1 Introduction
对于样本的分析,通过全连接层处理表格数据,通过卷积神经网络处理图像数据;第一种假设,所有数据都是独立同分布的RNN 处理序列信号
序列数据的更多场景
1)用户使用习惯具有时间的先后性
2)外推法和内插法
1.1 自回归模型
1)自回归模型,对自己执行回归

2)隐变量的自回归模型
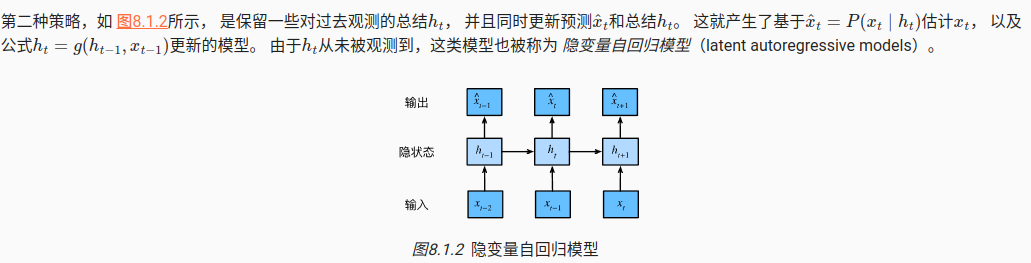
生成训练数据,

1.2 马尔科夫模型
一个模型被称为马尔可夫模型,主要是因为它满足马尔可夫性质,也就是说,该模型中的未来状态仅依赖于当前状态,而不依赖于过去的历史状态。在数学上,这被表达为条件概率的形式: ( p ( x k ∣ x k − 1 , x k − 2 , … ) = p ( x k ∣ x k − 1 ) ( p(x_k|x_{k-1}, x_{k-2}, \ldots) = p(x_k|x_{k-1}) (p(xk∣xk−1,xk−2,…)=p(xk∣xk−1)。这意味着下一个状态( x_k )的概率分布只取决于紧邻的前一个状态( x_{k-1} ),而与之前的所有其他状态无关。

2 文本序列处理
将文本拆分成次元,将词源字符串映射成数字索引,并将文本数据转换成词元索引以供模型操作。
将文本作为字符串加载到内存中。
将字符串拆分为词元(如单词和字符)。
建立一个词表,将拆分的词元映射到数字索引。
将文本转换为数字索引序列,方便模型操作。
3 语言模型和数据集
语言模型的目标是估计序列的联合概率
P ( x 1 , x 2 , . . . , x T ) P(x_1, x_2, ..., x_T) P(x1,x2,...,xT)

用贝叶斯条件概率估计,这种贝叶斯估计,会因为样本的稀疏,并不好建立足够的联系。

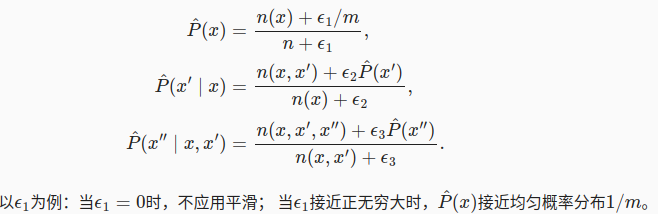
可以用马尔科夫模型来近似,因为当前状态基本上只依赖于前几个词元。
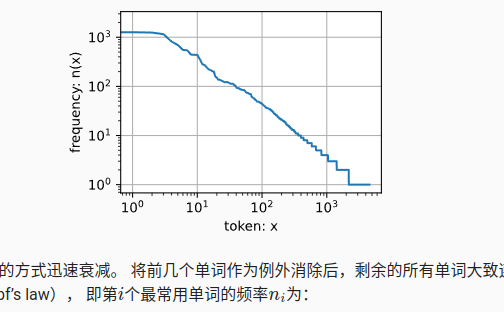
单词出现的频率以非常快的速度进行衰减,齐普夫定律(Zipf’s law), 即第个最常用单词的频率为:
多元语法的频率
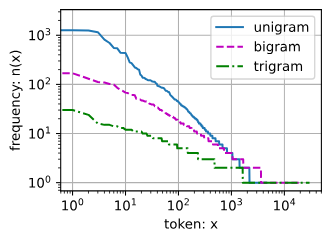
- 除了一元语法词,单词序列似乎也遵循齐普夫定律, 尽管公式 (8.3.7)中的指数
更小 (指数的大小受序列长度的影响);- 词表中元组的数量并没有那么大,这说明语言中存在相当多的结构, 这些结构给了我们应用模型的希望;
- 很多元组很少出现,这使得拉普拉斯平滑非常不适合语言建模。 作为代替,我们将使用基于深度学习的模型
读取长序列数据,如果采用固定长度,效果不太好,采用随机偏移量划分序列,以获得覆盖性和随机性。

