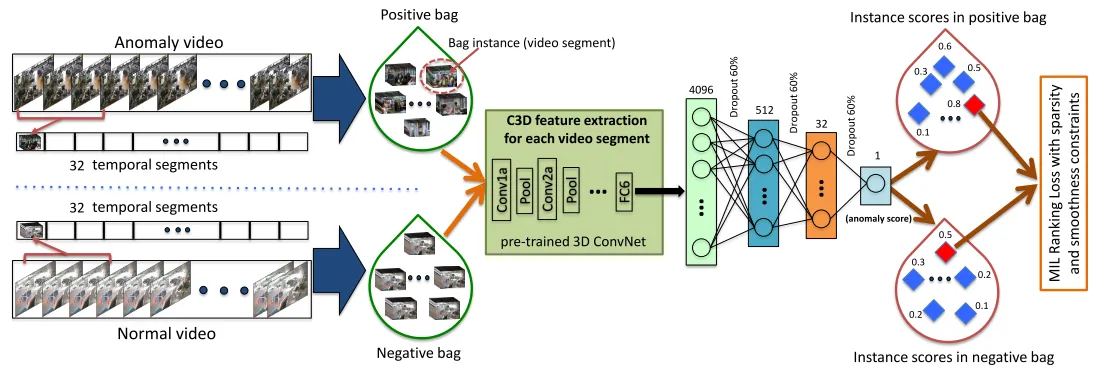
基于深度学习的视觉应用, 又名:机器视觉之从调包侠到底层开发(第4天)
PS:这个系列是准备做从Python一些接口应用开发,openCV基础使用场景原理讲解,做一些demo案例讲解,然后开始数学基础复习, 基础图像处理技术概念, 特征提取和描述细节, 深入了解图像分割和识别,三维视觉和摄影测量,和用C++进行图形学上的练习,再抽几篇关键的前沿文献和教材阅读。企业级项目制作。 最后再进行图像方向的论文写作让研究生阶段就可以发表的文献。
需要对理论进行补充, 包括:数学基础复习, 基础图像处理技术, 三维视觉和摄影测量, 图形学, 机器学习
PS::
当我提到“相机”的时候,并不一定是指照相机,尤其是在计算机视觉和图像处理的上下文中,"相机"通常指的是数字相机或虚拟相机,而不是传统的照相机。
具体来说:
- 数字相机:这是传统意义上的相机,通常用于拍摄静态图像或录制视频。数字相机包括单反相机、傻瓜相机、摄像机等。它们通过光学透镜捕捉现实世界中的光线,将图像传感器上的光线模式转化为数字图像或视频。
- 虚拟相机:在计算机图形学、计算机视觉和虚拟现实中,虚拟相机是一个模拟的概念。它代表了一个在虚拟三维场景中的观察者或视点,可以用来渲染或呈现虚拟世界。虚拟相机通常由参数(如位置、方向、视场角等)来描述,以控制渲染过程中的视图。
当我提到“相机的位移”时,通常是指虚拟相机在虚拟三维空间中的位置和方向的变化,而不是指实际的数字相机的位移。这种概念在计算机图形学、虚拟现实和三维建模中非常常见,用于控制虚拟世界的视图和动画。
目录:
- 双目相机基础:
- 视觉三角测量:
- 视差图:
- 运动估计:
- 深度学习方法:
- 实际应用:
- 双目实战
- 其他了解一下的知识点
1. 双目相机基础
双目相机原理
概念:
双目相机系统模仿人类的双眼视觉,由两个摄像头组成,分别模拟左眼和右眼。这种设置使得双目相机能够从两个略有不同的视角捕捉场景,产生视差。视差是指同一物体在两个摄像头图像中的位置差异,这种差异使得双目相机可以计算出物体的深度信息。视差图是一种图像,展示了双目相机视野中每个点的视差值。
场景应用:
双目相机广泛应用于机器视觉、自动驾驶汽车、机器人导航、3D重建和增强现实等领域。在这些应用中,深度信息对于物体检测、障碍物避让、环境理解和交互至关重要。
相机标定
概念:
相机标定是确定相机的内部和外部参数的过程。内部参数包括焦距、主点(图像中心)和畸变系数,而外部参数涉及到相机之间的几何关系,如相对位置和姿态。标定通常通过拍摄已知几何特征的标定板来完成,如棋盘格图案,然后利用这些信息计算出相机参数。
场景应用:
在工业自动化、高精度测量、虚拟现实和计算机图形学等领域中,精确的相机标定是必不可少的。它确保图像数据能够准确转换为实际世界坐标,是3D重建、运动跟踪和空间感知的关键步骤。
示例代码
import cv2
import numpy as np
# 定义标定板角点数量和实际尺寸
checkerboard_size = (6, 9)
square_size = 1.0 # 实际尺寸单位
# 存储世界坐标和图像坐标的列表
world_points = []
image_points = []
# 生成标定板角点的世界坐标
world_point = np.zeros((1, checkerboard_size[0] * checkerboard_size[1], 3), np.float32)
world_point[0, :, :2] = np.mgrid[0:checkerboard_size[0], 0:checkerboard_size[1]].T.reshape(-1, 2)
world_point *= square_size
# 读取标定图像
images = [...] # 标定图像路径列表
for img_path in images:
img = cv2.imread(img_path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 寻找棋盘格角点
ret, corners = cv2.findChessboardCorners(gray, checkerboard_size, None)
