前言
本文分享“占用网络”方案中,来自CVPR2023的VoxFormer,它基于视觉实现3D语义场景补全。
使用Deformable Attention从图像数据中,预测三维空间中的体素占用情况和类别信息。
VoxFromer是一个两阶段的框架:
- 第一个阶段:预测每个像素的深度值,将像素投影三维空间中,2D图像到3D空间的思想。然后预测每个三维网格是否被占用,生成稀疏体素特征。最后选择其中是“占用”的体素,作为“体素查询特征”进入第二阶段。这个阶段只预测占用情况,选择一些值得分析的体素。
- 第二个阶段:根据一阶段提议的体素特征,生成体素Query,使用交叉注意力从3D体素Query到2D图像中查询融合特征的思想;然后使用掩码标记与自注意力,预测那些“没占用”的网格,补全得到完整的体素特征。后面接3D语义场景任务头,预测每个三维网格的类别情况。
论文地址:VoxFormer: Sparse Voxel Transformer for Camera-based 3D Semantic Scene Completion
代码地址:https://github.com/NVlabs/VoxFormer

一、框架思路
VoxFromer仅通过2D图像,不依赖点云数据,能预测完整的3D几何形状和语义信息。
它输入图像数据,默认是多视角图像数据,比如6个相机的。也可以只输入单张图像数据,单目相机场景。
- 第一阶段:通过预测图像中每个像素点的深度信息,结合相机内外参,投影到三维空间中。然后预测每个三维网格是否被占用,并选择状态是“占用”的体素,得到提议的3D体素Query。这样模型会选择一些值得分析的体素,进入下一阶段。
- 第二阶段-1:得到的提议的3D体素Query,使用交叉注意力,3D体素Query到2D图像中查询融合特征,生成进一步的3D体素Query'。(这里体素特征Query',表示图像中可见区域生成的,是有占用的;而不是被遮挡或空的空间)
- 第二阶段-2:然后使用自注意力,类似MAE的掩码预测,生成完整的体素特征。(基于提议的有占用体素特征,预测其它空间的情况,得到完整的体素特征)
最后输出3D语义场景信息,包含体素占用情况和类别信息。

Voxel Queries: 表示体素查询。其中,体素是三维空间中的一个立方体单元,可以想象为三维像素。
体素查询与注意力机制相结合,使模型能够专注于输入数据中的重要部分,然后进行提取特征。
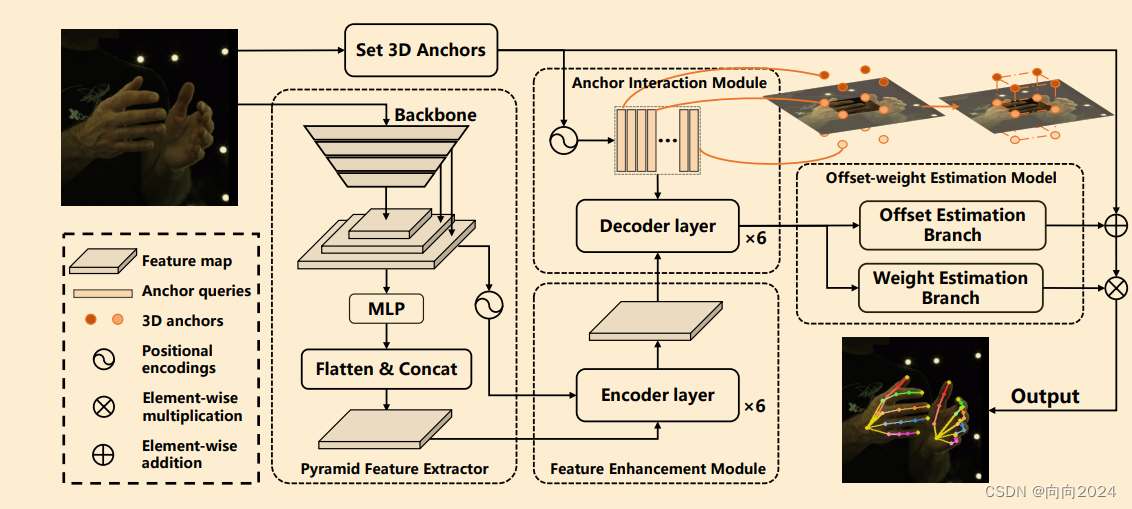
VoxFromer的详细的思路流程,如下图所示:
阶段一:
- 对图像中的每个像素,预测其深度值。结合相机内外参,投影到三维空间中,形成稀疏的3D点。
- 初始化一个体素查询矩阵Q,结合稀疏的3D点,对每个体素进行二元分类。当网格被占用时,预测为1;当网格没有被占用时,预测为0。图像中可见区域生成的,是有占用的;而不是被遮挡或空的空间。
- 设定数量Np,选择Np个最有可能是占用状态的网格特征,组成体素查询Qp。
- 这里选择其中是“占用”的体素,作为“体素查询特征”进入第二阶段。这个阶段只预测占用情况,选择一些值得分析的体素。
阶段二:
- 使用可变形交叉注意力,根据体素查询Qp,融合对应的图像特征。3D体素Query到2D图像中查询融合特征。
- 然后使用自注意力,类似MAE的掩码预测,生成完整的体素特征。基于提议的有占用体素特征,预测其它空间的情况,得到完整的体素特征。

