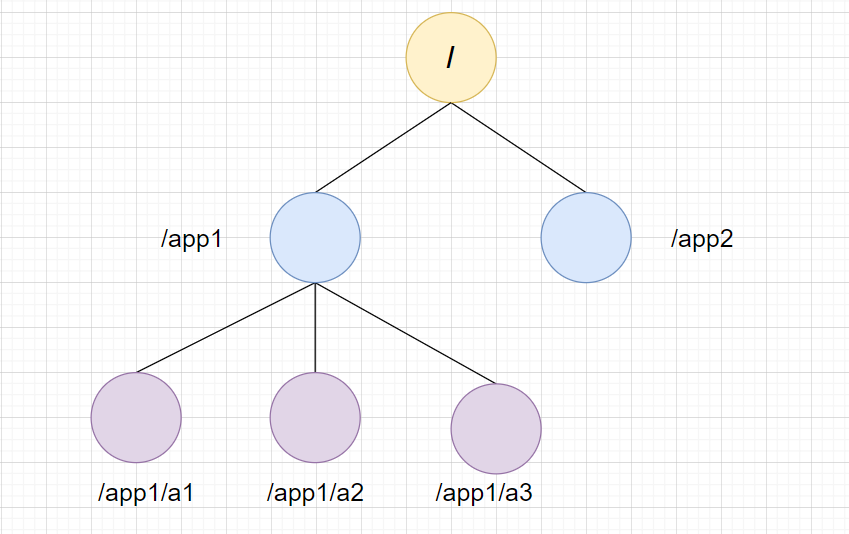
贝叶斯概率公式的组成
贝叶斯定理的概率公式:
P ( θ ∣ X ) = P ( X ∣ θ ) P ( θ ) P ( X ) P(θ|X)={P(X|θ)P(θ)\over{P(X)}} P(θ∣X)=P(X)P(X∣θ)P(θ)
先验分布 P ( θ ) P(θ) P(θ) :参数的先验分布是指在观测到新的数据之前,根据已有的知识或以往的经验对参数的估计。假如 P ( θ ) P(θ) P(θ) 为估计抛一次硬币中正面向上的概率,我们在不知道硬币质地是否均匀的情况下是不能确定这个概率的分布是什么样的,但可以利用经验推断,比如一般硬币都是均匀的,则可假设 P ( θ ) = 0.5 P(θ)=0.5 P(θ)=0.5 。或者像在Beta分布这篇文章里说过Beta分布可以描述 概率的概率密度分布 ,那么也可以假定 P ( θ ) P(θ) P(θ) 服从Beta分布。
似然函数 P ( X ∣ θ ) P(X|θ) P(X∣θ) : 已知参数的情况下,观测数据的概率分布。以抛硬币来说,在已知抛一次硬币正面向上的概率 θ θ θ 时,可得抛n次硬币中 X X X 次正面向上的概率分布,显然可以用二项分布来表示。
边缘概率 P ( X ) P(X) P(X) :也可称为全概率公式, P ( X ) = ∑ θ P ( X ∣ θ ) P ( θ ) P(X)=\sum_θP(X|θ)P(θ) P(X)=∑θP(X∣θ)P(θ) , P ( X ) P(X) P(X) 对后验分布的计算影响不大,可以当成一个系数。因此, P ( X ∣ θ ) P ( X ) P(X|θ)\over{P(X)} P(X)P(X∣θ) 也可以看作一个调整因子,后验分布=调整因子✖️先验分布,就是用观测数据将先验分布调整到更接近真实的分布,
后验分布 P ( θ ∣ X ) P(θ|X) P(θ∣X) : 后验分布是我们想通过贝叶斯定理得到的最终结果,表示的是在观测到新数据后对于参数的重新评估。计算后验分布的过程简单来说就是,在没有观测数据的时候,我们根据已有的知识或以往的经验赋予了参数一个估计,然后利用观测到数据,再对先验分布进行更新,最终得到后验分布,即在事件 X X X 发生之后,我们对参数 θ θ θ 的重新评估,因为 P ( X ) P(X) P(X) 可以当成一个系数,可得 P ( θ ∣ X ) ∝ P ( X ∣ θ ) P ( θ ) P(θ|X)∝P(X|θ)P(θ) P(θ∣X)∝P(X∣θ)P(θ)。
共轭先验与共轭分布
如果似然函数 P ( X ∣ θ ) P(X|θ) P(X∣θ) 可以使得先验分布 P ( θ ) P(θ) P(θ) 和后验分布 P ( θ ∣ X ) P(θ|X) P(θ∣X) 具有相同的分布,则称该先验分布为此似然函数的共轭先验。同时称后验分布 P ( θ ∣ X ) P(θ|X) P(θ∣X) 和先验分布 P ( θ ) P(θ) P(θ) 为共轭分布。比如Beta分布是二项分布似然的共轭先验。
贝叶斯推断与共轭先验的作用
如果要求解待估计量 θ θ θ ,可以利用贝叶斯推断,但需要先明确以下两项:一是要确定先验分布 P ( θ ) P(θ) P(θ) ,二是要确定基于 θ θ θ 的观测数据 X X X 的分布,即似然函数 P ( X ∣ θ ) P(X|θ) P(X∣θ) 。
但是通过贝叶斯推断的方法存在一些问题,会使后验分布并不容易计算:
为了找到最大的后验概率,需要为每个 θ θ θ 计算一次后验概率;
如果后验概率没有闭式解,则只能通过数值优化的方法来求最优解;
