClose(Consumer<Transaction> consumer);
向onReadWrite提供Consumer函数允许定义读取或写入发生时事务如何启动。Transaction.READ_WRITE_BEHAVIOR包含预定义的Consumer函数,可以提供给onReadWrite方法。它有两个选项:
AUTO- 自动事务,事务隐式地开始到读取或写入操作MANUAL- 手动事务,由用户显式打开事务,如果事务未打开,则抛出异常
向onClose提供Consumer函数允许配置在调用Transaction.close()时如何处理事务。Transaction.CLOSE_BEHAVIOR有几个预定义选项可供提供给此方法:
COMMIT- 在事务打开时自动提交ROLLBACK- 在事务打开时自动回滚MANUAL- 如果事务打开,则抛出异常,强制用户显式关闭事务
| 重要提示 | 事务和事务配置对于ThreadLocal具有相同的性质。 |
|---|---|
一旦了解了事务如何配置,接口的大多数其他部分都很容易理解。请注意,Neo4j-Gremlin在以下示例中用于演示,因为TinkerGraph不支持事务。
| 重要提示 | 以下示例旨在演示ThreadLocal事务的具体用法,并与推荐的嵌入式和远程环境中更普遍的事务约定相矛盾。在使用此方法之前,请确保了解遍历事务部分中描述的首选方法。 |
|---|---|
gremlin> graph = Neo4jGraph.open('/tmp/neo4j')
==>neo4jgraph[EmbeddedGraphDatabase [/tmp/neo4j]]
gremlin> g = traversal().withEmbedded(graph)
==>graphtraversalsource[neo4jgraph[community single [/tmp/neo4j]], standard]
gremlin> graph.features()
==>FEATURES
> GraphFeatures
>-- Transactions: true //1
>-- Computer: false
>-- Persistence: true
...
gremlin> g.tx().onReadWrite(Transaction.READ_WRITE_BEHAVIOR.AUTO) //2
==>org.apache.tinkerpop.gremlin.neo4j.structure.Neo4jGraph$Neo4jTransaction@1c067c0d
gremlin> g.addV("person").("name","stephen") //3
==>v[0]
gremlin> g.tx().commit() //4
==>null
gremlin> g.tx().onReadWrite(Transaction.READ_WRITE_BEHAVIOR.MANUAL) //5
==>org.apache.tinkerpop.gremlin.neo4j.structure.Neo4jGraph$Neo4jTransaction@1c067c0d
gremlin> g.tx().isOpen()
==>false
gremlin> g.addV("person").("name","marko") //6
Open a transaction before attempting to read/write the transaction
gremlin> g.tx().open() //7
==>null
gremlin> g.addV("person").("name","marko") //8
==>v[1]
gremlin> g.tx().commit()
==>null
- 检查
features以确保图支持事务。 - 默认情况下,
Neo4jGraph配置为使用“自动”事务,因此此处设置仅用于演示目的。 - 添加顶点时,事务会自动启动。从这一点开始,可以在该打开事务的上下文中进行更多的变异或执行其他读取操作。
- 调用
commit完成事务。 - 将事务行为更改为需要手动控制。
- 现在,添加顶点将失败,因为事务没有明确打开。
- 显式打开一个事务。
- 现在,添加顶点成功,因为事务已手动打开。
| 注意 | 当涉及到事务的具体行为时,可能重要的是查阅您使用的Graph实现的文档。TinkerPop在此领域允许某些灵活性,不同的实现可能不具有完全相同的行为和ACID保证。 |
|---|---|
Gremlin Server
与Gremlin Server一起使用事务的可用功能取决于所使用的交互方法。与Gremlin Server进行交互的首选方法是通过websocket和基于字节码的请求。事务部分的开始详细描述了这种方法,包括示例。
Gremlin Server还可以接受基于Gremlin的脚本。脚本方法提供对Graph API的访问,因此也提供了嵌入式部分中描述的事务模型。因此,单个脚本可以具有每个请求执行多个事务的能力,并且开发人员可以完全控制何时提交或回滚事务。