if ret:
world_points.append(world_point)
image_points.append(corners)
# 绘制并显示角点
cv2.drawChessboardCorners(img, checkerboard_size, corners, ret)
cv2.imshow('Calibration Image', img)
cv2.waitKey(100)
cv2.destroyAllWindows()
# 相机标定
ret, camera_matrix, distortion_coeff, rotation_vectors, translation_vectors = cv2.calibrateCamera(
world_points, image_points, gray.shape[::-1], None, None)
print("Camera Matrix:\\n", camera_matrix)
print("Distortion Coefficients:\\n", distortion_coeff)
这段代码展示了如何使用OpenCV对双目相机进行标定。首先,它定义了标定板的角点数量和尺寸,然后读取标定图像并寻找棋盘格角点。最后,使用cv2.calibrateCamera函数计算相机的内部参数和畸变系数。
2**. 三角测量原理**:
三角测量原理是基于视差的概念。视差是指当一个物体同时被两个不同位置的相机观察时,物体在两个图像中的位置差异。这个差异可以用来计算物体的深度信息,从而得到其三维位置。具体原理如下:
- 视差计算:首先,相机需要拍摄同一物体的两幅图像,这两幅图像的视点位置稍有不同。然后,通过对这两幅图像中同一物体的像素位置进行比较,可以计算出每个像素的视差值。
- 三角测量:一旦获得了视差信息,就可以使用三角测量原理来计算物体的深度。这里涉及到三角形的相似性,其中相机、物体和物体在两个图像中的像素位置构成一个三角形。通过这些三角形的相似性,可以计算出物体的深度。
2.1 三角测量算法:
三角测量算法有多种,其中一些常见的包括:
- 基于视差的三角测量:这是最基本的方法,根据视差信息和相机参数进行计算。该方法简单,但对于复杂场景和噪音敏感。
- 基于立体几何的三角测量:这种方法利用立体几何关系,如本质矩阵和基本矩阵,来计算物体的深度信息。它更适用于复杂的情况,但需要更多的计算资源。
示例场景和代码:
假设我们有两个相机,它们拍摄了同一物体的两幅图像。我们想要计算物体的深度信息。
import numpy as np
# 假设两个相机的参数
camera_params_1 = {
'focal_length': 50, 'baseline': 0.1} # 相机1的焦距和基线
camera_params_2 = {
'focal_length': 50, 'baseline': 0.1} # 相机2的焦距和基线
# 假设两个像素点的视差
disparity = 10 # 视差值
# 计算物体的深度
depth = (camera_params_1['focal_length'] * camera_params_2['focal_length']) / (disparity * camera_params_1['baseline'])
print(f"物体的深度为: {
depth} 米")
在这个示例中,我们使用了两个相机的参数和视差值来计算物体的深度。这个深度值表示物体距离相机的距离。
3**. 视差图生成**:
视差图生成是从双目相机图像中计算视差信息的过程。视差图通常是灰度图像,其中每个像素的灰度值表示对应位置的视差。以下是视差图生成的关键概念:
- 匹配点对:首先,需要找到左右两幅图像中的匹配点对。这些点对表示在左右图像中对应的特征点。
- 视差计算:一旦找到匹配点对,就可以计算每个像素的视差值。视差表示左右图像中对应特征点的水平偏移量。通常,视差越大,物体离相机越近。
- 视差图生成算法:视差图可以使用不同的算法生成,包括区域匹配、像素匹配、深度学习等。这些算法基于匹配点对来估计视差。
3.2 视差图滤波和后处理:
一旦生成了视差图,通常需要对其进行滤波和后处理,以减小噪声并提高估计的准确性。以下是相关概念:
- 滤波:滤波用于去除视差图中的噪声,例如离群点或不稳定的估计值。常用的滤波方法包括中值滤波、高斯滤波等。
- 后处理:后处理包括平滑、边缘保留滤波等技术,用于进一步改善视差图的质量。这可以提高深度估计的精确性。
示例场景和代码:
假设我们有一对双目相机图像,我们想要生成视差图,并对其进行滤波和后处理。
import cv2
# 从左右相机图像中加载图像
left_image = cv2.imread('left_image.png', cv2.IMREAD_GRAYSCALE)
right_image = cv2.imread('right_image.png', cv2.IMREAD_GRAYSCALE)
# 创建视差计算器对象
stereo = cv2.StereoBM_create(numDisparities=64, blockSize=15)
# 计算视差图
disparity_map = stereo.compute(left_image, right_image)
# 进行滤波和后处理
filtered_disparity_map = cv2.medianBlur(disparity_map, 5)
filtered_disparity_map = cv2.ximgproc.disparityWLSFilter(left_image, right_image, None, filtered_disparity_map)
# 显示视差图
cv2.imshow('Disparity Map', filtered_disparity_map)
cv2.waitKey(0)
cv2.destroyAllWindows()
在这个示例中,我们使用OpenCV库中的StereoBM算法来计算视差图,然后使用中值滤波和边缘保留滤波对其进行滤波和后处理。
4.1 光流估计:
光流估计是一种用于估计相邻图像帧之间像素位移的技术。基本概念如下:
- 光流向量:每个像素都有一个光流向量,表示在两个连续图像帧之间的运动。光流向量包括水平和垂直的分量,通常表示为(dx,dy)。
- 光流估计算法:光流估计算法通过比较两个图像帧中的像素强度值来计算光流向量。其中,常用的算法包括Lucas-Kanade、Horn-Schunck等。
4.2 视差法运动估计:
视差法运动估计使用视差信息来估计相机的运动,包括平移和旋转。基本概念如下:
- 视差法:视差法通过比较两幅图像中相同物体的视差信息来估计相机的位移。通过视差值的计算,可以得到相机的平移和旋转。
- 三维重建:一旦获得视差信息,可以使用三角测量等技术来进行三维重建,从而得到场景中物体的位置和运动。
4.3 基于特征的运动估计:
基于特征的运动估计使用特征点,如角点或SIFT特征点,来跟踪图像帧之间的运动。基本概念如下:
- 特征点检测:首先,需要检测图像中的特征点,这些点在连续帧之间容易跟踪。
- 特征点匹配:在相邻图像帧之间匹配特征点,以计算它们的位移。
- 运动估计:根据特征点的位移信息,可以估计相机的运动,包括平移和旋转。
示例场景和代码:
假设我们有一对连续图像帧,我们想要使用Lucas-Kanade算法进行光流估计。
import cv2
# 从两个连续图像帧中加载图像
frame1 = cv2.imread('frame1.png', cv2.IMREAD_GRAYSCALE)
frame2 = cv2.imread('frame2.png', cv2.IMREAD_GRAYSCALE)
# 创建Lucas-Kanade光流估计器对象
lk_params = dict(winSize=(15, 15), maxLevel=2, criteria=(cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 0.03))
p0 = cv2.goodFeaturesToTrack(frame1, mask=None, maxCorners=100, qualityLevel=0.3, minDistance=7)
# 使用Lucas-Kanade算法计算光流
p1, st, err = cv2.calcOpticalFlowPyrLK(frame1, frame2, p0, None, **lk_params)
