目录
主要数据类型:
数据类型可以分为以下几类:整形、浮点型、自定义类型、数组类型
整形家族
整形家族的成员主要有:char类型、short类型、int类型、long类型以及c99还引入了long long类型。 注意:字符型因为本质是ASCII码值,所以是整形家族。
字节数
char类型又分为signed char, unsigned char;short类型又分为signed short,unsigned short;int类型 又分为signed int,unsigned int;long类型又分为signed long,unsigned long;同样的long long类型又分为signed long long, unsigned long long。
另外,char类型的字节数为1。
short类型的字节数为2。
int类型的字节数为4。
long类型的字节数可能为4,也可能是8。c语言在规定的时候,只规定了sizeof(long) >= sizeof(int);但是,在32位环境下,long类型是4个字节,而在64位环境下,long类型是8个字节。
long long类型的字节数是8个字节
signed 与unsigned
signed的意思是有符号。unsigned 的意思是无符号。
我们平常习惯用的int、short、long,C语言标准定义为signed, 也就是有符号的整形;而char类型,在c语言的标准中未定义,其默认是否位有符号还是无符号主要取决于编译器。
这里需要明确知道的是unsigned 是不能用来修浮点型的。因为浮点型是把内存中的第一个比特位默认为符号位。而unsigned 则是把内存中的第一个比特位默认为数据位。所以两者之间会发生冲突。所以,这里可以知道。signed或者unsigned 只是用来修饰整形的。
浮点家族
浮点家族的成员主要有:float类型、double类型。
浮点型就是用来存放小数的。这里float的精度小, 范围小;double的精度高,范围大。
构造家族(自定义类型)
主要有数组类型、结构体类型、枚举类型、联合体类型。
数组也是一种构造的数据类型。例如我们定义int a [5] = { 0 };
这里int [5]就是一种数据类型,他表示一块内存空间,这块内存空间里面有五个元素,每个元素是int。
下面再定义一种类型:int b [6] = { 0 };
这一种类型和上一种数据类型就不一样了,尽管他们的元素都是int, 但是这里的数据类型是int [6], 而上面的是int [5]。
指针家族
指针类型:int* 类型,float* 类型,char* 类型, short* 类型, void*类型等等。
空类型
空类型也就是void。它经常被用在函数的返回类型,函数的传参,以及指针地址的接收等等地方。
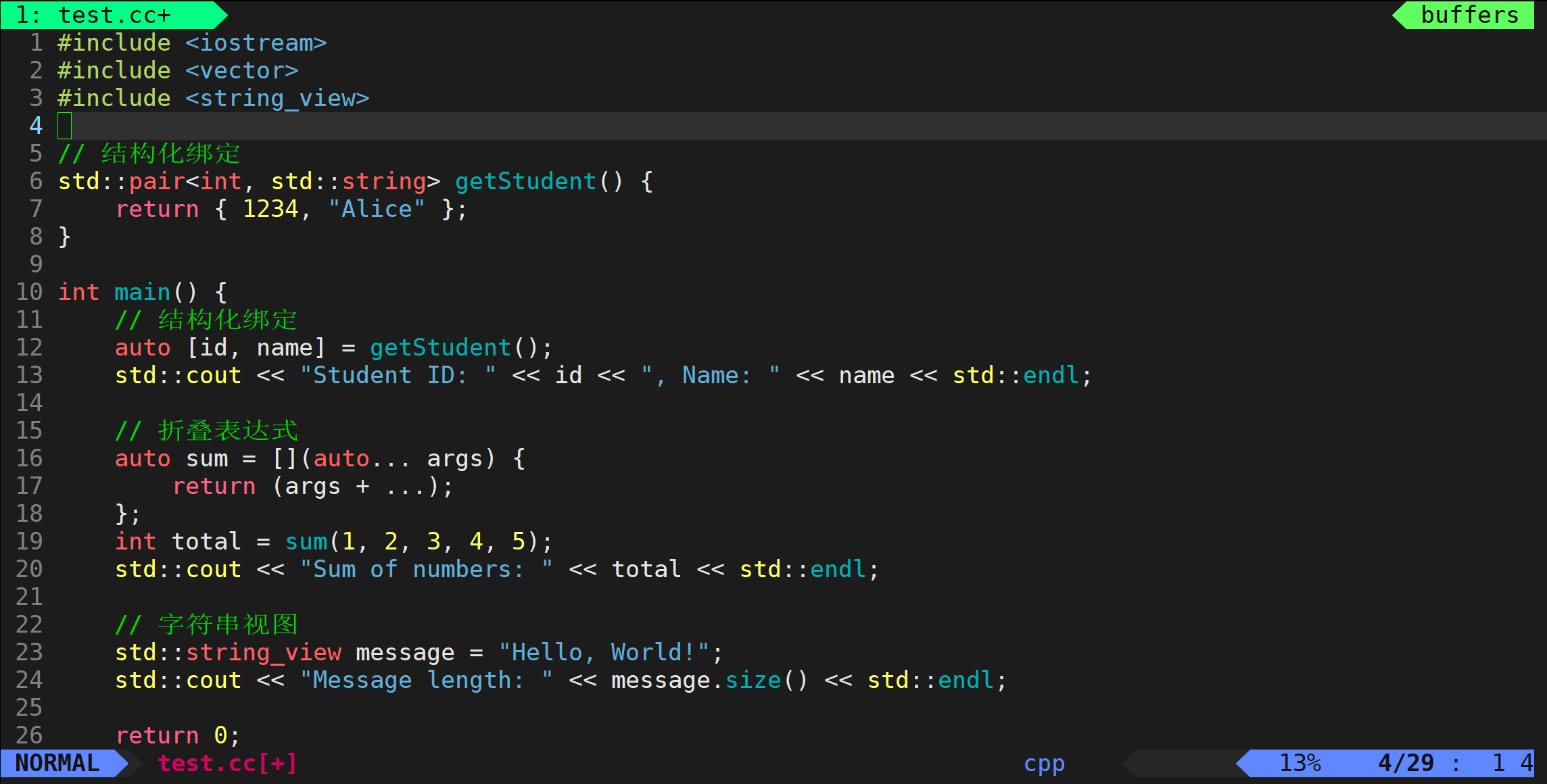
例如下面一串代码:

在这一串代码中,PrintA函数中,第一个void表示无返回值,第二个void表示不要传参。所以在调用PrintA函数的时候不需要进行传参。
下面是一个传址调用的例子。

在这里面,虽然传过去的是一个&a,也就是一个整形类型的地址。但是pa指针变量是空类型的指针 。所以结果虽然pa接收到了a的地址,但是这个过程中发生了强制类型转换。pa默认自己指向的是一个不完整类型的地址。
然后通过pa进行打印a的值:因为pa指向的是一个空类型的地址,所以不能访问。需要强制类型转换后才能进行访问。
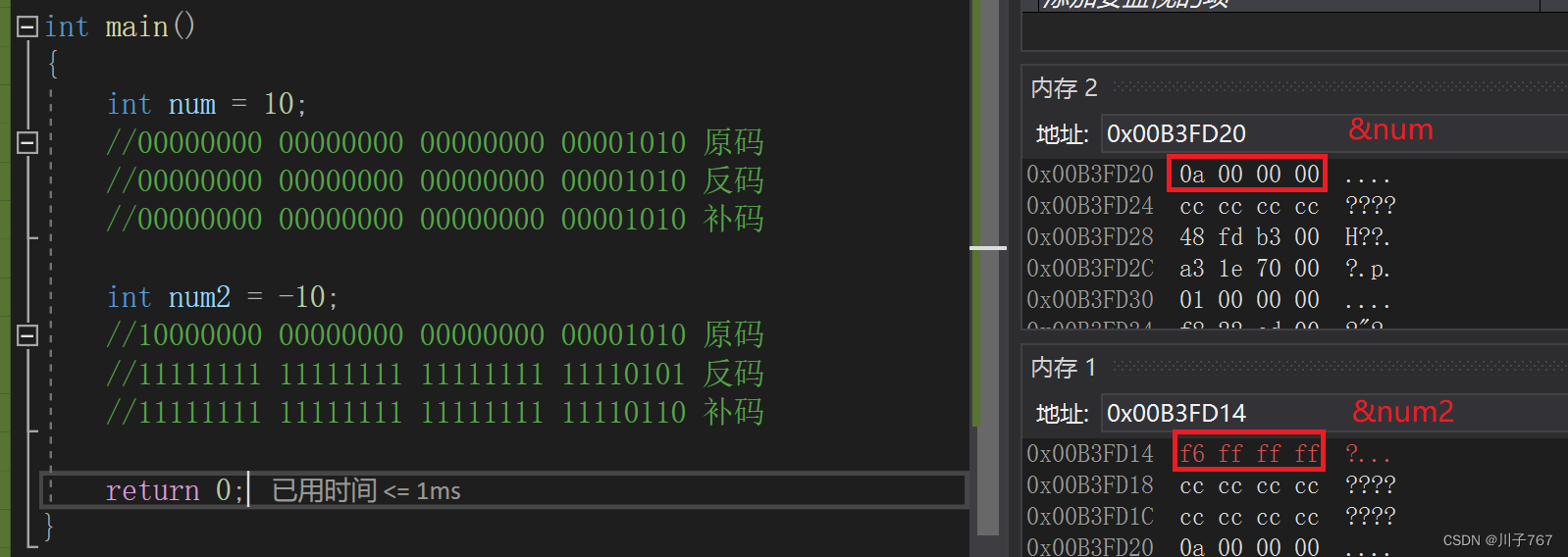
整形在内存中的存储方式
数据在内存中的存储方式是补码。整行类型的存储首先需要看是否有无符号,如果有符号,那么内存最高位是符号位。否则内存最高位就是数据位。
存储方式
整形数据的存储方式有原码,反码和补码。正数的原反补是相同的,都是我们平常看到的二进制序列。而负数的原码就是我们平常看到的二进制序列。反码是所该负数数据中的所有比特位按位取反,补码就是反码加一。
原码转化到补码是取反加一。补码转化到原码同样是取反加一。
有符号的存储:

无符号的储存:

范围大小
讨论char类型,char类型是1个字节。也就是八个比特位。如果是一个无符号类型char,那么八个比特位全部是数据位。数据可以储存的范围就是:0 ~ 255( 0 ~ 2 ^ 8 - 1)
如果是有符号类型的char,那么存储方式如下:

对于有符号整形来说,正数的原反补相同,数据在内存中的存储方式就是原码(原码与补码相同);而对于一个负数来说,负数的原反补是不相同的。数据在内存中的存储方式是补码,那么我们就需要通过计算,算出负数的原码。
那么无符号char:

int 类型等其他整型类型的存储方式类似。但是范围大小是不同的。例如short类型就有两个字节,16个比特位。有符号类型的short存储范围是 -32768 ~ 32767。无符号类型的short存储范围是0 ~ 65535.
为什么存储补码?
对于整形在内存中为什么以补码的形式进行存储的问题。其实是因为补码便于将符号位和和数值位进行统一处理。而且,我们的cpu只有加法器。而补码有利于我们对加法和减法进行统一的处理。
例如下面的 1 - 1计算

浮点在内存中的存储方式(待完善)
什么是浮点?浮点的表示形式是什么样的?
形如:1.25621或者1E10这样的就是浮点型。1E10是浮点型的科学计数法。表示1.0 * 10^10.
大小端问题
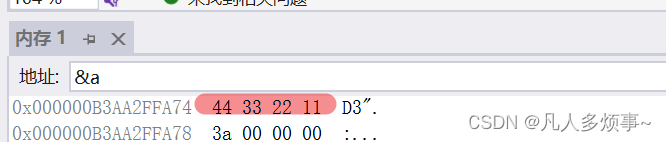
对于使用vs的朋友们,我们在调试观察内存时,可能会遇到这样的一个问题


就是我们会发现,数据在内存中的存储可能是反着存的。
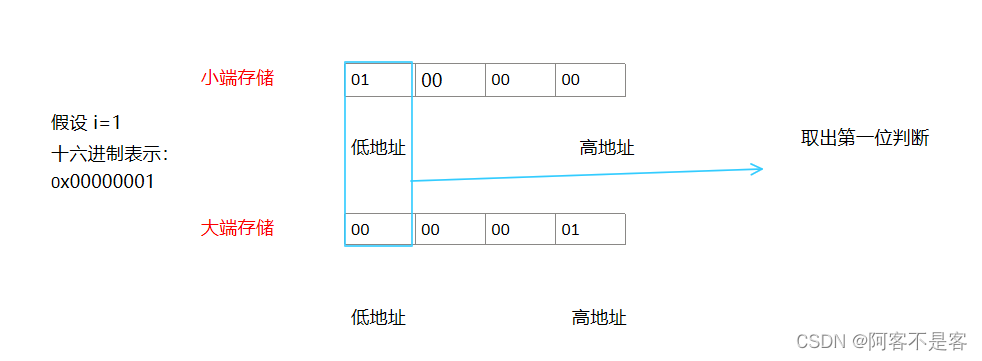
我们的a是0x11223344
但是到了内存中,保存的方式变成了44332211
这里就涉及到了大小端问题。
那么,什么是大小端存放,其实就是以内存为单位,数据在内存中的存储顺序问题。
我们都知道一个字节八个比特位,也就是两个十六进制位。
以下为十六进制表示数据,对于下面的存储方式进行讨论:
![]()