发送脚本到Gremlin Server有两种方法:无会话和基于会话。在无会话的请求中,将始终尝试在请求结束时关闭事务,如果没有错误,则提交事务,如果失败,则回滚事务。因此,在脚本本身中手动关闭事务是不必要的。默认情况下,基于会话的请求不具备此特性。事务将在服务器上保持打开状态,直到用户手动关闭它。有一个选项可以对会话进行自动事务管理。有关此主题的更多信息,请参见Considering Transactions部分和Considering Sessions部分。
远程Gremlin提供程序
目前,远程Gremlin提供程序的事务模式与Gremlin Server基本相同。由于大多数RGPs不会公开Graph实例,因此通常不允许以无会话方式访问嵌入式图中可用的较低级别事务函数。例如,没有Graph实例,无法配置事务关闭或读写行为。“事务”是什么意思的性质将取决于RGP,与任何TinkerPop启用的图系统一样,因此重要的是查阅该系统的文档以获取更多详细信息。
配置步骤
GraphTraversalSource上的许多方法用于配置用法。这些配置会影响从中生成遍历的方式。配置方法可以通过它们的名称来识别,其中使用"with"作为前缀:
With Configuration
with()配置向TraversalSource添加任意数据,图提供程序可以将其用作遍历执行的配置选项。此配置类似于应用于单个步骤时具有类似功能的with()修饰器。
g.with('providerDefinedVariable', 0.33).V()
"providerDefinedVariable"的值0.33将绑定到每个以此方式生成的遍历。请查阅正在使用的图系统,以确定是否存在任何此类配置选项。
WithBulk Configuration
withBulk()配置允许控制批量操作。默认情况下,该值为true,允许正常进行批量操作,但当设置为false时,在行为上引入了细微的变化,如sack()-step中的示例所示。
WithComputer Configuration
withComputer()配置添加一个Computer,用于处理遍历,并且对于基于OLAP的处理和需要该处理的步骤是必需的。请参阅与SparkGraphComputer相关的示例或参阅需要计算机所需步骤的示例,例如pageRank()或[shortestpath-shortestPath()]。
WithSack Configuration
withSack()配置添加一个"背包(sack)",可以由从此源生成的遍历访问。该功能在sack()-step的示例中详细介绍了。
WithSideEffect Configuration
withSideEffect()配置向从此源生成的遍历添加一个任意的Object,可以根据提供的键作为副作用进行访问。
gremlin> g.withSideEffect('x',['dog','cat','fish']).
V().has('person','name','marko').select('x').unfold()
==>dog
==>cat
==>fish
g.withSideEffect('x',['dog','cat','fish']).
V().has('person','name','marko').select('x').unfold()
其他实际示例可以在文档的其他地方找到。math()-step 示例和where()-step 示例应该有助于更仔细地检查此配置步骤。
WithStrategies Configuration
withStrategies()配置允许包含其他TraversalStrategy实例,以应用于从配置源生成的任何遍历。有关此配置如何工作的详细信息,请参阅遍历策略部分。
WithoutStrategies Configuration
withoutStrategies()配置从将应用于从配置源生成的遍历中移除特定的TraversalStrategy。有关此配置如何工作的详细信息,请参阅遍历策略部分。
开始步骤
并非所有的步骤都能够启动GraphTraversal。只有GraphTraversalSource上的步骤才能做到这一点。GraphTraversalSource上的许多方法实际上是用于配置的,不应将其与开始步骤混淆。
生成步骤实际上产生一个遍历,并且通常与现有步骤的名称匹配:
addE()- 添加一个边来启动遍历(示例)。addV()- 添加一个顶点来启动遍历(示例)。E()- 从图中读取边来启动遍历(示例)。inject()- 插入任意对象来启动遍历(示例)。V()- 从图中读取顶点来启动遍历(示例)。
图遍历步骤
Gremlin步骤被链接在一起以生成实际的遍历,并通过GraphTraversalSource上的开始步骤触发。
| 重要提示 | 关于Gremlin语言的更多详细信息可以在Gremlin语义部分中的提供程序文档中找到。 |
|---|---|
通用步骤