# 画出光流轨迹
for i, (new, old) in enumerate(zip(p1, p0)):
a, b = new.ravel()
c, d = old.ravel()
cv2.line(frame2, (a, b), (c, d), (0, 0, 255), 2)
cv2.circle(frame2, (a, b), 5, (0, 0, 255), -1)
cv2.imshow('Optical Flow', frame2)
cv2.waitKey(0)
cv2.destroyAllWindows()
在这个示例中,我们使用OpenCV中的Lucas-Kanade算法来估计两个连续图像帧之间的光流,并在第二个帧上画出光流轨迹。
5.1 卷积神经网络(CNN):
卷积神经网络是一类专门用于图像处理和视觉任务的深度学习模型。在视差估计和运动估计中,CNN被广泛应用。基本概念如下:
- 卷积层:CNN的核心是卷积层,它可以有效地学习图像中的特征。卷积层通过卷积操作提取图像的局部特征,以便后续层次可以更好地理解图像。
- 深度结构:CNN通常包括多个卷积层、池化层和全连接层。这些层次的结合使得网络能够逐渐提取和理解图像中的抽象特征。
- 训练:CNN的训练通常涉及到大量的标记数据和反向传播算法。通过反复迭代,网络可以学习到从输入图像到目标输出(如视差图或运动向量)的映射。
5.2 深度学习框架:
深度学习框架是用于构建、训练和部署深度学习模型的软件工具。两个流行的深度学习框架是TensorFlow和PyTorch。基本概念如下:
- TensorFlow:TensorFlow是由Google开发的深度学习框架,具有强大的生态系统和社区支持。它提供了各种高级API和工具,用于构建深度学习模型。
- PyTorch:PyTorch是由Facebook开发的深度学习框架,以其动态计算图和易用性而闻名。它在研究和实验中广泛使用,支持动态图和静态图两种计算图。
示例场景和代码示例:
假设我们希望使用PyTorch构建一个简单的CNN模型来进行图像深度估计。以下是一个示例代码:
import torch
import torch.nn as nn
# 定义一个简单的CNN模型
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)
self.relu1 = nn.ReLU()
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.relu2 = nn.ReLU()
self.fc = nn.Linear(64 * 32 * 32, 1) # 输出深度估计值
def forward(self, x):
x = self.relu1(self.conv1(x))
x = self.relu2(self.conv2(x))
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
# 创建模型实例
model = SimpleCNN()
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练模型(假设有训练数据和标签)
for epoch in range(num_epochs):
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
这个示例中,我们使用PyTorch定义了一个简单的CNN模型来进行深度估计。然后,我们定义了损失函数和优化器,并进行了模型训练。
6.1 SLAM(Simultaneous Localization and Mapping)中的双目相机
SLAM是一种高度复杂且关键的技术,用于在未知环境中实现自主定位和地图构建。在SLAM系统中,双目相机发挥了以下关键作用:
定位(Localization):
双目相机通过捕捉环境中的图像信息,能够精确地确定相机的位置和方向。这是通过比较左右相机的图像之间的视差来实现的。通过计算视差,系统可以估算出相机相对于已知地图的位置,从而实现定位。
地图构建(Mapping):
