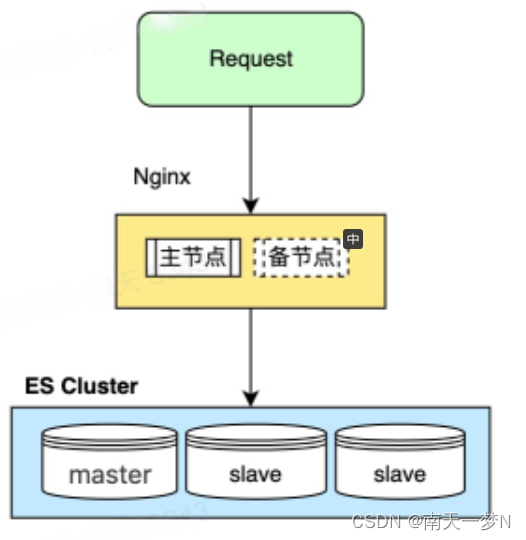
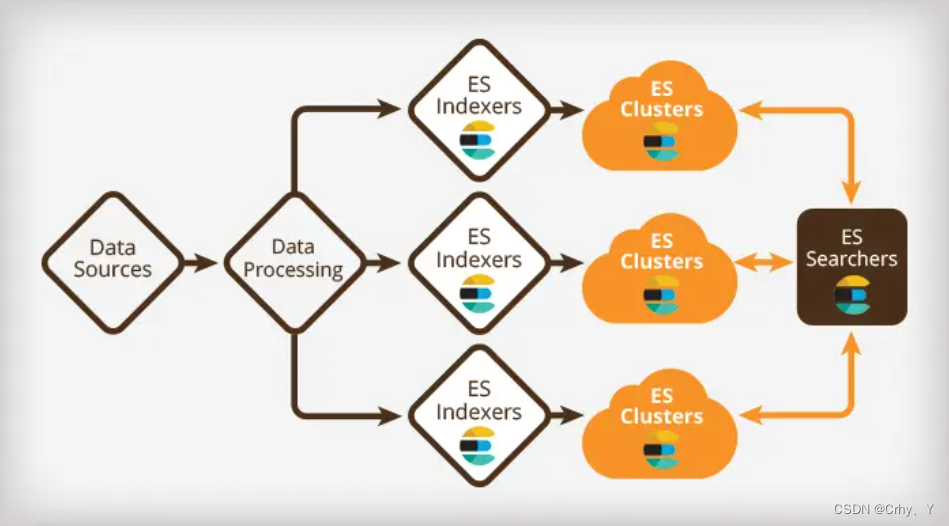
单机的elasticsearch做数据存储,必然面临两个问题:海量数据存储问题、单点故障问题。为了解决存储能力上上限问题就可以用到集群部署。
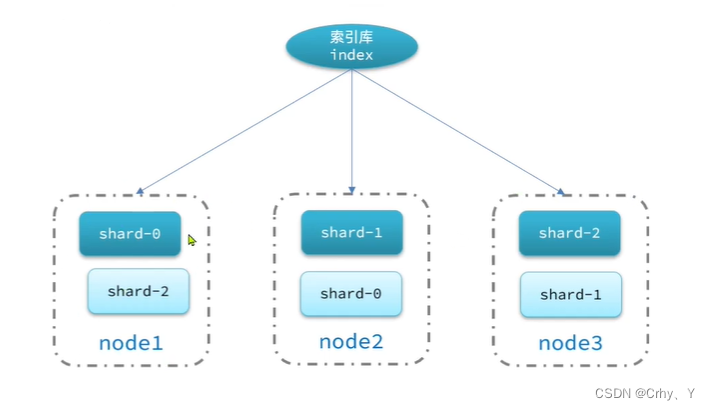
- 海量数据存储问题:将索引库从逻辑上拆分为N个分片(shard),存储到多个节点
- 单点故障问题:将分片数据在不同节点备份 (replica )
目录
二、集群搭建案例:利用3个docker容器模拟3个es的节点
2.1 首先编写一个docker-compost文件,代码如下
一、部署es集群
在单机上利用docker容器运行多个es实例来模拟es集群。在生产环境中推荐每一台服务节点仅部署一个es的实例。
部署es集群可以直接使用docker-compose来完成,但要求Linux虚拟机至少有4GI的内存空间。
二、集群搭建案例:利用3个docker容器模拟3个es的节点
2.1 首先编写一个docker-compost文件,代码如下
version:"2.2
services:
es01:
image: elasticsearch:7.12.1
container_name: es01
environment:
- node .name=ego1
-cluster.name=es-docker-cluster
-discovery.seed_hosts=es02,es3
-cluster.initial_master_nodes=es1es02 ,es03
-"ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