有五个通用步骤,每个步骤都有一个遍历和一个lambda表示,后面描述的所有其他具体步骤都是基于这些通用步骤扩展的。
| 步骤 | 描述 |
|---|---|
map(Traversal<S, E>) map(Function<Traverser<S>, E>) |
将traverser映射到下一步要处理的某个类型为E的对象。 |
flatMap(Traversal<S, E>) flatMap(Function<Traverser<S>, Iterator<E>>) |
将traverser映射到一个E对象的迭代器,该迭代器将流式传递给下一步。 |
filter(Traversal<?, ?>) filter(Predicate<Traverser<S>>) |
将traverser映射为true或false,其中false不会将traverser传递给下一步。 |
sideEffect(Traversal<S, S>) sideEffect(Consumer<Traverser<S>>) |
对traverser执行某些操作,并将其传递给下一步。 |
branch(Traversal<S, M>) branch(Function<Traverser<S>,M>) |
将traverser拆分为由M标记索引的所有遍历。 |
| 警告 | 为了教育目的,演示了lambda步骤,因为它们代表了Gremlin语言的基本构造。在实践中,应避免使用lambda步骤,而应使用它们的遍历表示,并且存在遍历验证策略来禁止使用它们,除非明确"关闭"。有关lambda的问题的更多信息,请阅读A Note on Lambdas。 |
|---|---|
Traverser<S>对象提供对以下内容的访问:
- 当前遍历的
S对象 -Traverser.get()。 - 遍历器当前遍历的路径 -
Traverser.path()。- 获取特定路径历史记录对象的快捷方式 -
Traverser.path(String) == Traverser.path().get(String)。
- 获取特定路径历史记录对象的快捷方式 -
- 遍历器已经经过当前循环的次数 -
Traverser.loops()。 - 由该遍历器表示的对象数量 -
Traverser.bulk()。 - 与此遍历器关联的局部数据结构 -
Traverser.sack()。 - 与遍历相关的副作用 -
Traverser.sideEffects()。- 获取特定副作用的快捷方式 -
Traverser.sideEffect(String) == Traverser.sideEffects().get(String)。
- 获取特定副作用的快捷方式 -

gremlin> g.V(1).out().values('name') (1)
==>lop
==>vadas
==>josh
gremlin> g.V(1).out().map {it.get().value('name')} (2)
==>lop
==>vadas
==>josh
gremlin> g.V(1).out().map(values('name')) (3)
==>lop
==>vadas
==>josh
g.V(1).out().values('name') (1)
g.V(1).out().map {it.get().value('name')} (2)
g.V(1).out().map(values('name')) //3
- 从顶点1出发,获取相邻顶点的名称值。
- 相同的操作,但使用lambda来访问名称属性值。
- 再次相同的操作,但使用
map()的遍历表示。

gremlin> g.V().filter {it.get().label() == 'person'} (1)
==>v[1]
==>v[2]
==>v[4]
==>v[6]
gremlin> g.V().filter(label().is('person')) (2)
==>v[1]
==>v[2]
==>v[4]
==>v[6]
gremlin> g.V().hasLabel('person') (3)
==>v[1]
==>v[2]
==>v[4]
==>v[6]
g.V().filter {it.get().label() == 'person'} (1)
g.V().filter(label().is('person')) (2)
g.V().hasLabel('person') //3
- 只有带有"person"标签的顶点才能通过过滤器。
- 相同的操作,但使用
filter()的遍历表示。 - 更具体的
has()-step实际上是使用相应谓词的filter()。

gremlin> g.V().hasLabel('person').sideEffect(System.out.&println) (1)
v[1]
==>v[1]
v[2]
==>v[2]
v[4]
==>v[4]
v[6]
==>v[6]
gremlin> g.V().sideEffect(outE().count().aggregate(local,"o")).
