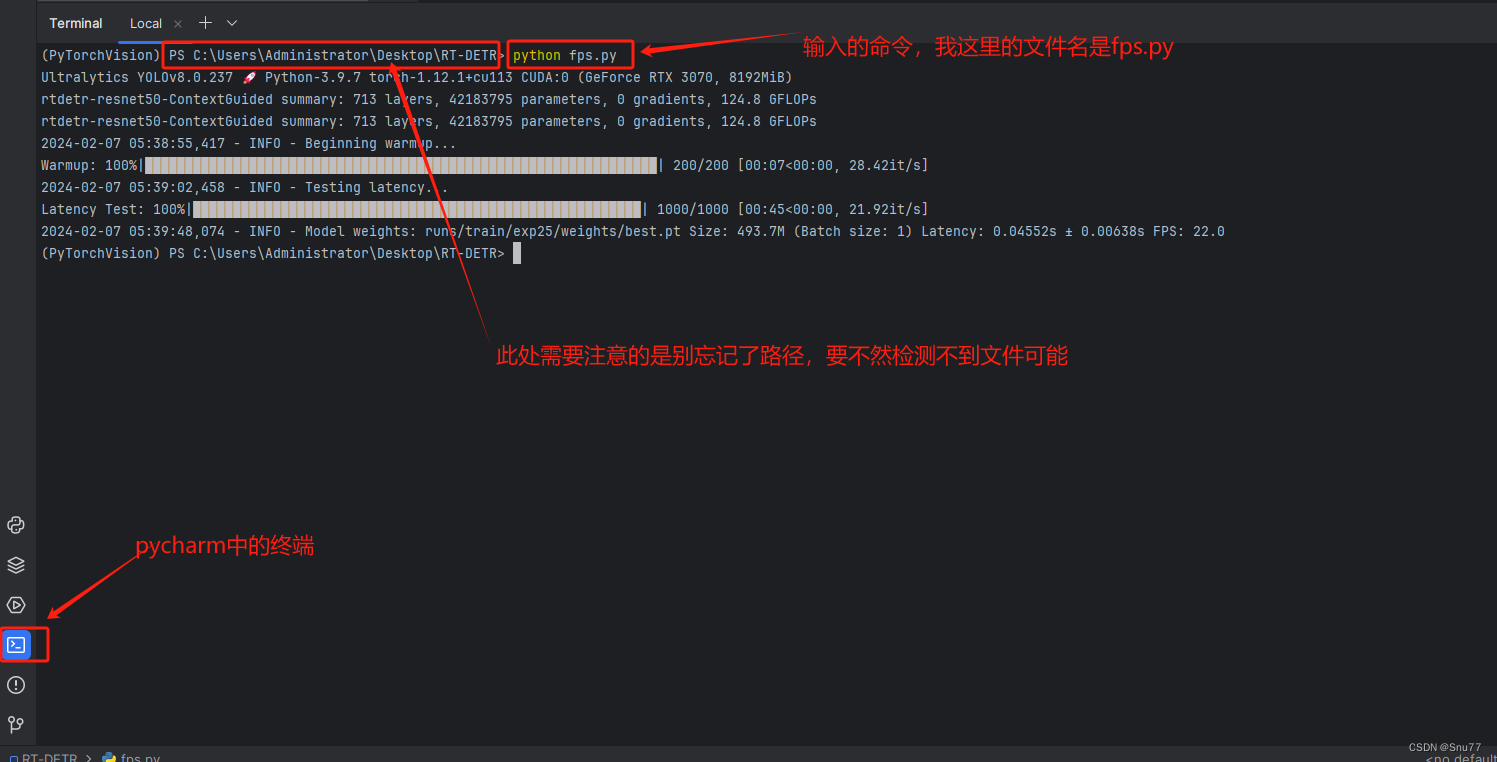
目录
类型的基本归类
1.整形家族:char short int long
2.浮点数家族:float double
3.构造类型:数组类型 结构体类型struct 枚举类型enum 联合类型union
4.指针类型:各种指针(包括 void*)
5.空类型:void
整形在内存中的存储

