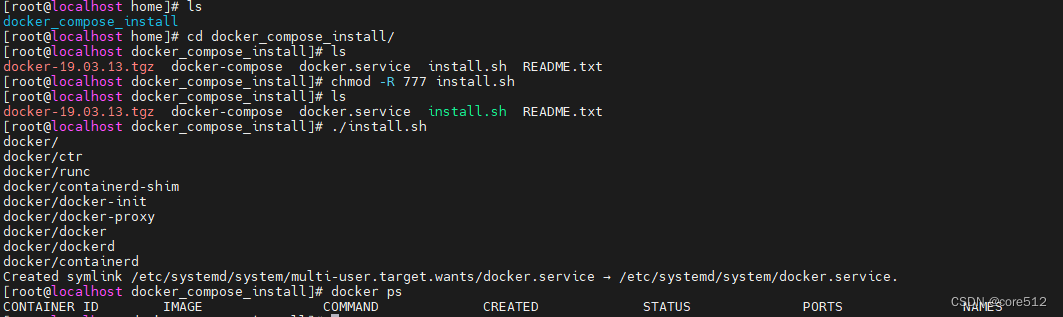
统计学介绍
统计学(statistics)是“数据的科学”
1.是用以收集数据、分析数据和由数据得出结论的一组概念、原则和方法。
2.统计学进行推断的基础是数据(data)。数据不仅仅限于数字,也可能是图表、视频、音频或者文字。
3.收集到数据之后,利用一些方法来整理和分析数据,最后得到结论。
统计学可以应用于什么领域呢?
统计学与各个学科的数据都有联系,可以应用于所有领域。
在网络、遥感、金融、电信、地理、商业、旅游、军事、生物医学等各个领域不断产生海量的数据。截至2016年年初,全球网民数量达到34亿,移动用户更是达到37.9亿,超过全球总人口的一半;中国的社交网络工具——微信,在2015年创下了月活跃用户破6.5亿的记录;2015年11月11日,阿里巴巴网上销售平台全天销售额达到创纪录的912亿元。庞大的互联网用户群体不停地生产着数据,这就是海量数据的源头。随着物联网的普及,全球所有设备都会为互联网贡献数据。

统计涉及两个阶段可以分为两个部分:描述统计学和推断统计学。
基本类型
总体( population):就是指问题所涉及的所有可能的个人、物体或度量的集合。 这些观察值有时是有限多个,有时也可以是无限多个(宇宙中的所有行星)。
统计学的目标是研究总体中包含的统计学规律。 然而,总体往往难以全部获得, 因此,我们从总体中抽取一部分观察值,通过研究它们的规律推理出总体的规律,这部分被抽取出来的观察值就是样本。
数据和变量
变量(variable)是一个可以取两个或更多可能值的特征或属性。
在收集数据进行统计分析之前,要给变量一个明确的适合研究目的的定义。这个过程并不容易。如果对问题考虑得不全面,那么就没有理由指望回答问题的人能按照我们的期望回答问题。因此,在做研究之前,对变量必须要有一个清晰的定义。
定量变量有连续型变量(continuous variable)和离散型变量(discrete variable),以及既有连续成份、也有离散成份的混合型变量。
离散型变量(discrete variable)只能取某些特定的值,并且不同取值之间通常都存在间距。通常,离散变量是通过计数得到的。
离散变量的例子包括具有某种特征的人口数(取正整数值)、某种事故发生的次数(非负整数)、足球射门次数、安静时的心率等。
连续型变量(continuous variable)的观测值可以遍取某一 区间中的任何值。通常,连续变量是通过测量得到的。身高、体重、热量、速度、长度等都是连续变量
数据是变量的观测值或者是试验结果。比如,身高是一个变量,测量一个人的身高,就好比一次试验,可观测到一次试验结果,即观测值(observation)。
一般所说的数据是一个集合名词,每一个数据包含很多观测值,每个观测值也称为一个数据点(data point,point)。 请注意,为了处理性别、籍贯等类似的数据,通常对类别进 行1,2,3等编码,以便于计算机的计数。
数据的测量水平一共有4个:
1.定类或分类(categorical data)
2.定序或有序(ordinal data)
3.定距或区间(interval data)
4.定比或比例(ratio data)。
数据的测量水平制约着在数据概括或显示时可以选用的计算方法,还决定了应使用何种统计检验方法
数据:采集方法四种方法:
(1)公开发表资料,(2)实验设计,(3)调查,(4)观察
数据抽样
在R中可以进行有放回、无放回抽样。
sample函数。sample的默认行为是无放回抽样,并且size不能超过被抽样向量的长度。如果想有放回抽样,那么需要加上参数replace=TRUE。