Mask Tokens 掩码标记与体素查询一起使用,以帮助模型预测那些在点云数据中缺失但对于理解整体场景很重要的体素。
每个掩码标记都是一个可学习的向量,代表一个缺失体素的存在,而位置嵌入(positional embeddings)则确保掩码标记能够了解它们在3D空间中的位置。
二、核心内容——第一阶段(预测深度值、预测网格是否被占用)
第一个阶段主要包括:预测深度值、预测网格是否被占用。
一阶段详细步骤:
深度估计:从给定的二维图像中,使用深度估计模型来预测每个像素点的深度。结果是一个深度图,其中每个像素的值代表从相机到场景中相应点的距离。
体素化:利用这些深度信息,结合相机内外参,投影到三维空间的体素网格。每个体素是三维空间中的一个立方体区域,类似于二维图像中的像素点。
占用决策(深度修正):对于每个体素,根据其内部是否有从深度图中推导出的点来决定其占用状态。如果一个体素在其对应的深度图区域内有深度信息(即至少有一个像素点的深度信息指向该体素的空间区域),则该体素被标记为“占用”(通常用1表示)。如果没有深度信息指向该体素,它被标记为“空闲”(通常用0表示)。
二值化占用图:通过这种方式,可以生成一个二值化的占用图,这是一个三维网格,其中每个体素的值指示该区域是否被占用。
查询提案:接下来,系统会选择这些“占用”的体素进行进一步的处理,如特征提取或语义分割,在本文中是输入到第二阶段。在Class-Agnostic Query Proposal阶段,模型不区分体素类别,而是根据它们是否包含足够的信息(即是否占用)来选择哪些体素值得进一步分析。
有了每个像素的深度值后,可以利用相机的内外参,来将图像反投影至3D点云空间:

通过这种方法生成的3D点云在远距离区域特别是地平线附近的质量非常低,原因在于这些区域的深度极不一致。
此外,只有极少数像素决定了大片区域的深度,导致这些区域的点云相对稀疏。
为什么要做深度校正,也就是外什么还有用一个模型来预测每个网格是否占用?
深度修正背景:
- 在场景的远处,如地平线区域,因为在这些区域,相机捕捉到的深度信息往往因为距离过远而不准确或者分辨率不足。这种情况下,直接从图像像素得到的深度数据是不可靠的,需要进行校正。
- 地平线区域进行深度估计的问题通常是因为在这些远距离处,深度信息变得非常稀疏和不连续。在普通的二维图像中,地平线附近的物体通常比较小,因此在点云数据中,它们可能只对应非常少的点,甚至可能没有点。
解决方案:是使用一个模型来预测占用图,这是一个在较低空间分辨率下的二进制体素网格。每个体素表示一小块三维空间。
如果至少有一个点在该体素的空间范围内,则该体素在占用图中被标记为1,表示该区域被占用;如果没有点,则标记为0,表示未被占用。
这种占用信息有助于对深度信息进行修正,因为它提供了场景中哪些区域是空的,哪些是有物体的更明确的信息。
深度修正的思路流程:
- 使用深度估计模型从图像获取初步的深度信息。
- 将这个初步深度信息转换成一个低分辨率的体素网格,即占用图。
- 通过检查哪些体素被占用(至少有一个点),哪些没有被占用(没有点),来校正深度信息。这样可以修正因为分辨率不足或其他原因造成的误差。
详细步骤:
生成初步深度图:首先,利用深度估计模型(比如基于单目或立体视觉的深度估计网络)从二维图像中生成一个初步的深度图。这个深度图在远处尤其是地平线区域可能会存在较大的误差。
构建占用图:随后,将初步深度图转换为一个三维体素网格。这个过程中,每个体素根据是否存在对应的深度点被标记为占用(1)或未占用(0)。由于地平线区域的深度信息可能不连续,所以此时的体素网格是低分辨率的,也就是说,每个体素覆盖的空间较大,可以包含较多的潜在深度信息。
低分辨率修正:在低分辨率的占用图中,可以辨别出哪些区域是连续被占用的,哪些区域是空的。由于每个体素较大,即使远处的深度点非常稀疏,也更可能被检测到占用。然后,可以对那些在初步深度图中看起来是空的但在占用图中被标记为占用的区域进行深度修正。
插值和平滑:在确认了哪些大体素内的空间确实存在物体后,可以在这些区域应用插值或平滑技术来估计更准确的深度值。例如,如果一个大体素被标记为占用,而其内部的小体素深度值不连续,可以通过插值周围小体素的深度值来估计这些小体素的深度,使深度信息在大体素内部更加连续。
高分辨率细化:最后,使用这个经过低分辨率修正的占用图作为一个指导,可以在更高分辨率的深度图上进行细化,进一步提高深度估计的准确性。这可以通过在高分辨率深度图上应用从占用图中得到的占用信息来完成,进而优化整个场景的深度估计。
三、核心内容——第二阶段(交叉注意力、自注意力、生成完整的体素特征)
在第一阶段,系统已经生成了体素查询提案特征,表示这些体素值得进一步分析。
第二阶段是关于如何利用这些体素查询提案来提取丰富的图像特征,并对它们进行分割,区分不同类别的物体。
- 第二阶段-1:得到的提议的3D体素Query,使用交叉注意力,3D体素Query到2D图像中查询融合特征,生成进一步的3D体素Query'。(这里体素特征Query',表示图像中可见区域生成的,是有占用的;而不是被遮挡或空的空间)
- 第二阶段-2:然后使用自注意力,类似MAE的掩码预测,生成完整的体素特征。(基于提议的有占用体素特征,预测其它空间的情况,得到完整的体素特征)
首先使用ResNet以及FPN提取多尺度图像特征。使用可变形交叉注意力,根据体素查询Qp,融合对应的图像特征。3D体素Query到2D图像中查询融合特征。
然后使用自注意力,类似MAE的掩码预测,生成完整的体素特征。基于提议的有占用体素特征,预测其它空间的情况,得到完整的体素特征。
最后然后使用VoxFormeHead得到3D栅格预测,其中Attention均采用Deformable Attention。
体素Query'与图像特征的Cross Attention:通过将Query栅格的坐标投影到图像上,使用投影点作为Deformable Attention的参考点,并在这些参考点附近采样图像特征作为Value进行处理。
将每个查询网格的坐标投影到图像上,以这些投影点作为参考点。
然后,通过可变形注意力机制在参考点周围采样图像特征,这些特征随后被用作Transformer的Value。对于投影到多个图像帧的网格,将各帧的注意力输出进行平均,以合成最终特征。

体素Query''栅格与所有栅格的Self Attention:处理整个空间的栅格特征,对于非Query栅格使用mask token进行替代,并以栅格中心作为Deformable Attention的参考点。