注:有符号和无符号只是针对整形的,浮点数是没有有符号和无符号这种说法的。char也属于整形,因此也分有符号char和无符号char。
对于short来说,short和signed short是等价的,int和long亦然,但是对于char来讲,如果只写一个char,是不确定他是有符号char还是无符号char,C语言语法并没有明确规定这个事情。在VS环境下char其实是有符号char。
有符号char和无符号char有什么区别?表示范围分别是什么?
对于有符号char来讲,他的八位只有七位是符号位,最高位是一个符号位,对于无符号char来讲,他的八位全都是数值位。
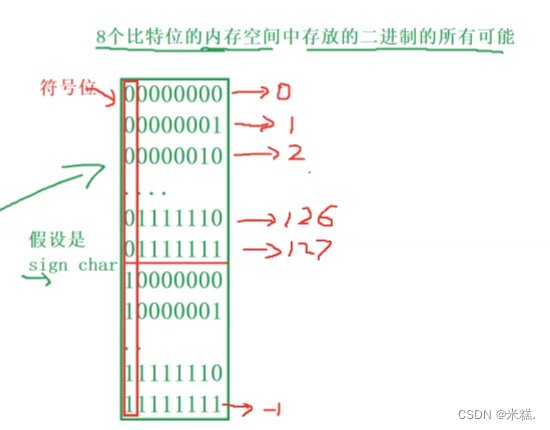
假设这是一个有符号char类型,那么最高位就是符号位,00000000~01111111范围就是0~127,再+1就成了10000000,看起来是-0,但是前面已经有了0,+0和-0没啥区别,因此我们规定有符号char里面的10000000的值是-128,这是规定。在往下看就是1开头的了,这些都是负数,负数在内存中以补码的形式存放,我们通过计算原码发现1开头的二进制序列范围是-1~-128。
综上所述,有符号char的范围是-128~+127
0再-1,就是0+(-1)先整型提升,补码相加之后是32个1,再发生截断,发现存的还是-1。
-1再+1,同样是先整型提升,补码是32个1和31个0一个1的二进制序列,补码相加之后发生截断,补码全为0,存的数就变成了0
也就是说有符号char的范围其实是一个循环,从0开始一直加的话加到127,再+1就变成-128,然后再一直加就会加到-1,再+1就变成了0。如图所示(这个图非常重要)

也可以理解为从-1开始减,减到-128的时候再减1就成了+127,接着从127开始减,减到0之后,再减一就成了-1。
注:有符号char的-1再+1变成0是因为发生了截断,127+1变成了-128是因为规定10000000是-128。
再看无符号char的范围

八位全是数值位,直接计算得到范围就是0~255。
所以有符号char的范围是-128~+127,无符号char的范围是0~255。
也就是说char类型的变量如果当前是127,再+1就会变成-128
同理可以计算出有符号short范围是-32768~32767,无符号short范围是0~65535。
练习:

答案:a=-1,b=-1,c=255
a是有符号char还是无符号char并不确定,因此我们先讨论b和c在内存中的存储情况,b是有符号char,-1是一个整数,他在内存中以补码的形式存储,其二进制序列为32个1,现在我们要把他放到一个char类型的变量里面,会发生截断,因此最终在内存a存储的是8个1,在打印的时候是按照%d的形式打印,表示打印十进制有符号整数,而b是一个char类型的变量,要发生整形提升,补符号位1直到32位,发现打印的时候b的补码其实和int类型的-1的补码是相同的,因此b的打印结果是-1(注:虽然负数存储的时候存的是补码,但是打印的时候呈现的是原码)再来看c,同样是把整数-1放到char类型的变量里面,会发生截断,因此c里面存放的是八个1,在打印的时候要发生整形提升,又因为c是一个无符号char类型的变量,因此高位补0至32位,且原反补相同,最终结果是255。最终我们打印发现打印结果分别是-1,-1,255,这说明此时编译器认为a是一个带符号char类型的变量。