bootstrap重抽样法。该方法的基本思想是在原始数据的范围内做有放回抽样,样本量仍为n,原始数据中每个观测值每次被抽到的概率相等,为1/n,所得的样本为bootstrap。
如果想从1~100中随机取10个数字,那么可以写如下命令:
>sample(1:100,10)
[1] 45 100 65 59 91 36 10 94 70 22
sample(x,size)第一个参数(x)是一个被抽样的值向量,第二个参数( size)是抽样大小,并且size不能超过被抽样向量的长度
一个单个的数字就可以代表整数序列的长度,上述命令用sample(100,10)足够了
有放回抽样适用于扔硬币或掷骰子模型。比如,模拟10次扔硬币:
>sample(c("H","T"),10,replace=T)
[1] “T” “T” “H” “T” “T” “T” “T” “H” “T” “H”
有放回抽样适用于扔硬币或掷骰子模型。比如,模拟10次扔硬币:
>sample(c("H","T"),10,replace=T)
随机事件的思想显然不局限于对称情形,它同样适用于其他情形。如一个考试成功的结果,也许我们希望成功的机会超过50%时,可以通过使用 sample()函数中的prob参数模拟那种结果不具有相等概率的数据,如成功的可能性是85%,因此,可以使用如下命令:
>sample(c("成功","失败"),10, replace=T, prob=c(0.85,0.15))
[1] “成功” “成功” “成功” “成功” “失败” “成功” “成功” “成功” “成功” “成功”
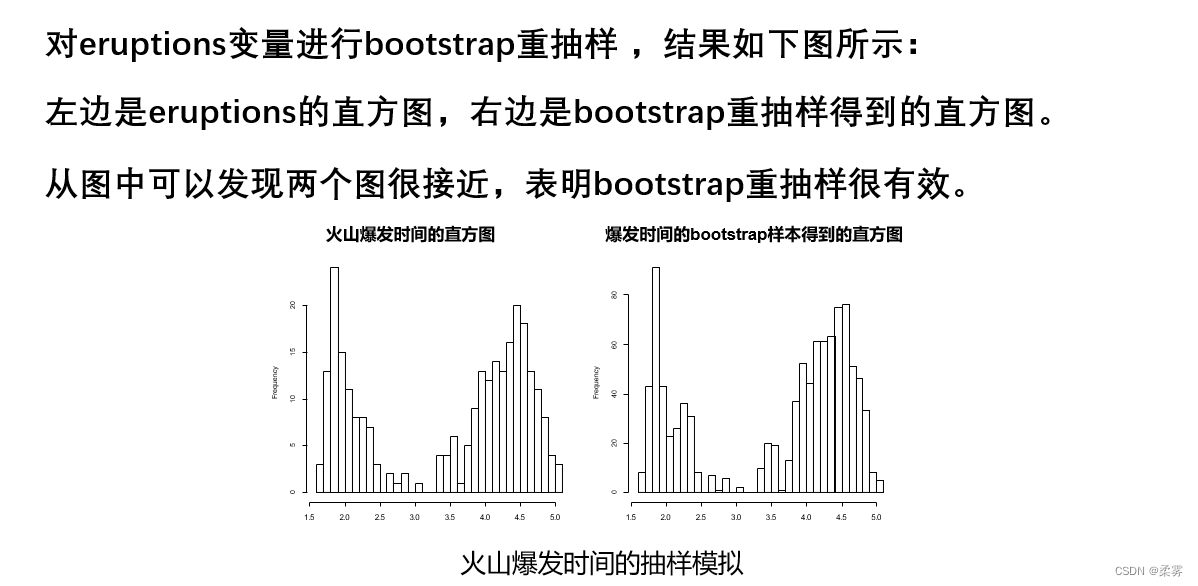
一个重要的有放回抽样方法就是 bootstrap重抽样法( resampling),它是美国统计学家 Efron于1982年发明的。
该方法的基本思想是在原始数据的范围内做有放回抽样,样本量仍为n,原始数据中每个观测值每次被抽到的概率相等,为1/n,所得的样本为bootstrap
以R软件自带的数据faithful中的变量eruptions为例。 eruptions变量记录了火山爆发的时间,属于不常见的分布,对它进行bootstrap重抽样 :
>attach(faithful) //获取数据集
>sample(eruptions,10,rep=T)
>b.sample=sample(eruptions,1000,rep=T)#抽取一个样本量为1000的bootstrap样本
>par(mfrow=c(1,2))
>hist(eruptions,breaks=25)
>hist(b.sample,breaks=25)
总结
1、举出你所知道的统计应用的例子(三个即可)。
统计学与各个学科的数据都有联系,可以应用于所有领域。
在网络、遥感、金融、电信、地理、商业、旅游、军事、生物医学等各个领域不断产生海量的数据。截至2016年年初,全球网民数量达到34亿,移动用户更是达到37.9亿,超过全球总人口的一半;中国的社交网络工具——微信,在2015年创下了月活跃用户破6.5亿的记录;2015年11月11日,阿里巴巴网上销售平台全天销售额达到创纪录的912亿元。庞大的互联网用户群体不停地生产着数据,这就是海量数据的源头。随着物联网的普及,全球所有设备都会为互联网贡献数据。
现在从各个领域中产生的数据量远远超过了人们对它们的分析和处理能力。把数据中的重要信息迅速、有效地提取出来是非常重要的。传统的数据库技术无法高效处理这些海量数据,那么就需要统计学结合以革命性的新处理模式,比如分布式文件系统GFS、HDFS;并行处理架构MapReduce和分布式数据存储系统Bigtable等。