与定位相辅相成的是地图构建。双目相机可以捕捉环境中的立体图像,从而实现三维地图的构建。通过不断地捕捉图像并计算深度信息,SLAM系统可以构建出一个实时更新的地图,其中包含了环境中的各种物体和障碍物的位置和形状。
实时性和稳定性:
双目相机能够提供更多的深度信息,相较于单目相机,从而提高了SLAM系统的实时性和稳定性。这对于实时定位和地图构建非常关键,尤其是在复杂的室内和室外环境中。
6.2 自动驾驶中的双目相机
在自动驾驶领域,双目相机也发挥着关键作用,用于环境感知和车辆控制。以下是双目相机在自动驾驶中的关键作用:
环境感知:
双目相机可以捕捉道路和周围环境的立体图像,以识别道路标志、交通信号、行人、车辆和其他障碍物。这种立体视觉能力使车辆能够更准确地理解其周围环境,从而做出更明智的驾驶决策。
路况分析:
通过分析双目相机捕捉的立体图像,自动驾驶系统可以检测道路上的各种路况,例如道路状况(湿滑、坎坷等)、交通拥堵、行车线和交汇处等。这有助于车辆选择最佳的行驶路径和速度。
车辆控制:
双目相机提供的深度信息对于车辆控制至关重要。它可以用于实现自动驾驶车辆的跟随车距控制、避障、自动停车和自动变道等关键功能。相机捕捉到的视觉信息使车辆能够在各种复杂交通情况下安全驾驶。
企业中主要运用场景:
假设你正在开发一个无人机,需要使其具备避障能力。你可以使用双目相机来感知周围环境,并估计无人机与障碍物之间的距离和运动关系。通过分析双目相机的图像,生成视差图,然后使用运动估计算法,例如光流估计或基于视差的运动估计,来实时检测障碍物并规划无人机的飞行路径,以确保安全避障。
7.1 双目相机运动估计
7.1.1 相机测距流程
相机测距是指通过相机捕获的图像信息来估计物体到相机的距离或深度的过程。通常,相机测距包括以下流程:
- 图像捕获:使用双目相机同时捕获左右两个图像。
- 特征点提取:从左右图像中提取特征点,这些特征点在两个图像中具有对应关系。
- 匹配:匹配左右图像中的特征点,以确定它们在不同图像中的位置。
- 三角测距:使用已知的相机参数和特征点的位置信息来估计物体的深度。
- 深度图生成:将估计的深度信息转化为深度图,每个像素表示物体到相机的距离。
- 后处理:对深度图进行滤波和去噪处理,以获得更准确的深度信息。
7.1.2 双目相机成像模型
双目相机成像模型是用于描述双目相机成像过程的数学模型。它包括左右两个相机,每个相机有自己的内参矩阵和外参矩阵。双目相机成像模型通常使用立体几何学的原理来描述两个相机之间的关系。
7.1.3 极限约束
极限约束是双目视觉中的重要概念,它描述了两个相机之间的特征点在空间中的关系。极限约束用于将特征点的匹配问题转化为一个几何约束问题(几何约束问题是一种在计算机辅助设计(CAD)和计算机图形学中常见的问题,涉及到在设计和建模过程中对物体或形状施加的几何约束,以确保它们满足特定的几何关系。这些约束用于控制物体之间的相对位置、大小和方向,以便在设计和建模过程中保持一致性和准确性),从而实现深度估计。
7.1.4 双目测距的优势
双目相机测距具有以下优势:
- 相对于单目相机,双目相机提供了更多的深度信息,因此能够更准确地估计物体的距离。
- 双目相机可以克服单目相机在纹理较弱或低对比度条件下的测距困难。
- 双目相机可以消除部分遮挡问题,因为两个相机可以看到不同的视角。
7.1.5 双目测距的难点
双目相机测距也面临一些难点和挑战:
- 需要精确的相机标定,包括内参和外参的准确估计。
- 特征点匹配需要高效的算法和鲁棒性,尤其是在纹理较弱或光照变化明显的情况下。
- 误差传播问题:深度估计的误差会传播到三维重构中,因此需要考虑误差的影响。
7.1.6 案例实现
以下是一个简化的Python示例代码,演示了如何使用OpenCV库进行双目相机测距的实现:
import cv2
import numpy as np
# 读取左右图像
left_image = cv2.imread('left_image.png', cv2.IMREAD_GRAYSCALE)
right_image = cv2.imread('right_image.png', cv2.IMREAD_GRAYSCALE)
# 配置双目相机参数
# 这包括相机内参、外参、相机位姿等信息
# 创建立体BM匹配器
stereo = cv2.StereoBM_create(numDisparities=16, blockSize=15)
