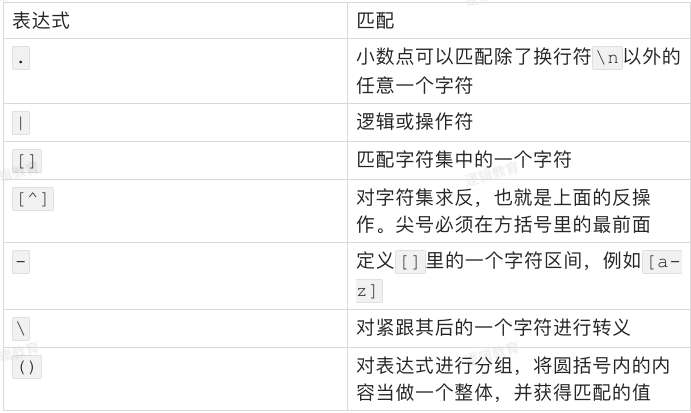
代码思路
- 从网站获取完整网页数据
- 数据转换成string,查找指定字符串:
- findall、.*?搭配使用,查找出所有目标数据list
- for循环遍历list,提取目标url
- 根据url从网站获取图片数据
- 保存数据
完整源码
# 爬虫实战3,正则表达式解析数据
pass # 这是分隔符
# 1、导入库
import os
import requests
import time
import re
t1 = time.thread_time() # 测试开始时间
# 2、爬取数据
url = "https://pic.sogou.com/"
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36"
}
if not os.path.exists("./img"):
os.mkdir("./img") # 创建图片存储路径
page_Text = requests.get(url,headers=headers)
with open('123.html','wb') as f:
f.write(page_Text.content) # 保存html log
str1 = page_Text.text
# str1 = ('<img src="//img04.sogoucdn.com/v2/thumb/retype_exclude_gif/ext/auto/q/80/crop/xy/ai/t/0/w/562/h/752?appid=122&url=https://img01.sogoucdn.com/app/a/100520020/8ff759f66f5e475579bb7083f6f958e6" alt style="object-fit: cover; height: 100%">'
# '<img src="//img05.sogoucdn.com/v2/thumb/retype_exclude_gif/ext/auto/q/80/crop/xy/ai/t/0/w/562/h/752?appid=122&url=https://img01.sogoucdn.com/app/a/100520020/8ff759f66f5e475579bb7083f6f958e6" alt style="object-fit: cover; height: 100%">'
# '<img src="//img06.sogoucdn.com/v2/thumb/retype_exclude_gif/ext/auto/q/80/crop/xy/ai/t/0/w/562/h/752?appid=122&url=https://img01.sogoucdn.com/app/a/100520020/8ff759f66f5e475579bb7083f6f958e6" alt style="object-fit: cover; height: 100%">')
# 3、提取数据
ex = '<img src=.*? alt style=.*?>' # .*?为缺省数据代表符号,意思为省略一下数据,以便于批量性查找开头相同,但是中间内容不同的数据
img_src_list = re.findall(ex,str1)
print(f"找到了{len(img_src_list)}个数据")
# 提取完整url,属于分析数据的一环
for i in range(len(img_src_list)):
ex2 = 'https.*?"' # 查找https开头的url数据
img2 = re.findall(ex2,img_src_list[i])
str2 = img2[0].replace('"','') # 把不需要的字符串替换成空字符串
img_data = requests.get(url=str2,headers=headers).content # 在取得完整的image url后,获取图片数据
# 4、保存数据
img_name = str2.split('/')[-1] # 获取image名称
imgPath = 'img\\'+img_name+".png" # image存储路径
with open(imgPath,'wb') as f:
f.write(img_data)
time.sleep(0.001) # 不要太频繁提取数据,否则会被认为是在攻击网站
print(str2)
print(f"use time : {0}",time.thread_time() - t1) # 打印测试耗时
pass # 这是分隔符