后验分布是处于动态更新过程中的,也就是说某次试验得到的后验分布,对于后续收集到的新观测数据而言又可以看作是一个先验分布。新的数据不断进来,模型需要一直更新,但贝叶斯推理中的计算量非常大,因此如果能利用共轭先验,计算会更加简便。
然而当我们知道后验分布和先验分布是共轭分布时,就可以跳过使用 后验分布=似然函数✖️先验分布 这步而直接利用先验分布来求得后验分布。
共轭分布举例
以抛硬币为例,对于一枚质地不知是否均匀的硬币,事先不知道抛一次正面向上的概率 θ θ θ ,我们可以通过多次抛硬币实验中正面向上次数 X X X 次来估计 θ θ θ ,即求后验分布 P ( θ ∣ X ) P(θ|X) P(θ∣X) 。
由贝叶斯推断可知,为了求 P ( θ ∣ X ) P(θ|X) P(θ∣X) ,需要知道:
- 先验分布 P ( θ ) P(θ) P(θ) ,即抛一次硬币正面向上的概率分布;
- 似然函数 P ( X ∣ θ ) P(X|θ) P(X∣θ) ,即已知硬币正面向上概率后抛n次硬币中出现 X X X 次正面向上的概率分布。
先验分布 P ( θ ) P(θ) P(θ)
目前我们对 P ( θ ) P(θ) P(θ) 还一无所知,但Beta分布可以描述 概率的概率密度分布 ,那么可以假设 P ( θ ) P(θ) P(θ) 服从Beta分布,用Beta分布作为参数 θ θ θ 的先验分布,概率密度函数表示为:
f ( θ ; α , β ) = 1 B ( α , β ) θ α − 1 ( 1 − θ ) β − 1 = Γ ( α + β ) Γ ( α ) Γ ( β ) θ α − 1 ( 1 − θ ) β − 1 ( 1 ) f(θ;\alpha,\beta)={1\over{B(\alpha,\beta)}}θ^{\alpha-1}(1-θ)^{\beta-1}={ {\Gamma(\alpha+\beta)}\over{\Gamma(\alpha)\Gamma(\beta)}}θ^{\alpha-1}(1-θ)^{\beta-1} \ \ \ \ \ (1) f(θ;α,β)=B(α,β)1θα−1(1−θ)β−1=Γ(α)Γ(β)Γ(α+β)θα−1(1−θ)β−1 (1)
其中 α 、 β \alpha、\beta α、β 是已知的形状参数,可以灵活控制图像的形状。
似然函数 P ( X ∣ θ ) P(X|θ) P(X∣θ)
对于似然函数 P ( X ∣ θ ) P(X|θ) P(X∣θ) ,即已知硬币正面向上概率后抛n次硬币中出现 X X X 次正面向上的概率分布,这个分布可以用二项分布来表示:
P ( X ∣ θ ) = ( n X ) θ X ( 1 − θ ) n − X = n ! X ! ( n − X ) ! θ X ( 1 − θ ) n − X , X ∈ [ 0 , n ] P(X|θ)=\binom{n}{X}θ^X(1-θ)^{n-X}={n!\over{X!(n-X)!}}θ^X(1-θ)^{n-X} \ , \ X∈[0,n] P(X∣θ)=(Xn)θX(1−θ)n−X=X!(n−X)!n!θX(1−θ)n−X , X∈[0,n]
假设此处出现 X = k X=k X=k 次正面向上,则似然函数 P ( X ∣ θ ) P(X|θ) P(X∣θ) 表示为:
P ( k ∣ θ ) = n ! k ! ( n − k ) ! θ k ( 1 − θ ) n − k ( 2 ) P(k|θ)={n!\over{k!(n-k)!}}θ^k(1-θ)^{n-k} \ \ \ \ \ (2) P(k∣θ)=k!(n−k)!n!θk(1−θ)n−k (2)