四、VoxFormer实现细节
在第一阶段中:
深度估计:这一步骤使用深度感知网络,如MobileStereoNet或MSNet3D,从单幅图像或一对立体图像中估计出每个像素点的深度信息。此信息随后利用相机内部和外部参数被转换成三维空间中的点云数据,这通常是为了与现实世界的物理尺度对齐。
深度修正:直接从深度估计得到的点云数据往往包含噪声,为了提高数据质量,引入了基于3D网格的占据概率预测网络,使用了激光雷达SSC方法LMSCNet。该网络处理经过栅格化(将连续空间量化为离散的网格)的点云数据,输出更低分辨率的占据预测,以减少噪声和增强数据的可用性。
这个流程中,输入为三维栅格,每个体素(voxel)记录了0-1的占据情况。处理过程首先通过permute操作将z轴的维度转换到图像的通道维度,这样三维数据被转换为类似于二维图像的形式。接下来,利用类似于图像处理中的UNet架构来处理这个“二维化”的数据,从而得到二维特征图。最后,使用一个专门的头部(head)网络将这个二维特征图再转换回三维占据栅格。这个过程有效地将3D空间数据处理流程与传统的2D图像处理技术相结合,以实现高效的特征提取和空间理解。
查询网格生成:在占据概率预测步骤之后,所有被预测为占据的栅格都被用作查询网格。这些查询网格将用于后续的3D视觉处理任务,如语义分割或对象识别。
在第二阶段中:
可变形交叉注意力(Deformable Cross Attention):它专注于将查询网格坐标投影到图像上,使用这些投影点作为采集图像特征的参考点,并通过可变形注意力机制来实现。对每一帧图像都进行此操作,并将注意力输出进行平均,以获得全面的特征表示。
可变形自注意力(Deformable Self Attention):采用所有网格点的特征(包括由mask token代表的非查询点)进行注意力处理,以网格中心作为参考点。
其中Attention均采用Deformable Attention。
损失函数
在模型训练过程中,分两个阶段应用了不同的损失函数。
第一阶段 - 这一阶段主要使用交叉熵损失来评估栅格是否正确地被识别为占用。这个阶段的重点是识别哪些体素是重要的,应该被后续处理阶段进一步分析。
第二阶段 - 这一阶段的损失函数更复杂,包括两个部分:
一是用于评估语义类别识别准确性的交叉熵损失;
二是MonoScene提出的Scene-Class Affinity Loss,这个损失函数专注于优化模型对场景中不同类别间关系的理解,从而增强模型对整个场景的认知能力。
五、背景——语义场景补全(SSC,Semantic Scene Completion)
在自动驾驶汽车感知中,从视觉图像进行完整的3D场景理解是一个重要而具有挑战性的任务。
这个过程受限于传感器的视野和物体遮挡问题,导致获取准确和完整的3D信息变得困难。
为了解决这些问题,语义场景补全(SSC)技术被提出,它旨在从有限的观测中联合推断出场景的完整几何形状和语义信息。
SSC的挑战在于需要同时处理可见区域的场景重建和遮挡区域的场景推断。
目前一些基于视觉的SSC方法,例如MonoScene,尝试通过将2D图像特征投影到3D空间来解决这个问题。但这种方法可能会把可见区域的2D特征错误地分配给空的或被遮挡的体素,从而产生歧义,影响后续的几何补全和语义分割任务的性能。

六、模型效果
VoxFormer在SemanticKITTI数据集上进行验证,该数据集提供了KITTI里程计基准测试中每个激光雷达扫描的密集语义注释,共包含22个户外驾驶场景。
- SemanticKITTI SSC基准测试关注车前51.2米、左右两侧各25.6米、高6.4米的体积区域。这个体积的体素化导致了一组尺寸为256×256×32的3D体素网格,因为每个体素的大小为0.2米×0.2米×0.2米。
- 体素网格被标记为20个类别(19个语义类和1个空类)。
- 关于目标输出,SemanticKITTI通过连续注册的语义点云的体素化提供了真实的语义体素网格。
- 对于SSC模型的稀疏输入,可以是单个体素化的激光雷达扫描或RGB图像。
对基于相机的语义场景补全(SSC)方法进行了定量比较:

性能在三种不同体积的空间(分别是12.8×12.8×6.4立方米、25.6×25.6×6.4立方米和51.2×51.2×6.4立方米)内进行评估。前两个体积是为了评估在安全关键的邻近位置的SSC性能。
性能最佳的三种方法分别用红色、绿色和蓝色标记。
VoxFormer和MonoScene在SemanticKITTI hidden test上的定量结果。

VoxFormer在与最新激光雷达基础的语义场景补全(SSC)方法的定量比较中,即使在近距离范围内,其表现也与一些激光雷达基础的方法相当。

在单目深度的情况下,VoxFormer-S在几何(12.8米、25.6米和51.2米范围)和语义(12.8米和25.6米范围)方面的表现优于MonoScene。

VoxFormer在大规模自动驾驶场景中测试效果。相对下,VoxFormer在树干、电线杆等小物体的补全方面表现较好。

分享完成~

![[<span style='color:red;'>CVPR</span> <span style='color:red;'>2023</span>:AeDet实现<span style='color:red;'>方位</span>不变<span style='color:red;'>的</span>多视图<span style='color:red;'>3</span><span style='color:red;'>D</span>目标检测]](https://img-blog.csdnimg.cn/direct/be26c75a6f0c49e982a78d62ca6d3a2b.png)


![[<span style='color:red;'>CVPR</span> <span style='color:red;'>2023</span>:<span style='color:red;'>3</span><span style='color:red;'>D</span> Gaussian Splatting:实时<span style='color:red;'>的</span>神经场渲染]](https://img-blog.csdnimg.cn/direct/f973f10f6301494eac5338df51c43f73.png)