数据挖掘、人工智能、机器学习等领域的出现对统计学、计算机科学及各个相关领域提出了更高的要求,同时也带来了机会和挑战。
2、解释定性数据和定量数据的区别,分别给出一个定性数据和一个定量数据的例子。
定性变量的取值称为水平(level)或者类(class)。比如,姓名、行业、出生地、国籍/地区以及汽车类型都是定性变量。
定量变量的例子比较多,比如年龄、寿命、公司的员工人数、薪水金额等。
3、列出测量的4个水平,写明一下每个测量水平的数据特征,表征形式,以及具有什么运算功能并对每个测量水平举出一个实例。
在统计学中,通常有四个测量水平,它们分别是名义(或分类)、顺序、间隔和比例水平。下面是每个测量水平的数据特征、表征形式以及运算功能,并举出了一个实例:
名义水平:
数据特征:名义水平是最基本的测量水平,用于对对象进行分类或分组,没有任何排序或数量关系。
表征形式:标签或符号,没有数值含义。
运算功能:主要用于计数和描述频数,不能进行数学运算。
实例:性别(男、女)是一个名义水平的变量。
顺序水平:
数据特征:顺序水平在名义水平的基础上添加了顺序或排序信息,表示项目之间的相对大小或顺序。
表征形式:可以使用整数或有序标记来表示不同的级别。
运算功能:可以进行排序、计算中位数、描述相对大小等。
实例:学生的成绩等级(A、B、C、D、F)是一个顺序水平的变量。
间隔水平:
数据特征:间隔水平在顺序水平的基础上添加了等距信息,表示项目之间的差异具有恒定的单位。
表征形式:使用数值来表示不同的级别,可以包含负数。
运算功能:可以进行加减运算、计算平均值、描述差异等。
实例:温度(摄氏度或华氏度)是一个间隔水平的变量。
比例水平:
数据特征:比例水平是最高级的测量水平,具有等距和绝对零点的特征,表示项目之间的差异具有恒定的单位,并且存在绝对意义上的零点。
表征形式:使用数值来表示不同的级别,包括零值。
运算功能:可以进行加减乘除运算、计算平均值和比率等。
实例:身高(厘米)是一个比例水平的变量。
4、下表是按收入五等分划分的我国农村居民平均每人纯收入数据(单位:元)
(1)在R中录入上表数据,并存为R格式
(2)将下述数据框转换为矩阵

(1)
names<-c("低收入户","中等偏下户","中等收入户","中等偏上户","高收入户")
a<-c(1500,2935,4203,5929,11290)
b<-c(1549,3110,4502,6468,12319)
c<-c(1870,3621,5222,7441,14050)
d<-c(2002,4256,6208,8894,16783)
e<-c(2316,4808,7041,10142,19009) #把数据以列向量的形式录入
f<-data.frame(指标=names,"2008年"=a,"2009年"=b,"2010年"=c,"2011年"=d,"2012年"=e) #把数据组织成数据框的形式
f
f<-edit(f)
save(f,file="C:/Users/125/Desktop/example/ch1/f.RData")

(2)
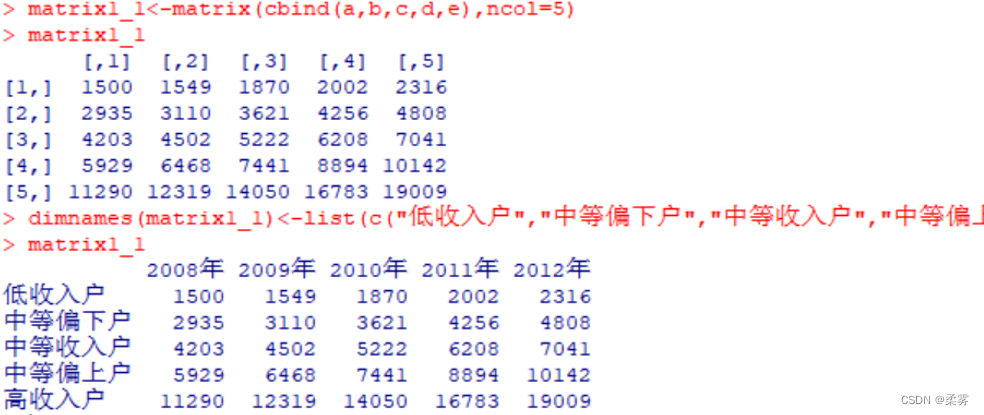
matrix1_1<-matrix(cbind(a,b,c,d,e),ncol=5) #使用matrix()函数将数据部分以列的形式合并
dimnames(matrix1_1)<-list(c("低收入户","中等偏下户","中等收入户","中等偏上户","高收入户"),c("2008年","2009年","2010年","2011年","2012年"))#命名,矩阵的行名称,列名称进行命名
matrix1_1