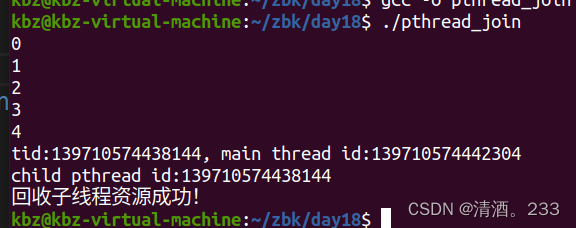
1. 什么是http请求
我们将通过发送http请求来获取网页内容。http是HyperText Transfer Protocol的缩写,意思是超文本传输协议,它是一种客户端和服务器之间的请求响应协议。
浏览器就可以看作是一个客户端,当我们在浏览器地址栏输入想访问的网址,按下回车后,浏览器就会像服务端发送一个http请求,然后等待服务器返回给浏览器响应。
http有多种不同的请求方法,最常见的是get和post。由于爬虫程序大部分都是在获取数据,所以我们发送的请求大部分情况下都用get方法。
2. 一个完整的http请求组成
一个http请求由三个部分组成:

请求行会包含方法类型、资源路径和协议版本等等
资源路径指明了我们将要访问服务器的哪个资源,资源路径后方也可以添加查询参数。

请求头会包含一些给服务器的信息,比如Host、User-Agent、Accept等等
Host 指主机域名,结合请求行里的路径资源,可以得到一个完整的网址。
User-Agent 用来告知服务器客户端的相关信息,比如请求是浏览器发出来的还是其他东西发出来的如果是浏览器的话,类型是什么、版本是什么等等。
Accept 是想告诉服务器客户端想接受的响应数据是什么类型的,接受多种类型的话,可以用逗号进行分隔,如果是
*/*表示什么类型都可以。请求体里面可以放客户端传给服务器的其他任意数据,但是
get方法的请求体一般是空的。
当服务端收到客户端传来的请求后,它会根据所有这些信息返回http响应,响应也由三个部分组成:

状态行包含了协议版本、状态码、状态消息
其中状态消息常见的有以下这些:

响应头会包含一些想要告知客户端的信息
Date 是生成响应的日期和时间。
Content-Type 返回内容的类型及编码格式。例如
text/html;charset=utf-8指响应类型是HTML,编码是utf-8。响应体里是服务端想要告知客户端的一些内容
比如如果前面的内容类型是HTML,这里返回的就是HTML内容。




















![[足式机器人]Part3 机构运动学与动力学分析与建模 Ch00-3(2) 刚体的位形 Configuration of Rigid Body](https://img-blog.csdnimg.cn/direct/aa377c21d07a4c6cabdb07b7f2663a3c.png#pic_center)