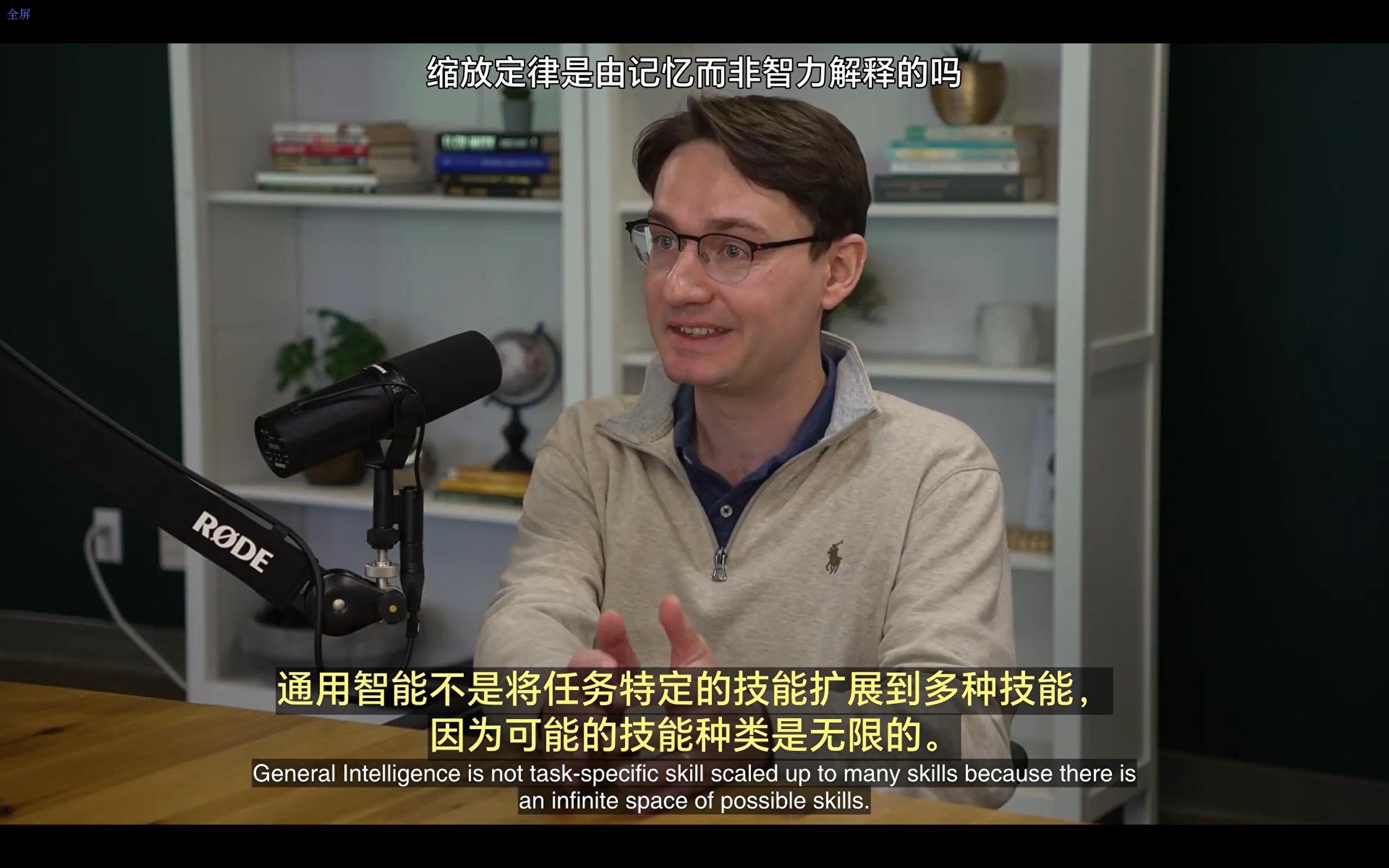
KM(Kaplan-McCandlish)缩放法则
KM缩放法则是由OpenAI的研究员Jared Kaplan和Sam McCandlish提出的,用于描述大型语言模型(LLMs)如何随着模型大小、数据量和计算资源的增加而提高性能。这个法则基于经验数据表明,模型性能(如测试集上的预测精度)随着模型参数的数量以及训练过程中使用的数据量和计算量的对数线性增长。
KM缩放法则的关键观点是,通过增加模型的大小和投入更多的计算资源,可以预测地改善模型的性能。这对于理解和预测大型语言模型的发展轨迹具有重要意义,帮助研究者和开发者在设计和训练这些模型时做出更明智的决策。
Chinchilla 缩放法则
Chinchilla 缩放法则是对KM缩放法则的一个重要补充。这个法则指出,对于给定数量的计算资源,存在一个最优的模型大小。这意味着简单地增加模型的大小并不总是最有效的做法,特别是在计算资源有限的情况下。相反,为了最大化性能,应该在模型大小和训练数据量之间找到一个平衡点。
Chinchilla 缩放法则的提出,对于如何有效地分配资源以训练大型语言模型具有重要意义。它强调了在有限的资源下优化模型性能的重要性,对于那些没有大量计算资源的研究者和小型企业来说尤其重要。
研究这些缩放法则的意义
研究KM和Chinchilla缩放法则对于理解和提高大型语言模型的性能具有重大意义。这些法则为模型设计和训练提供了指导原则,帮助研究者更高效地利用资源。通过遵循这些法则,可以在有限的计算资源下实现更高的性能,同时也为未来大型模型的发展提供了理论基础。
此外,这些研究有助于推动人工智能领域的进步,使得即使是资源较少的研究者和企业也能够开发出强大的语言模型,进而加速技术的普及和应用。




























![解决Typescript报错问题[亲测有效]](https://img-blog.csdnimg.cn/img_convert/347a3f0795efea63956f2dc9fc182160.png)