# 计算视差图
disparity = stereo.compute(left_image, right_image)
# 计算深度图
depth_map = 1.0 / disparity
# 后处理:滤波和去噪
depth_map_filtered = cv2.medianBlur(depth_map, 5)
# 显示深度图
cv2.imshow('Depth Map', depth_map_filtered)
cv2.waitKey(0)
cv2.destroyAllWindows()
其他:可以了解的知识点:
雷达测距
雷达测距是一种使用雷达技术来测量目标距离的方法。雷达(Radio Detection and Ranging)是一种利用电磁波进行目标探测和距离测量的技术。雷达系统通过发射射频信号,并接收目标反射回来的信号来实现测距。
雷达测距的原理基于射频信号的传播时间。当雷达发射射频信号时,它会在空间中传播,并在遇到目标时发生反射。雷达接收到目标反射信号后,可以通过测量信号的到达时间来计算目标的距离。
雷达测距的应用十分广泛。它被用于气象观测、航空导航、军事侦察、交通管理等领域。在自动驾驶汽车中,雷达测距被用于检测和跟踪周围车辆和障碍物,以实现安全的驾驶。
示例代码:
import numpy as np
# 定义雷达参数 ,这边正常会有传感器的的接口调用,然后得到数值
speed_of_light = 299792458 # 光速,单位:米/秒
transmit_frequency = 24e9 # 发射频率,单位:赫兹
time_of_flight = 10e-6 # 信号往返时间,单位:秒
# 计算目标距离
target_distance = (speed_of_light * time_of_flight) / (2 * transmit_frequency)
print("目标距离:", target_distance, "米")
在这个示例中,我们使用了雷达的参数和信号往返时间来计算目标的距离。这个距离表示目标与雷达之间的距离。
请注意,这只是一个简单的示例,实际的雷达系统可能涉及更复杂的信号处理和计算方法。
相关概念
- 单目相机测距(Monocular Camera Distance Estimation):单目相机测距是一种使用单个相机来估计目标距离的方法。通过在图像中测量目标的大小或使用其他视觉特征,可以推断目标与相机之间的距离。这种方法常用于计算机视觉和机器人技术中。
- 双目相机测距(Stereo Camera Distance Estimation):双目相机测距是一种使用双目相机来测量目标距离的方法。通过测量两个相机之间的视差,可以计算目标与相机之间的距离。双目相机测距常用于计算机视觉、机器人导航和三维重建等领域。
- 激光测距(Laser Distance Measurement):激光测距是一种使用激光技术来测量目标距离的方法。通过发射激光束并测量激光束的时间往返,可以计算目标与激光测距仪之间的距离。激光测距常用于建筑测量、工业检测和地质勘探等领域。
视觉配准
概念:
- 图像配准(Image Registration): 图像配准是将多个图像对齐,以便进行比较、融合或分析的过程。它可以涉及到水平(行)和垂直(列)对准以及变换参数的估计。
- 行对准(Horizontal Alignment): 行对准是将图像在水平方向(即行)上对齐的过程,通常涉及到平移操作。
- 列对准(Vertical Alignment): 列对准是将图像在垂直方向(即列)上对齐的过程,通常也涉及到平移操作。
- 变换参数估计(Transformation Parameter Estimation): 这是确定如何将一个图像与另一个图像对齐的关键步骤,涉及到平移、旋转、缩放和扭曲等变换参数的估计。
算法:
- 基于特征点的配准(Feature-Based Registration): 这种方法使用图像中的特征点(如角点、SIFT或SURF特征)来找到对应关系,并估计变换参数。常用的算法包括 RANSAC、Lucas-Kanade 等。
- 基于亮度特征的配准(Intensity-Based Registration): 这种方法使用图像的亮度信息来匹配像素,并估计变换参数。常用的技术包括亮度相关性、最小二乘法等。