-data01:/usr/share/elasticsearch/data
ports:
-9200:9200
networks:
-elastic
es02:
image: elasticsearch:7.12.1
container_name: es02
environment:
-node.name=es02
-cluster.name=es-docker-cluster
-discovery.seed_hosts=es01,es03
-cluster.initial_master_nodes=es01,es02,es03
-"ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
-data02:/usr/share/elasticsearch/data
ports:
9201:9200
networks:
-elastic
es03:
image: elasticsearch:7.12.1
container_name: es03
environment:
-node.name=es03
-cluster.name=es-docker-cluster
-discovery.seed_hosts=es01,es02
-cluster.initial_master_nodes=es01,es02,es03
-"ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
-data03:/usr/share/elasticsearch/data
ports:
9202:9200
networks:
-elastic
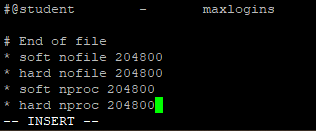
2.2 es运行需要修改一些lintx系统权限
(1) 修改 /etc/sysctl.conf 文件
vi /etc/sysctl.conf
(2) 添加下面的内容
vm.max_map_count=262144
(3) 然后执行命令,让配置生效
sysctl -p
(4) 通过docker-compose启动集群
docker-compose up -d
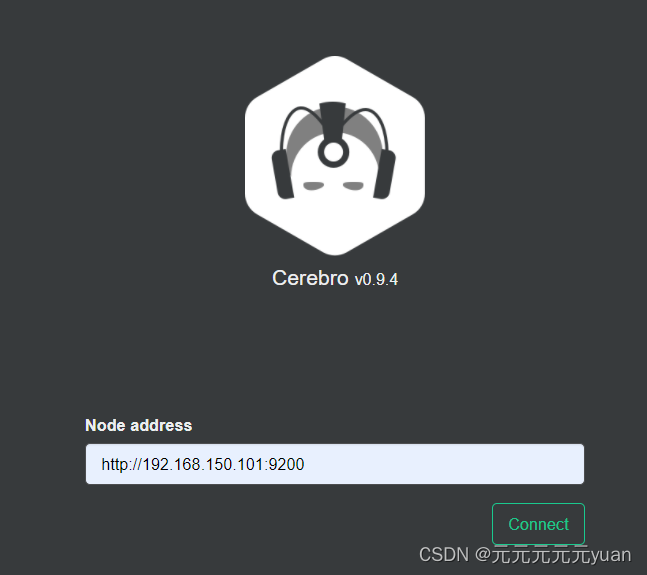
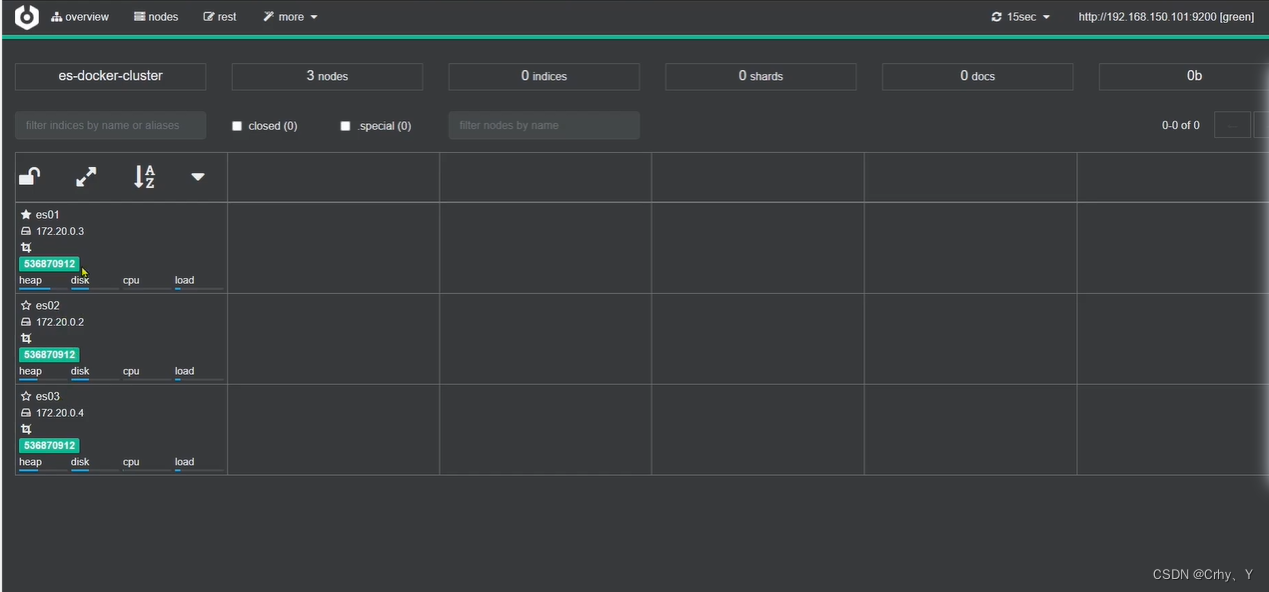
2.3 集群状态监控(cerebro)
kibana可以监控es集群,不过新版本需要依赖es的x-pack 功能,配置比较复杂。
推荐使用cerebro来监控es集群状态,官方网址:https://github.com/lmenezes/cerebro
启动 cerebro 服务

访问登录cerebro
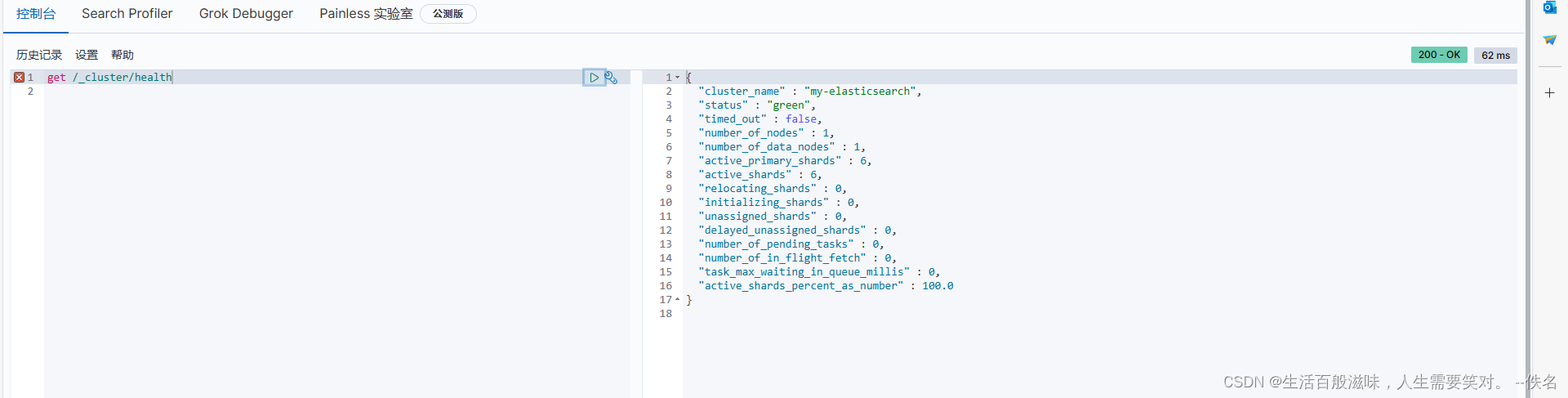
集群状态
2.4 创建索引库
第一种方式:利用kibana的DevTools创建索引库 ,在DevTools中输入指令
PuT /itcast
{
"settings" : {
"number_of_shards": 3,// 分片款量"number_of_replicas": 1 // 副本数
},
"mappings" : {
"properties":{
//mapping晚射定义
}
}
}
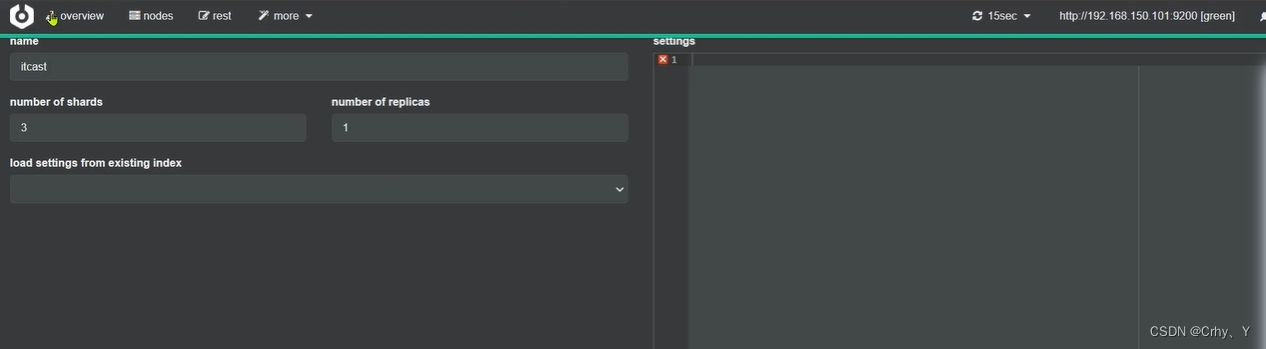
第二种方式:利用cerebro创建索引库
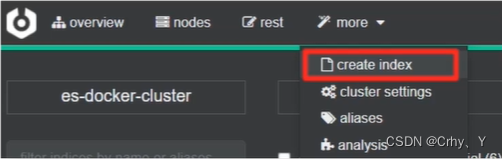
填写索引库信息