前言
提示:这里可以添加本文要记录的大概内容:
C++ 是一门强大而灵活的编程语言,具有许多高级的特性,其中包括命名空间、缺省参数和函数重载。这些特性为开发者提供了更好的代码组织结构、更灵活的函数调用方式以及更强大的函数多态性。在本博客中,我们将深入探讨这些特性,揭示它们的用途和优势,帮助读者更好地利用 C++ 的强大功能进行编程。
提示:以下是本篇文章正文内容,下面案例可供参考
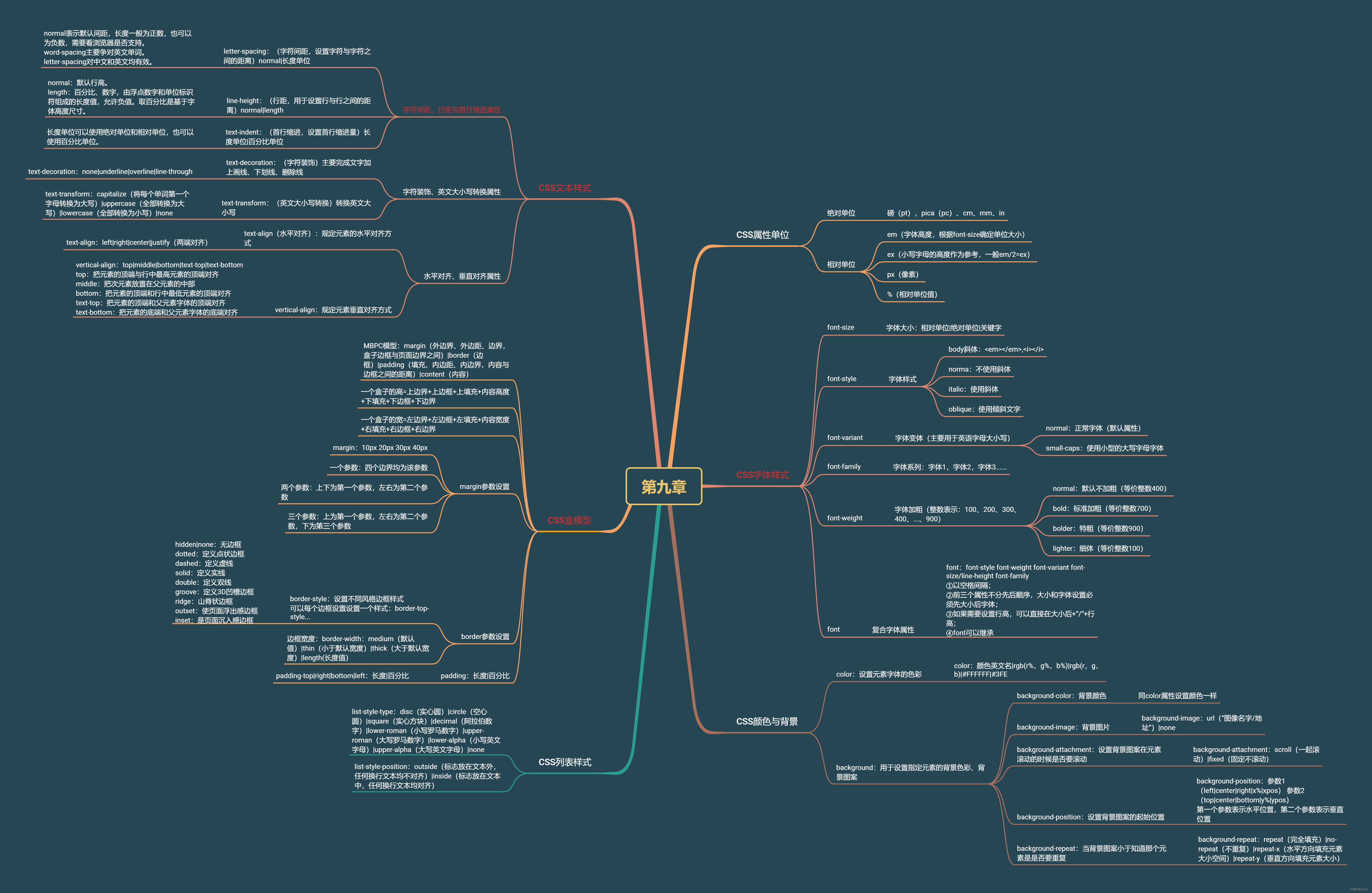
命名空间
在C++中,命名空间是一种用于组织和管理代码的机制,旨在解决命名冲突和提供更好的代码结构。通过命名空间,程序员可以将全局作用域内的代码划分为不同的逻辑单元,使其更具可读性和可维护性。
命名空间的定义
基本形式
namespace NamespaceName {
// 声明或定义代码元素
// 如变量、函数、类等
}
普通的命名空间
namespace N1//N1是命名空间的名称
{
//命名空间中的内容,既可以定义变量,也可以定义函数
int b;
int add(int num1, int num2)
{
return num1 + num2;
}
}
命名空间的嵌套
namespace N2
{
int a;
int b;
int add(int num1, int num2)
{
return num1 + num2;
}
namespace N3
{
int c;
int f;
int sub(int num1, int num2)
{
return num1 - num2;
}
}
}
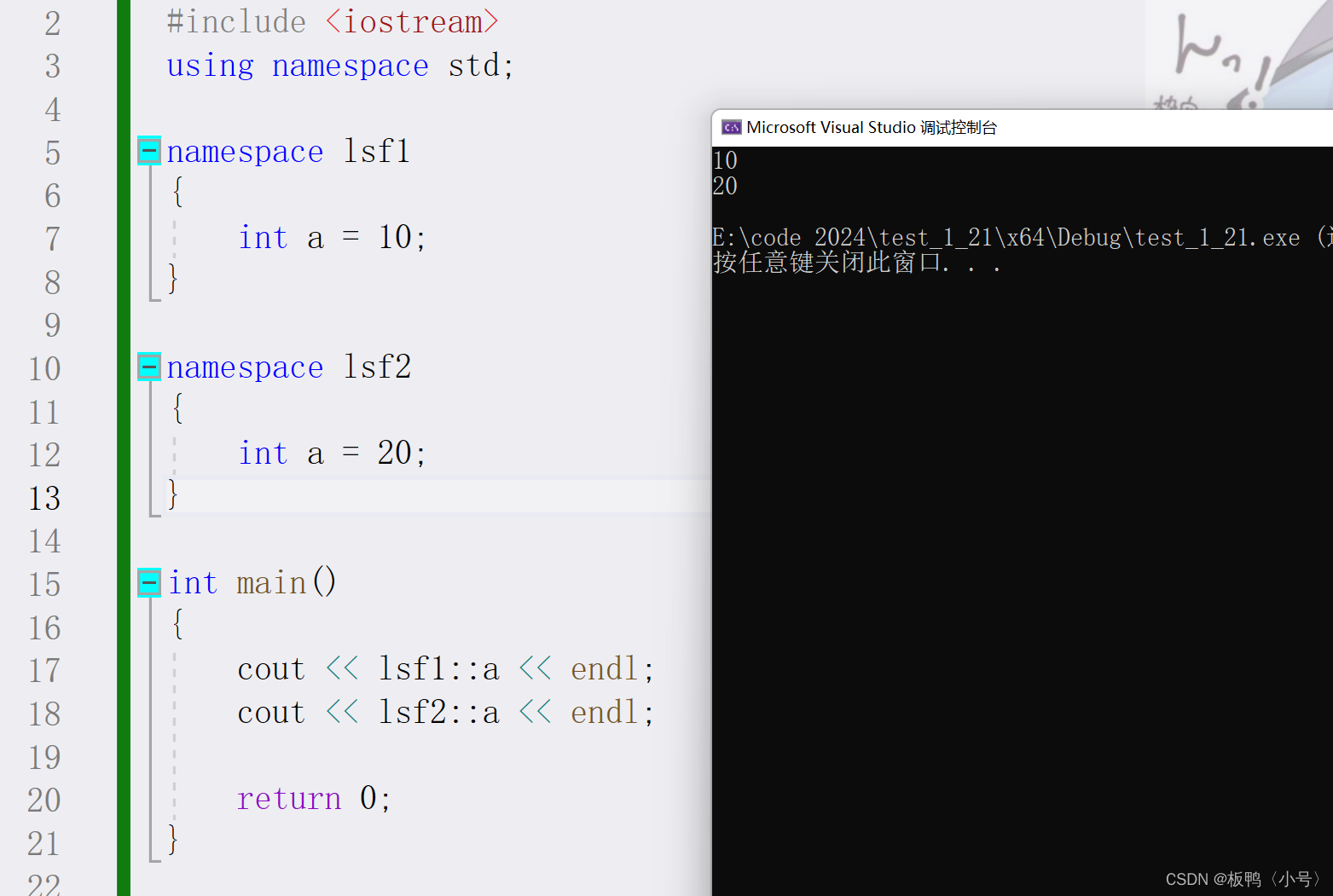
同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中
//同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中
namespace N2
{
int mul(int num1, int num2)
{
return num1 * num2;
}
}
注意:一个命名空间就定义了一个新的作用域,命名空间中所有的内容都局限于该命名空间中
命名空间的使用
先看一段代码
#include <iostream>
using namespace std;
namespace N2
{
int a;
int b;