其中 θ 、 n 、 k θ、n、k θ、n、k 都是已知参数。
计算后验分布 P ( θ ∣ X ) P(θ|X) P(θ∣X)
由 P ( θ ∣ X ) ∝ P ( X ∣ θ ) P ( θ ) P(θ|X)∝P(X|θ)P(θ) P(θ∣X)∝P(X∣θ)P(θ) 及式 ( 1 ) 、 ( 2 ) (1)、(2) (1)、(2) 可得:
P ( θ ∣ k ) ∝ Γ ( α + β ) Γ ( α ) Γ ( β ) θ α − 1 ( 1 − θ ) β − 1 n ! k ! ( n − k ) ! θ k ( 1 − θ ) n − k ( 3 ) P(θ|k)∝{ {\Gamma(\alpha+\beta)}\over{\Gamma(\alpha)\Gamma(\beta)}}θ^{\alpha-1}(1-θ)^{\beta-1} {n!\over{k!(n-k)!}}θ^k(1-θ)^{n-k} \ \ \ \ \ (3) P(θ∣k)∝Γ(α)Γ(β)Γ(α+β)θα−1(1−θ)β−1k!(n−k)!n!θk(1−θ)n−k (3)
其中 Γ ( α + β ) Γ ( α ) Γ ( β ) {\Gamma(\alpha+\beta)}\over{\Gamma(\alpha)\Gamma(\beta)} Γ(α)Γ(β)Γ(α+β) 、 n ! k ! ( n − k ) ! {n!\over{k!(n-k)!}} k!(n−k)!n! 均与待估计参数 θ θ θ 无关,因此, 式 ( 3 ) (3) (3) 可进一步简化:
P ( θ ∣ k ) ∝ θ α − 1 ( 1 − θ ) β − 1 θ k ( 1 − θ ) n − k = θ α + k − 1 ( 1 − θ ) β + n − k − 1 ( 4 ) P(θ|k)∝θ^{\alpha-1}(1-θ)^{\beta-1} θ^k(1-θ)^{n-k}=θ^{\alpha+k-1}(1-θ)^{\beta+n-k-1} \ \ \ \ \ (4) P(θ∣k)∝θα−1(1−θ)β−1θk(1−θ)n−k=θα+k−1(1−θ)β+n−k−1 (4)
所以 P ( θ ∣ k ) P(θ|k) P(θ∣k)~ B e t a ( α + k , β + n − k ) Beta(\alpha+k,\beta+n-k) Beta(α+k,β+n−k)
在式 ( 4 ) (4) (4) 中令 α = α + k \alpha=\alpha+k α=α+k 、 β = β + ( n − k ) \beta=\beta+(n-k) β=β+(n−k) , k k k 是n次抛硬币中正面向上(成功)的次数, n − k n-k n−k 是n次抛硬币中反面向上(失败)的次数
则式 ( 4 ) (4) (4) 相当于由新观测数据更新为:
P ( θ ∣ k ) ∝ θ α − 1 ( 1 − θ ) β − 1 ( 5 ) P(θ|k)∝θ^{\alpha-1}(1-θ)^{\beta-1} \ \ \ \ \ (5) P(θ∣k)∝θα−1(1−θ)β−1 (5)
式 ( 5 ) (5) (5) 是不是很面熟,这不就是Beta分布吗,所以这里后验分布 P ( θ ∣ X ) P(θ|X) P(θ∣X) 和先验分布 P ( θ ) P(θ) P(θ) 为共轭分布,这也是为什么前面说Beta分布是二项分布似然的共轭先验。
知道了后验分布与先验分布是共轭分布后,就可以直接利用分布,在给定观测数据的情况下推断未知参数 θ 的分布情况,一般我们会选择后验分布概率密度函数曲线的峰值作为参数的估计值。