sideEffect(inE().count().aggregate(local,"i")).cap("o","i") (2)
==>[i:[0,0,1,1,1,3],o:[3,0,0,0,2,1]]
g.V().hasLabel('person').sideEffect(System.out.&println) (1)
g.V().sideEffect(outE().count().aggregate(local,"o")).
sideEffect(inE().count().aggregate(local,"i")).cap("o","i") //2
sideEffect()中的任何内容都会传递到下一步,但可能会发生一些干预操作。- 计算每个顶点的出度和入度。两个
sideEffect()接收相同的顶点。

gremlin> g.V().branch {it.get().value('name')}.
option('marko', values('age')).
option(none, values('name')) (1)
==>29
==>vadas
==>lop
==>josh
==>ripple
==>peter
gremlin> g.V().branch(values('name')).
option('marko', values('age')).
option(none, values('name')) (2)
==>29
==>vadas
==>lop
==>josh
==>ripple
==>peter
gremlin> g.V().choose(has('name','marko'),
values('age'),
values('name')) (3)
==>29
==>vadas
==>lop
==>josh
==>ripple
==>peter
g.V().branch {it.get().value('name')}.
option('marko', values('age')).
option(none, values('name')) (1)
g.V().branch(values('name')).
option('marko', values('age')).
option(none, values('name')) (2)
g.V().choose(has('name','marko'),
values('age'),
values('name')) //3
- 如果顶点是"marko",则获取他的年龄,否则获取顶点的名称。
- 相同的操作,但使用
branch()的遍历表示。 - 更具体的基于布尔值的
choose()-step实际上是branch()的实现。
终端步骤
通常,当一个步骤连接到一个遍历中时,将返回一个新的遍历。通过这种方式,遍历可以以流畅、单子的方式逐步构建起来。然而,有些步骤并不返回遍历,而是执行遍历并返回结果。这些步骤被称为**终端步骤(terminal)**并通过下面的示例进行解释。
gremlin> g.V().out('created').hasNext() (1)
==>true
gremlin> g.V().out('created').next() (2)
==>v[3]
gremlin> g.V().out('created').next(2) (3)
==>v[3]
==>v[5]
gremlin> g.V().out('nothing').tryNext() (4)
==>Optional.empty
gremlin> g.V().out('created').toList() (5)
==>v[3]
==>v[5]
==>v[3]
==>v[3]
gremlin> g.V().out('created').toSet() (6)
==>v[3]
==>v[5]
gremlin> g.V().out('created').toBulkSet() (7)
==>v[3]
==>v[3]
==>v[3]
==>v[5]
gremlin> results = ['blah',3]
==>blah
==>3
gremlin> g.V().out('created').fill(results) (8)
==>blah
==>3
==>v[3]
==>v[5]
==>v[3]
==>v[3]
gremlin> g.addV('person').iterate() (9)
g.V().out('created').hasNext() (1)
g.V().out('created').next() (2)
g.V().out('created').next(2) (3)
g.V().out('nothing').tryNext() (4)
g.V().out('created').toList() (5)
g.V().out('created').toSet() (6)
g.V().out('created').toBulkSet() (7)
results = ['blah',3]
g.V().out('created').fill(results) (8)
g.addV('person').iterate() //9
hasNext()确定是否有可用的结果(在gremlin-javascript中不支持)。next()返回下一个结果。next(n)返回列表中的下一个n个结果(在gremlin-javascript或 Gremlin.NET 中不支持)。tryNext()返回一个Optional,因此是hasNext()/next()的组合(仅支持 JVM 语言)。toList()返回所有结果的列表。toSet()返回所有结果的集合,并且会去除重复项(在gremlin-javascript中不支持)。toBulkSet()返回所有结果的加权集合,并且通过加权保留重复项(仅支持 JVM 语言)。fill(collection)将所有结果放入提供的集合中,并在完成时返回集合(仅支持 JVM 语言)。iterate()不完全符合终端步骤的定义,因为它不返回结果,但仍然返回一个遍历。然而,它作为终端步骤的行为是迭代遍历并生成副作用,而不返回实际结果。
还有一个名为 promise() 的终端步骤,只能与连接到 Gremlin Server 或 RGPs 的远程遍历一起使用。它启动了一个承诺,以在将来执行当前 Traversal 上的函数。
最后,explain() 步骤也是一个终端步骤,并在自己的部分中进行了描述。
AddE 步骤
Reasoning 是将数据中的隐含信息变为显式的过程。图中的对象,即顶点和边,是显式的。图中的遍历是隐含的。换句话说,遍历通过定义暴露了意义。例如,考虑"co-developer"的概念。如果两个人共同参与了同一个项目,那么他们就是共同开发者。这个概念可以表示为遍历,并且因此"co-developers"的概念可以得出。而且,通过addE()步骤(map/sideEffect)可以将隐含的东西变为显式的。

gremlin> g.V(1).as('a').out('created').in('created').where(neq('a')).