int add(int num1, int num2)
{
return num1 + num2;
}
namespace N3
{
int c;
int f;
int sub(int num1, int num2)
{
return num1 - num2;
}
}
}
int main()
{
cout <<a << endl;//编译错误,a是未定义的标识符
}
在这段代码中,直接利用变量a并不可行,那么如何引入命名空间N2中的a呢?
命名空间的使用有三种方式:
- 加命名空间名称及作用域标识符
int main()
{
cout<<N2::a<<endl;
cout << N2::N3::f << endl;
return 0;
}
- 使用using关键字将命名空间中成员引入
using N2::a;
using N2::N3::f;
int main()
{
cout<<a<<endl;
cout << f << endl;
return 0;
}
- 使用using namespace关键字将命名空间名称引入
using namespace N2;
int main()
{
cout<<a<<endl;
cout << N3::f << endl;
return 0;
}
C++输入输出
C++ 的输入输出是通过标准库的 <iostream> 头文件提供的。主要使用 cin 进行输入,cout 进行输出。
输入(cin):
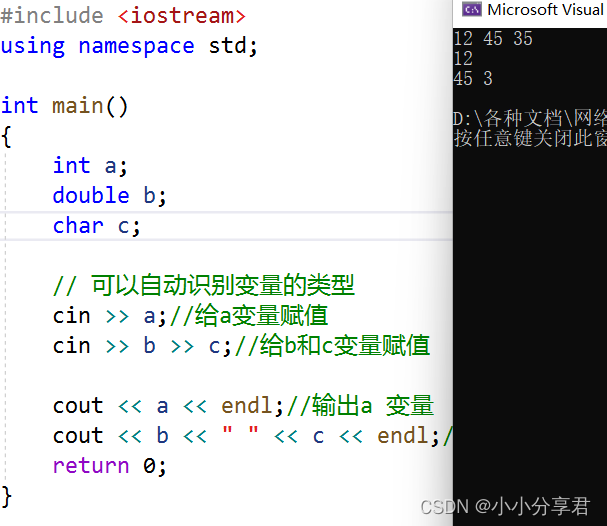
基本输入:
int num; std::cin >> num; // 从标准输入读取整数字符输入:
char ch; std::cin >> ch; // 从标准输入读取字符字符串输入:
std::string str; std::cin >> str; // 从标准输入读取字符串,以空白字符为分隔符
输出(cout):
基本输出:
int num = 42; std::cout << num; // 将整数输出到标准输出字符输出:
char ch = 'A'; std::cout << ch; // 将字符输出到标准输出字符串输出:
std::string str = "Hello, World!"; std::cout << str; // 将字符串输出到标准输出
文件输入输出:
文件输入:
std::ifstream inputFile("input.txt"); int num; inputFile >> num; // 从文件读取整数文件输出:
std::ofstream outputFile("output.txt"); int result = 42; outputFile << result; // 将整数写入文件
注意事项:
- 输入输出流操作需要包含
<iostream>头文件和std标准命名空间。 - 避免使用未初始化的变量进行输出。
- 使用文件输入输出时,确保文件是否存在、可读写。
- 早期的编译器还支持<iosteam.h>的写法,但后续编译器都不支持,因此
推荐使用<iosteam>+std的写法。 - 使用C++输入输出更方便,
不需要增加数据格式控制,比如:整型-%d等。
以上是C++中输入输出的基本概念,这些简单而强大的机制可以满足日常编程中的大多数需求。
缺省参数
缺省参数定义
在C++中,缺省参数(默认参数)是一种函数参数的设置方式,允许在调用函数时不提供该参数的值,而使用函数定义时指定的默认值。这样的设计提高了函数的灵活性和可用性,使得函数的调用更为简便。
示例:
#include <iostream>
using namespace std;
void test(int a = 10)
{
cout << a << endl;
}
int main()
{
test();//没有传参时,使用默认参数
test(20);//传参时使用指定参数
return 0;
}
运行结果

从结果上,证明了缺省参数就是默认参数的事实!!!
缺省参数分类
- 全缺省
#include <iostream>
using namespace std;
void test(int a = 10,int b = 20,int c = 30)
{
cout << a << endl;
cout << b << endl;
cout << c << endl;
}
int main()
{
test();
test(1);
test(1,2);
test(1,2,3);
return 0;
}
- 半缺省
#include <iostream>
using namespace std;
void test(int a ,int b ,int c = 30)
{
cout << a << endl;
cout << b << endl;
cout << c << endl;
}
int main()
{
test(1,2);