2.1 随机采样
def seq_data_iter_random(corpus, batch_size, num_steps): #@save
"""使用随机抽样生成一个小批量子序列"""
# 从随机偏移量开始对序列进行分区,随机范围包括num_steps-1
corpus = corpus[random.randint(0, num_steps - 1):]
# 减去1,是因为我们需要考虑标签
num_subseqs = (len(corpus) - 1) // num_steps
# 长度为num_steps的子序列的起始索引
initial_indices = list(range(0, num_subseqs * num_steps, num_steps))
# 在随机抽样的迭代过程中,
# 来自两个相邻的、随机的、小批量中的子序列不一定在原始序列上相邻
random.shuffle(initial_indices)
def data(pos):
# 返回从pos位置开始的长度为num_steps的序列
return corpus[pos: pos + num_steps]
num_batches = num_subseqs // batch_size
for i in range(0, batch_size * num_batches, batch_size):
# 在这里,initial_indices包含子序列的随机起始索引
initial_indices_per_batch = initial_indices[i: i + batch_size]
X = [data(j) for j in initial_indices_per_batch]
Y = [data(j + 1) for j in initial_indices_per_batch]
yield torch.tensor(X), torch.tensor(Y)
2.2 顺序分区
完全按照顺序进行分区,没有洗牌的操作。
def seq_data_iter_sequential(corpus, batch_size, num_steps): #@save
"""使用顺序分区生成一个小批量子序列"""
# 从随机偏移量开始划分序列
offset = random.randint(0, num_steps)
num_tokens = ((len(corpus) - offset - 1) // batch_size) * batch_size
Xs = torch.tensor(corpus[offset: offset + num_tokens])
Ys = torch.tensor(corpus[offset + 1: offset + 1 + num_tokens])
Xs, Ys = Xs.reshape(batch_size, -1), Ys.reshape(batch_size, -1)
num_batches = Xs.shape[1] // num_steps
for i in range(0, num_steps * num_batches, num_steps):
X = Xs[:, i: i + num_steps]
Y = Ys[:, i: i + num_steps]
yield X, Y
4 循环神经网络
循环圣经网络的核心思想

4.1 无隐状态的神经网络
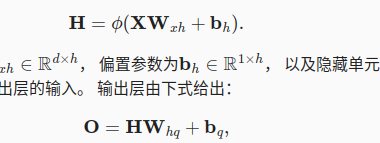
4.2 有隐状态的神经网络
H t − 1 H_{t-1} Ht−1捕获并保留序列知道当前时间步的历史信息