addE('co-developer').from('a').property('year',2009) (1)
==>e[0][1-co-developer->4]
==>e[13][1-co-developer->6]
gremlin> g.V(3,4,5).aggregate('x').has('name','josh').as('a').
select('x').unfold().hasLabel('software').addE('createdBy').to('a') (2)
==>e[14][3-createdBy->4]
==>e[15][5-createdBy->4]
gremlin> g.V().as('a').out('created').addE('createdBy').to('a').property('acl','public') (3)
==>e[16][3-createdBy->1]
==>e[17][5-createdBy->4]
==>e[18][3-createdBy->4]
==>e[19][3-createdBy->6]
gremlin> g.V(1).as('a').out('knows').
addE('livesNear').from('a').property('year',2009).
inV().inE('livesNear').values('year') (4)
==>2009
==>2009
gremlin> g.V().match(
__.as('a').out('knows').as('b'),
__.as('a').out('created').as('c'),
__.as('b').out('created').as('c')).
addE('friendlyCollaborator').from('a').to('b').
property(id,23).property('project',select('c').values('name')) (5)
==>e[23][1-friendlyCollaborator->4]
gremlin> g.E(23).valueMap()
==>[project:lop]
gremlin> vMarko = g.V().has('name','marko').next()
==>v[1]
gremlin> vPeter = g.V().has('name','peter').next()
==>v[6]
gremlin> g.V(vMarko).addE('knows').to(vPeter) (6)
==>e[22][1-knows->6]
gremlin> g.addE('knows').from(vMarko).to(vPeter) (7)
==>e[24][1-knows->6]
g.V(1).as('a').out('created').in('created').where(neq('a')).
addE('co-developer').from('a').property('year',2009) (1)
g.V(3,4,5).aggregate('x').has('name','josh').as('a').
select('x').unfold().hasLabel('software').addE('createdBy').to('a') (2)
g.V().as('a').out('created').addE('createdBy').to('a').property('acl','public') (3)
g.V(1).as('a').out('knows').
addE('livesNear').from('a').property('year',2009).
inV().inE('livesNear').values('year') (4)
g.V().match(
__.as('a').out('knows').as('b'),
__.as('a').out('created').as('c'),
__.as('b').out('created').as('c')).
addE('friendlyCollaborator').from('a').to('b').