第一种方式我们可以看到低位字节序的数据存放在了高地址处,高位字节序的数据存放到了低地址处。这就是大端存储的方式。
第二种方式是低位字节序的数据存放到了低地址处,高位字节序的数据存放到了高地址处。这就是小端存储的方式。
第三种方式明显是乱序的。这种存储方式虽然也能对数据进行存储。但是编译器不会采取这种存储方式,因为过于复杂。
数据在内存中以字节为单位的存储顺序主要取决于编译器。一般就是大端存储,或者小端存储。
那么,我们怎么来判断我们的编译器到底是什么字节序存储方式呢?
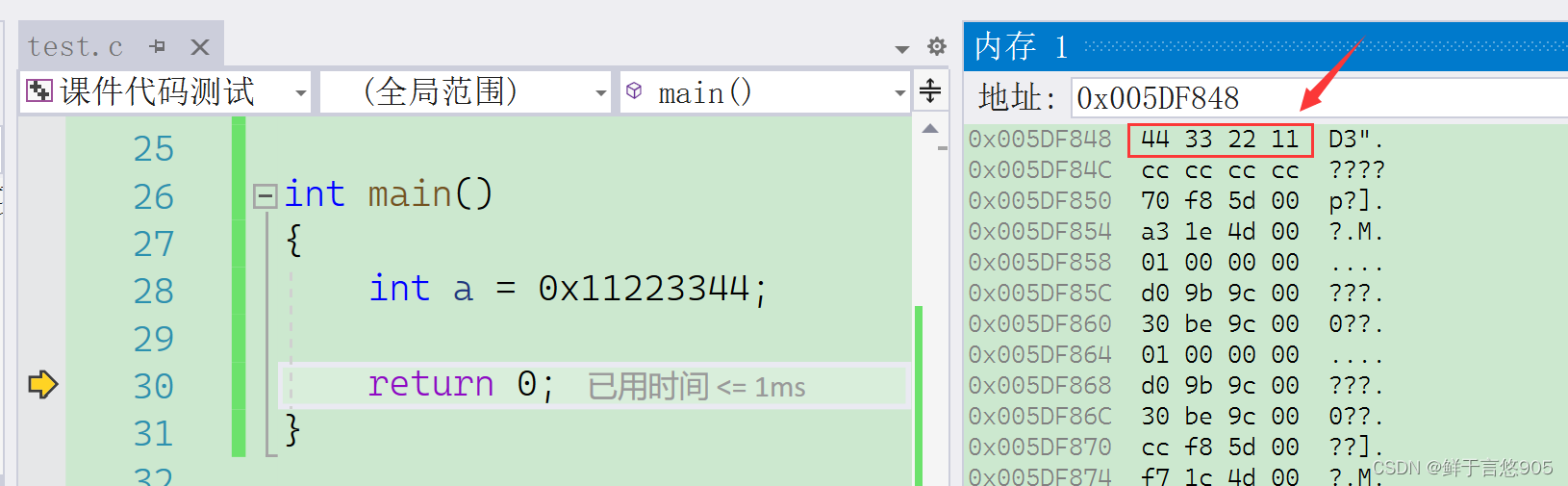
通过下面代码可以进行判断:

这个代码其实用到了指针访问与强制类型转换的问题。在函数为a开辟空间并将a的数据存入之后。通过一个指针只访问其单个字节序,来进行判断是大端字节序存储还是小端字节序存储。

经过检验,我们的vs2022是小端存储。





















![XCTF:MISCall[WriteUP]](https://img-blog.csdnimg.cn/direct/52ad12b02ad14ce6af2fcff31632441b.png)