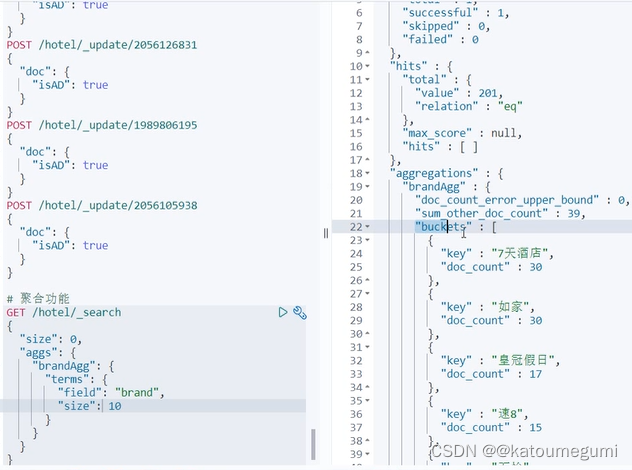
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

首个自回归的多模态模型,能够理解和生成图像、文本、音频和动作。为了统一不同的模态,将输入和输出——图像、文本、音频、动作、方框等,标记化到一个共享的语义空间中,然后使用单一的编码器-解码器变换模型来处理它们。由于训练如此多样化的模态极其困难,提出了各种架构改进以稳定模型。从零开始训练的模型,在一个大型多模态预训练语料库上进行训练,该语料库来源于多种渠道,使用多模态去噪目标混合。为了学习广泛的技能,比如遵循多模态指令,构建并微调了一个由120个现有数据集组成的集合,其中包括提示和增强。通过单一的统一模型,统一输入输出 2 在 GRIT 基准测试中实现了最先进的性能,并在包括图像生成与理解、文本理解、视频和音频理解以及机器人操控等30多个基准测试中取得了强有力的成绩。
它基于区区70亿参数构建,并经过大量多模态数据的精心训练(包括10亿图像-文本配对、1万亿文本标记,以及大量的视频、图像和3D内容)。在超过35个不同的基准测试中表现出色,统一输入输出 2 不仅仅是人工智能领域的一步,而是一大跃进,展示了多模态训练在理解和生成复杂、跨媒介内容方面的巨大潜力。
所有模型发布给研究社区。
详细的区看看: https://unified-io-2.allenai.org/ 和 https://github.com/allenai/unified-io-2





























![[机缘参悟-124] :实修 - 融汇贯通各种思想(道)和各种法门(术)](https://img-blog.csdnimg.cn/direct/063ff1b3c52c4ca292c0585cba7e5a08.png)

![[嵌入式软件][入门篇] 搭建在线仿真平台(STM32)](https://img-blog.csdnimg.cn/direct/ddfe49b5b0e54e52806fc1451b10a4e3.png)