对于第一个输入,往往也会初始化一个隐变量
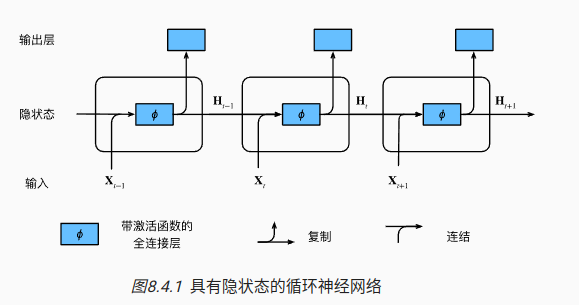
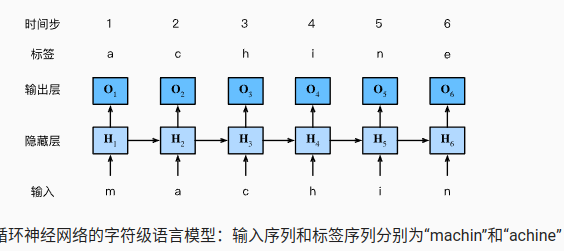
输出层,采用softmax的分类器;因为有很多个head,中间的输出层的结果如下图,会推断到下一个
4.3 困惑度
质量上,从人的评价来说,满足基本的结构,满足填充的内容正确,

似然概率来度量模型的质量,但是因序列的长度有差异,需要借用信息论中信息熵的概念来分析
类似调和平均数来判断,困惑度


5 RNN的从零实现
5.1 独热编码

独热编码(One-Hot Encoding)的好处主要包括:
清晰表示:独热编码通过将每个类别表示为一个唯一的二进制向量,为类别提供了明确的表示,这在处理类别数据时非常有用。
无序性:在独热编码中,不同类别之间没有数值上的关联,这避免了模型错误地解释类别间的数值关系,特别是在类别没有内在顺序的情况下。
适合距离计算:由于每个类别都被转换成相互正交的向量,它们在空间中的距离是相等的。这对于基于距离的算法(如K-近邻算法)非常有用。
在处理不同长度的序列样本时,RNN网络通常采用以下策略之一:
填充(Padding):将所有序列填充到相同的长度。较短的序列在末尾添加特殊的填充符号,以便所有序列具有相同的长度。这允许网络具有固定的结构。
动态计算图:某些深度学习框架支持动态计算图,它们可以处理可变长度的输入。在这种情况下,RNN可以在每个批次中处理不同长度的序列,而无需填充。
分批处理不同长度:将序列分组到不同长度的批次中。这种方法避免了过多的填充,但可能需要更复杂的批次管理。
5.2 梯度裁剪
梯度裁剪和Wolfe原则有一定的相似性,但也存在重要的区别:
梯度裁剪:主要关注梯度的大小。当梯度的范数超过一个预定的阈值时,会按比例缩减梯度,以防止梯度过大导致的训练不稳定问题。
Wolfe原则:是一种在线搜索(Line Search)策略,用于选择步长。它包含两个条件:充分下降条件和曲率条件,旨在确保每一步优化都朝着目标函数下降的方向,并且步长既不太大也不太小。
共同之处在于它们都旨在通过控制优化步骤的大小来提高优化过程的稳定性。不同之处在于梯度裁剪是一种更直接的方法,用于控制梯度的大小,而Wolfe原则是一种更复杂的策略,用于在优化过程中选择合适的步长。