test(1,2,3);
return 0;
}
注意事项:!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
- 半缺省参数必须
从右往左依次来给出,不能间隔着给 - 缺省参数不能在函数声明和定义中
同时出现(编译器报错重定义默认参数)
void test1(int x = 10);
void test1(int x = 20)
{
cout << x << endl;
}
- 缺省值必须是常量或者全局变量
- C语言不支持(编译器不支持)
函数重载
函数重载的概念
函数重载是指在同一个作用域内定义多个同名函数,但它们的参数列表或参数类型不同(参数个数或类型或顺序必须其中有一个不同)。C++允许在程序中使用相同的函数名,通过函数参数的不同组合来区分它们。
示例:
#include <iostream>
using namespace std;
int add(int num1, int num2)
{
return num1 + num2;
}
double add(double num1, double num2)
{
return num1 + num2;
}
int main()
{
cout << add(10, 20) << endl;
cout << add(10.1, 20.1) << endl;
return 0;
}
注意:函数重载和返回值类型没有关系!!!
函数名修饰规则
为什么C++支持函数重载,但是C语言不支持?
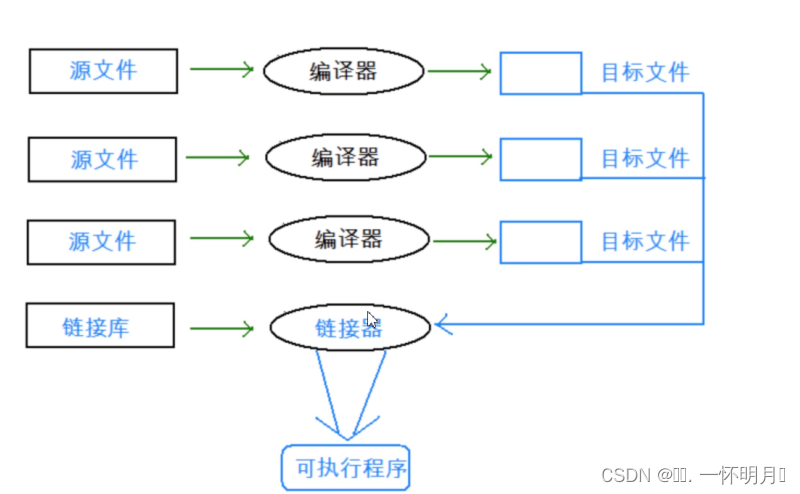
谈到这个问题,我们需要知道程序的运行,需要经过几个步骤:
预处理:宏替换、去注释、头文件的展开
编译:语法分析等、检查语法错误
汇编:将源代码转换成二进制代码,生成目标文件和符号表
链接:链接目标文件,符号表的合并与重定位,生成可执行程序
实际我们的项目通常是由
多个头文件和多个源文件构成,而通过我们C语言阶段学习的编译链接,我们可以知道,当a.cpp中调用了b.cpp中定义的Add函数时,编译后链接前,a.o的目标文件中没有Add的函数地址,因为Add是在b.cpp中定义的,所以Add的地址在b.o中。那么怎么办呢?所以链接阶段就是专门处理这种问题,链接器看到a.o调用Add,但是没有Add的地址,就会到b.o的符号表中找Add的地址,然后链接到一起。那么链接时,面对Add函数,链接器会使用哪个名字去找呢?