property(id,23).property('project',select('c').values('name')) (5)
g.E(23).valueMap()
vMarko = g.V().has('name','marko').next()
vPeter = g.V().has('name','peter').next()
g.V(vMarko).addE('knows').to(vPeter) (6)
g.addE('knows').from(vMarko).to(vPeter) //7
- 在 Marko 和他的合作者之间添加一个带有 year 属性的 co-developer 边。
- 从 josh-顶点到 lop-和 ripple-顶点添加 createdBy 边。
- 对于所有创建的边,添加一个相反的 createdBy 边。
- 新创建的边是可遍历对象。
- 将两个任意绑定在遍历中通过
from()→to()进行连接,其中对于支持用户提供的 id 的图可以提供id。 - 在 Marko 和 Peter 之间添加一个边,给定定向(分离的)顶点引用。
- 在 Marko 和 Peter 之间添加一个边,给定定向(分离的)顶点引用。
其他参考资料
AddV 步骤
addV()-步骤用于向图中添加顶点(map/sideEffect)。对于每个传入的对象,都会创建一个顶点。此外,GraphTraversalSource 维护了一个 addV() 方法。
gremlin> g.addV('person').property('name','stephen')
==>v[0]
gremlin> g.V().values('name')
==>stephen
==>marko
==>vadas
==>lop
==>josh
==>ripple
==>peter
gremlin> g.V().outE('knows').addV().property('name','nothing')
==>v[13]
==>v[15]
gremlin> g.V().has('name','nothing')
==>v[13]
==>v[15]
gremlin> g.V().has('name','nothing').bothE()
g.addV('person').property('name','stephen')
g.V().values('name')
g.V().outE('knows').addV().property('name','nothing')
g.V().has('name','nothing')
g.V().has('name','nothing').bothE()
其他参考资料
addV(), addV(String), addV(Traversal)
Aggregate 步骤

aggregate()-步骤(sideEffect)用于将遍历的特定点上的所有对象聚合到一个 Collection 中。此步骤使用 Scope 来帮助确定聚合行为。对于 global 范围,这意味着该步骤将使用急切求值,即在继续之前不会有任何对象,直到所有之前的对象都已完全聚合。急切求值模型在需要将某个特定点的所有内容用于未来计算的情况下至关重要。默认情况下,当没有提供 Scope 的 aggregate() 重载调用时,默认为 global。以下是一个示例。
gremlin> g.V(1).out('created') (1)
==>v[3]
gremlin> g.V(1).out('created').aggregate('x') (2)
==>v[3]
gremlin> g.V(1).out('created').aggregate(global, 'x') (3)
==>v[3]
gremlin> g.V(1).out('created').aggregate('x').in('created') (4)
==>v[1]
==>v[4]
==>v[6]
gremlin> g.V(1).out('created').aggregate('x').in('created').out('created') (5)
==>v[3]
==>v[5]
==>v[3]
==>v[3]
gremlin> g.V(1).out('created').aggregate('x').in('created').out('created').
where(without('x')).values('name') (6)
==>ripple
g.V(1).out('created') (1)
g.V(1).out('created').aggregate('x') (2)
g.V(1).out('created').aggregate(global, 'x') (3)
g.V(1).out('created').aggregate('x').in('created') (4)
g.V(1).out('created').aggregate('x').in('created').out('created') (5)
g.V(1).out('created').aggregate('x').in('created').out('created').
where(without('x')).values('name') //6
- Marko 创建了什么?
- 聚合他的所有创建。
- 与上一行完全相同。
- Marko 的合作者是谁?
- Marko 的合作者创建了什么?
- Marko 的合作者创建的项目中,Marko 尚未创建的有哪些?
在推荐系统中,使用了上述模式:
"用户 A 喜欢什么?其他人喜欢什么?其他人喜欢的东西中,A 还没有喜欢过的有哪些?"
最后,aggregate()-步骤可以通过 by()-投影进行调节。
gremlin> g.V().out('knows').aggregate('x').cap('x')
==>[v[2],v[4]]
gremlin> g.V().out('knows').aggregate('x').by('name').cap('x')
==>[vadas,josh]
gremlin> g.V().out('knows').aggregate('x').by('age').cap('x') (1)
==>[27,32]
g.V().out('knows').aggregate('x').cap('x')
g.V().out('knows').aggregate('x').by('name').cap('x')
g.V().out('knows').aggregate('x').by('age').cap('x') //1
- 对于不是所有顶点都具有生产性(productive)的 “age” 属性,这些值不会包含在聚合中。
对于 local 范围,聚合将以惰性方式进行。
| 注意 | 在 3.4.3 之前,local 聚合(即惰性)求值由 store()-步骤处理。 |
|---|---|
gremlin> g.V().