- 多尺度配准(Multiscale Registration): 对于大幅度变换的图像,通常需要多尺度策略来逐步逼近最优配准。例如,金字塔配准方法。
示例代码:
下面是一个基于Python和OpenCV的示例代码,演示了如何进行图像的行对准和列对准,并估计平移变换参数:
import cv2
import numpy as np
# 读取两张图像
image1 = cv2.imread('image1.jpg', cv2.IMREAD_GRAYSCALE)
image2 = cv2.imread('image2.jpg', cv2.IMREAD_GRAYSCALE)
# 行对准
height_diff = image1.shape[0] - image2.shape[0]
if height_diff > 0:
image1 = image1[height_diff // 2: -height_diff // 2, :]
else:
image2 = image2[-height_diff // 2: height_diff // 2, :]
# 列对准
width_diff = image1.shape[1] - image2.shape[1]
if width_diff > 0:
image1 = image1[:, width_diff // 2: -width_diff // 2]
else:
image2 = image2[:, -width_diff // 2: width_diff // 2]
# 估计平移变换参数
translation_matrix = np.float32([[1, 0, width_diff // 2], [0, 1, height_diff // 2]])
# 应用平移变换
result_image = cv2.warpAffine(image1, translation_matrix, (image1.shape[1], image1.shape[0]))
# 显示结果
cv2.imshow("Aligned Image", result_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
这个示例首先进行了行对准和列对准,然后估计了平移变换参数,并应用了平移变换,最后显示了对齐后的图像。
消除畸变
消除畸变是在图像处理中的一个重要步骤。畸变是由于相机镜头的特性所导致的图像失真。消除畸变的目的是尽可能准确地还原图像中的真实场景。
在相机标定过程中,可以获得相机的内部参数和畸变系数。这些参数可以用来对图像进行畸变校正。常用的畸变校正方法包括:
- 去畸变模型:使用相机的内部参数和畸变系数,可以构建去畸变模型。这个模型可以将图像中的畸变特征进行逆向变换,从而消除图像中的畸变。
- 畸变校正算法:畸变校正算法根据去畸变模型对图像进行处理,以消除畸变。常见的算法包括极坐标校正、透视校正、多项式校正等。
示例代码:
import cv2
import numpy as np
# 加载图像和相机内部参数
img = cv2.imread('distorted_image.jpg')
camera_matrix = np.array([[fx, 0, cx], [0, fy, cy], [0, 0, 1]])
dist_coeffs = np.array([k1, k2, p1, p2, k3])
# 进行畸变校正
undistorted_img = cv2.undistort(img, camera_matrix, dist_coeffs)
# 显示结果
cv2.imshow('Undistorted Image', undistorted_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
在这个示例中,我们使用OpenCV库提供的cv2.undistort函数对图像进行畸变校正。首先,我们加载图像和相机内部参数。然后,通过调用cv2.undistort函数,将图像进行畸变校正。最后,我们显示校正后的图像。
消除畸变后,图像中的直线和物体应该更接近现实场景,因为畸变校正可以还原相机镜头引起的失真效果。