这里每个编译器都有自己的函数名修饰规则。由于Windows下vs的修饰规则过于复杂,而Linux下gcc的修饰规则简单易懂,下面我们使用了gcc演示了这个修饰后的名字。
通过下面我们可以看出gcc的函数修饰后名字不变。而g++的函数修饰后变成
_Z+函数长度+函数名+类型首字母。
关键来咯!!!!
- 采用C语言编译器,编译后结果
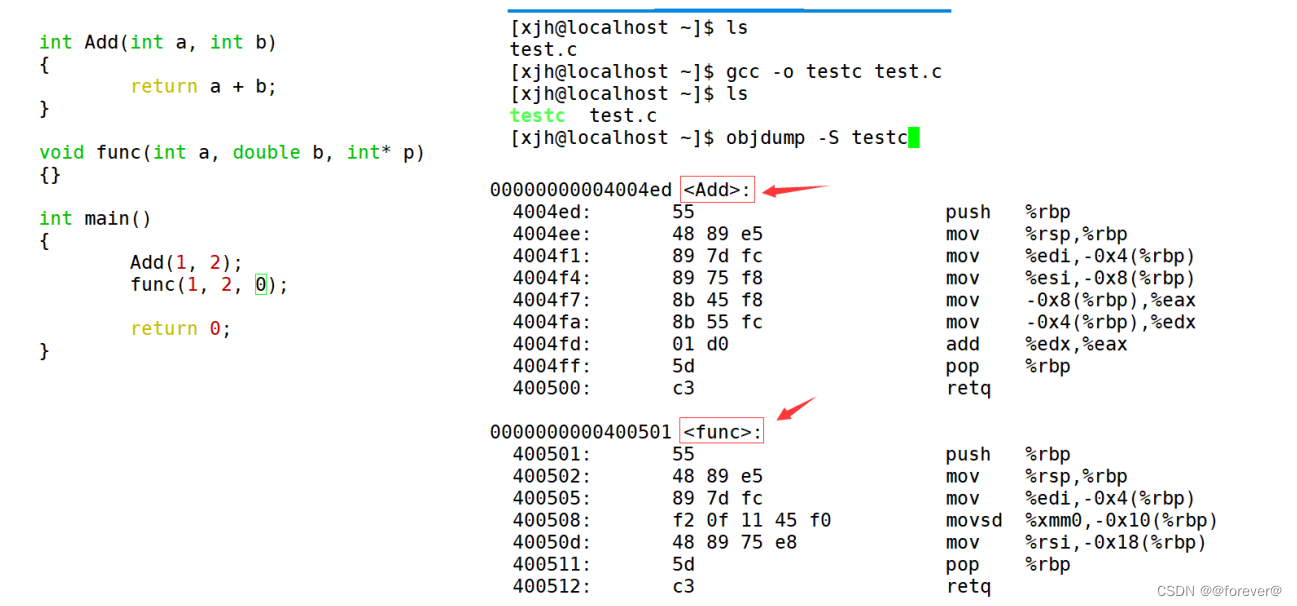
结论:linux、gcc下,可以看到在汇编代码中,函数名和源代码中函数名是一样的,这也说明C语言函数名修饰规则基本就是采用原来的函数名 - 采用C++编译器,编译后结果
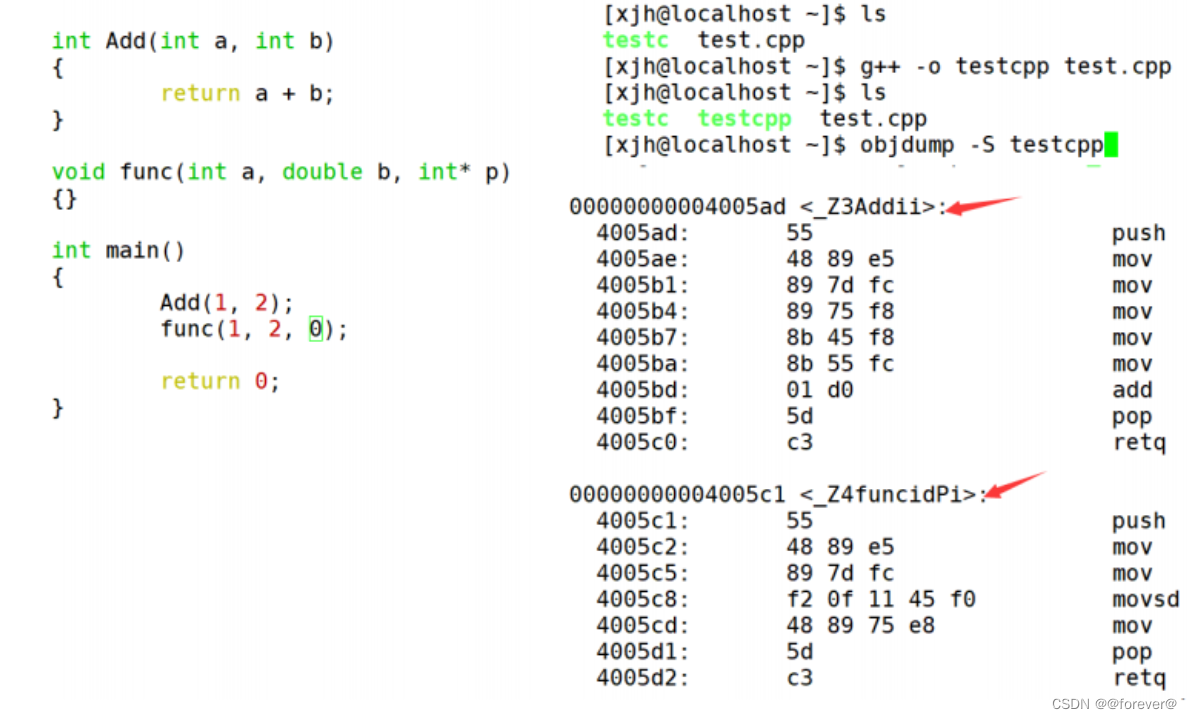
结论:在linux下,采用g++编译完成后,函数名字的修饰发生改变,编译器将函数参数类型信息
添加到修改后的名字中。
extern "C"的使用
有时候在C++工程中可能需要将某些函数按照C的风格来编译,在函数前加extern “C”,意思是告诉编译器,
将该函数按照C语言规则来编译。比如:tcmalloc是google用C++实现的一个项目,他提供tcmallc()和tcfree
两个接口来使用,但如果是C项目就没办法使用,那么他就使用extern “C”来解决。
extern "C" int Add(int left, int right);
int main()
{
Add(1,2);
return 0;
}
总结
通过本博客的阅读,我们希望读者能够更深入地理解 C++ 中命名空间的作用,掌握如何使用缺省参数使函数调用更简洁、灵活,以及如何通过函数重载实现更多样化的函数功能。这些特性不仅提高了代码的可读性和可维护性,也为开发者提供了更多的选择,使得 C++ 成为处理各种编程任务的理想选择。愿这些知识点的掌握能够让你在 C++ 编程的旅途中更加得心应手。