def grad_clipping(net, theta): #@save
"""裁剪梯度"""
if isinstance(net, nn.Module):
params = [p for p in net.parameters() if p.requires_grad]
else:
params = net.params
norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))
if norm > theta:
for param in params:
param.grad[:] *= theta / norm
6 简洁实现
#@save
class RNNModel(nn.Module):
"""循环神经网络模型"""
def __init__(self, rnn_layer, vocab_size, **kwargs):
super(RNNModel, self).__init__(**kwargs)
self.rnn = rnn_layer
self.vocab_size = vocab_size
self.num_hiddens = self.rnn.hidden_size
# 如果RNN是双向的(之后将介绍),num_directions应该是2,否则应该是1
if not self.rnn.bidirectional:
self.num_directions = 1
self.linear = nn.Linear(self.num_hiddens, self.vocab_size)
else:
self.num_directions = 2
self.linear = nn.Linear(self.num_hiddens * 2, self.vocab_size)
def forward(self, inputs, state):
X = F.one_hot(inputs.T.long(), self.vocab_size)
X = X.to(torch.float32)
Y, state = self.rnn(X, state)
# 全连接层首先将Y的形状改为(时间步数*批量大小,隐藏单元数)
# 它的输出形状是(时间步数*批量大小,词表大小)。
output = self.linear(Y.reshape((-1, Y.shape[-1])))
return output, state
def begin_state(self, device, batch_size=1):
if not isinstance(self.rnn, nn.LSTM):
# nn.GRU以张量作为隐状态
return torch.zeros((self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens),
device=device)
else:
# nn.LSTM以元组作为隐状态
return (torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device),
torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device))
7 通过时间反向传播
7.1 梯度分析
通过链式法则回顾循环神经网络的梯度爆炸问题;类似控制中的乘积累加的问题,第一个词元对最后位置的词元产生重大的影响。
每个时间步的隐状态和输出,完整的RNN表示如下:
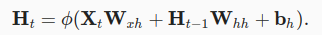
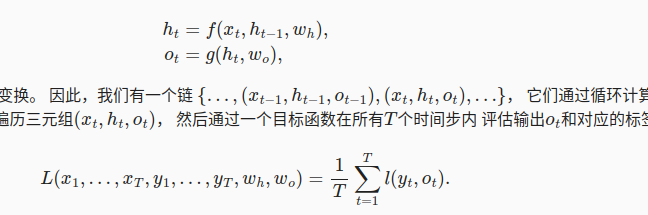
统计T个时间步内的总体的loss,
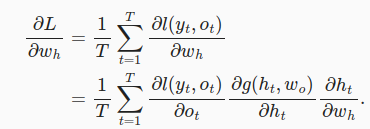
计算目标函数L关于参数 w h w_h wh的梯度时,
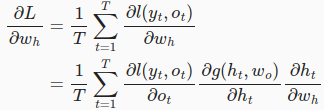
这里的因为链式法则比较复杂,
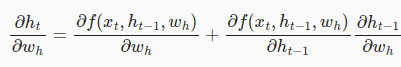
有以下几种策略:
完全计算
因为有循环结算,容易梯度爆炸
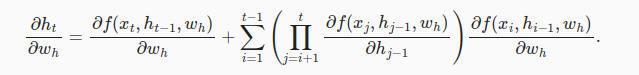
截断时间步
截断到 ∂ h t − τ ∂ w h \frac{\partial h_{t-\tau}}{\partial w_h} ∂wh∂ht−τ随机截断
比较策略
实践中,随机截断的效果不比常规截断更好,
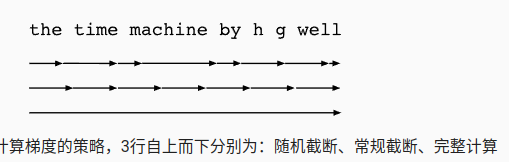
7.2 通过时间反向传播的细节
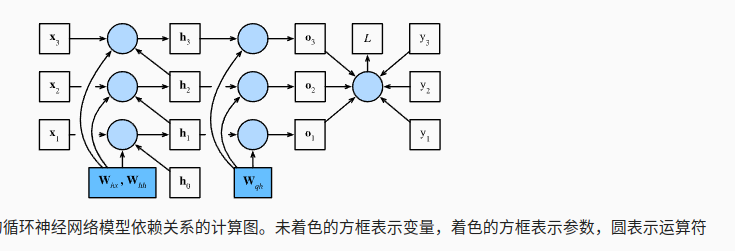
一套链式法则以后,类似于控制中的状态变量,初始的隐变量对应的参数的梯度是指数型的,导致数值上的不稳定;
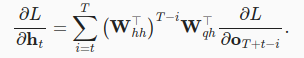
解决方法:
1)截断时间不长,取近似的梯度;
2)LSTM