%u表示以整数的形式打印无符号数,-128是一个整数,原码是10000000000000000000000010000000,补码是11111111111111111111111110000000,放到char类型的变量a里面要发生截断,因此a里面放的是10000000,打印的时候发生整型提升补符号位1至32位,并认为这是一个无符号数的补码,又因为无符号数的原码和补码相同,因此最终打印结果是一个非常大的数字。

虽然这里a要存的是128,但是发生截断之后实际存在a里面的补码和上面的-128是一样的,因此打印结果也是一样的,是一个非常大的数字。

先来看一下循环,这个循环显然是在给数组a进行初始化,第一次把下标为0的元素初始化成-1,第二次把下标为1的元素初始化成-2,以此类推最后把下标为999的元素初试化成-1000,但问题在于a是一个char [1000]类型的数组,他里面只能放char类型的元素,假如编译器是默认char位有符号char,那么char的范围就是-128~+127,是放不下-128以后的数的,会发生截断,-128再-1之后就变成了127,也即下标为128的元素实际上存的是127,下标为129的元素实际上存的是126,以此类推直到某个下标元素为0。再-1就会从-1开始,重复上述过程。strlen计算的是从因此最终打印结果为128+127=255
注:本题实际上就是有符号char那个重要图的逆时针版本
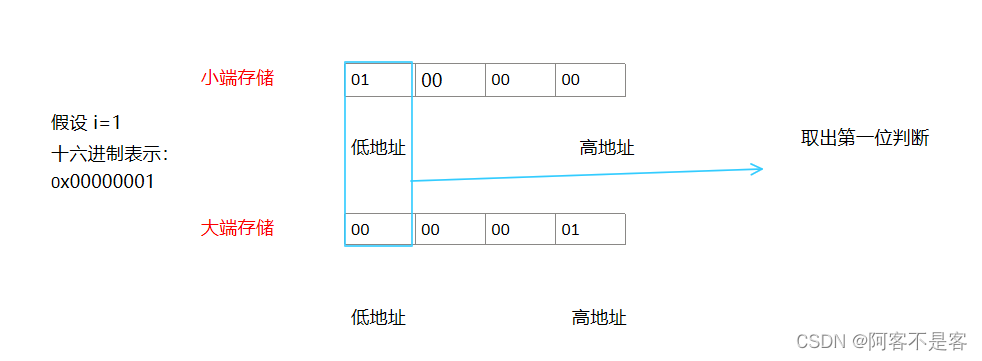
大端字节序存储与小端字节序存储
1.字节序:以字节为单位,讨论存储顺序
2.大端字节序存储:高位在低地址处
小端字节序存储:高位在低地址处
什么是高位?比如1234中1就是高位,4就是低位。
3.只有字节数超过一个字节的类型才讨论存储顺序,char类型的变量一共就一个字节,当然就不存在存储顺序的问题。
4.为什么会有大端和小端之分?
一个内存单元是一个字节也就是八个比特位,但是C语言中还有超过8个bit的int等等类型,这就涉及到了存储顺序的问题。因此有了大端字节序存储和小端字节序存储,大端字节序就是高位在低地址处,小端字节序存储就是高位在高地址处。
5.用代码判断当前机器是大端存储还是小端存储

只需要找一个足够简单的数字比如1,取出他的地址,然后拿到第一个字节内容看看是0还是1即可,但是a是一个int类型的变量,对他取地址是一个int*类型的指针,对他解引用是直接拿到4个字节内容,要想拿到1个字节内容,我们应该先把int*类型的指针强制类型转换成char*类型的指针。
对于大端字节序存储,第一个字节的内容就是0,对于小端字节序存储,第一个字节的内容就是1。
代码还可以使用函数方式实现

因为是规定小端就返回1,大端就返回0,又因为我们用来判断大小端的数字1本来就是小端拿到的第一个字节就是1,大端是0,因此我们直接返回第一个字节的内容即可。
浮点数在内存中的存储

运行结果如图所示

先来介绍一个错误的想法:首先把9放到了n申请的这块内存空间里面,第一次打印肯定是9,没问题,第二次打印是通过*pFloat,他仍然是访问这块空间,拿到的是9,但是打印的时候以%f形式打印,默认是小数点后六位,因此结果是9.000000,然后代码中把n指向的这块空间的内容改成了9.0,再次以%d形式打印,还是9,然后又以%f形式打印这块空间里的内容,应该是9.000000。这与我们的运行结果大相径庭,原因是以浮点数的形式往外取数据,和以整形的形式往外取数据是不一样的。

这其实就是二进制的科学计数法。
例如5.5的二进制序列是101.1,写成二进制的科学计数法就是1.011*2^2
也就是S=0,M=1.011,E=2,因为只要确定了S,M,E这三个数,就确定了一个浮点数的值,因此规定浮点数在内存中存储的时候存的是S,M,E这三个数。


第一位都是存S,因为S不是零就是一,没什么好说的。
然后存的是E,这个标准规定这个E是一个无符号整数(unsigned int),因此他只能表示正数,而二进制的科学计数法中E是有可能出现负数的,例如0.5写成二进制形式是0.1,再写成科学计数法是1*2^(-1),此时的E就是负数,为了应对这种情况,我们就不是直接把-1存到内存里面了,而是把-1+127=126存在内存里。同理对于64位的浮点数(double)E在存储的时候是先+1023再存进去。这个127和1023都是规定的。
注:不管E是正数还是负数,存的时候都要+127(或者1023)
然后是M,因为M是一个大于等于1小于2的数,也就是1.xxxxxxx,第一位永远都是1,因此存的时候可以把存1的这位拿出来,存后面的有效数字,这样精度更高,然后再读取的时候再把1还原回来即可。
例如5.5在内存中的存储应该是
1 10000001 01100000000000000000000
小数部分的101是直接存进去的,没有存1.101的第一个1,不够23位的用0补齐。
注:关于E
当E在内存中存的二进制序列有零有一,由于这个数是原来的E+127得到的,因此直接-127就能得到原来的E
当E在内存中存的二进制序列全为0,那么原来的E就是-127,则存储的浮点数就是-1的S次方*M*2的-127次方,这个数非常的小,这时候我们还原M的时候不在把舍掉的1还原回来,而是还原成0.xxxxxxxx
当E在内存中存的二进制序列全为1,这个二进制序列是255,因此原来的E是128,也就是说存储的这个浮点数是,-1的S次方*M*2的128次方,这个数非常的大,直接会被解读为正无穷或者负无穷。
再来看到前面的代码

变量n向内存申请了一块四字节的空间放上了9,其二进制序列为00000000000000000000000000001001,然后以整数的形式打印出来当然是9,第二次打印是通过*pFloat这个浮点数类型指针的形式打印的,这个指针指向的仍然是n申请的这块空间,里面存放的也还是这个二进制序列,但是站在这个浮点数类型指针的角度来看,他认为这个序列是个浮点数,因此第一位就是S,紧接着8位是E,在接下来的23位是M,因此S是0,E是0,M的有效小数是00000000000000000001001,当E全为零的时候还原M的时候是还原成0.xxxxx,因此存储的这个浮点数是(-1)^0*0.00000000000000000001001*2的-127次方,然后以%f的形式打印默认是打印前六位小数,因此打印的全是0.
再来看后两次打印,在打印之前先把9.0存到了内存中,而且是通过解引用一个浮点数类型指针存放进去的,存放的时候就是按照浮点数类型的存储规则来存放的,9写成二进制数是1001.0也就是(-1)^0*1.001*2^3,因此S是0,M是1.001,E是3(实际上在内存里存130),在内存中存的是
0 100000010 00100000000000000000000,然后以%d的形式打印,认为这是一个带符号整数,符号位是0,原反补相同,打印出来是一个非常大的数字,以%f的形式打印,认为这是一个浮点数,默认打印前六位,结果就是9.000000。
注:要想打印结果正确,应该遵循以什么样的形式存储,就以什么样的形式拿出,不能以浮点数类型存储却以整形形式打印。






























![[BUUCTF]-PWN:[极客大挑战 2019]Not Bad解析](https://img-blog.csdnimg.cn/direct/0905ed1af6134c44a1f6e4e0d19042a2.png)