1.数据重塑
重塑数据主要有两种方式,分别是 stack(堆叠)和 unstack(拆堆),他们两个是互逆的操作
| 函数 | 作用 | 参数 |
|---|---|---|
data.stack( ) 堆叠 |
会“旋转”或将列中的数据透视到行 列 一一> 行 |
可以在括号里传入需要堆叠的轴向名称 |
data.unstack( ) 拆堆 |
将行中的数据透视到列 行 一一> 列 |
可以通过传入一个层级名称来拆分不同的层级 |
import pandas as pd
import numpy as np
data = pd.DataFrame(np.arange(12).reshape(6,2),
index = pd.MultiIndex.from_product([["Ohio","Colorado"],["one","two","three"]],names = ["state","number"]),
columns = pd.Index(["left","right"],name = "side"))
print(data)
print("-"*35)
# 拆堆 行透视为列
chai = data.unstack("state") # 传入要拆分的层级
print(chai)
print("-"*35)
# 堆叠 列透视为行
dui = chai.stack("side")
print(dui)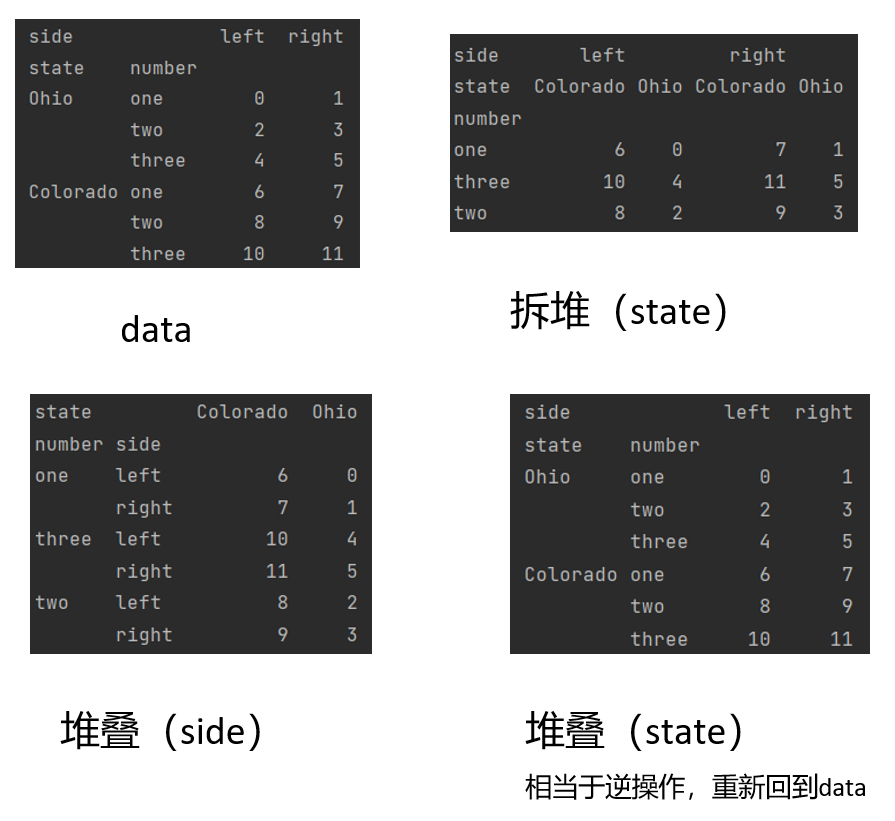
2.数据透视表
透视表是一种可以对数据动态排布并且分类汇总的表格格式
可以让我们从不同的角度去分析一个大数据库,有点类似于分类筛选的高阶版操作
2.1 pivot_table
该部分笔记参考了以下文章:
https://zhuanlan.zhihu.com/p/31952948![]() https://zhuanlan.zhihu.com/p/31952948
https://zhuanlan.zhihu.com/p/31952948
- 语法:
pivot_table ( data, index = None, values = None, columns = None, aggfunc = 'mean' )
常用参数说明:
index: 设置行分层字段,将选中的列设为行索引 👇
values:输入一个含列名的列表,筛选我们需要保留的列
columns:类似Index设置列分层字段,将选中的列设为列索引 👉
aggfunc:设置我们对数据聚合时进行的函数操作,默认为 mean
fill_value:替换缺失值
drop_na:是否去除所有条目均为NA的列(默认False,不去除)
margins:是否添加行 / 列计数 及 总计数(默认False,不添加)
- 参数使用说明
下面我们以詹姆斯某赛季的数据为例,来对pivot_table函数进行讲解
step1 首先导入数据,并展示前五场:
import pandas as pd
import numpy as np
road = "E:\python 资料\孙兴华 数据分析教程\Pandas课件\课件\pandas教程\课件028-029\Lebron_James.csv"
data = pd.read_table(road,sep=",")
print(data.head(5))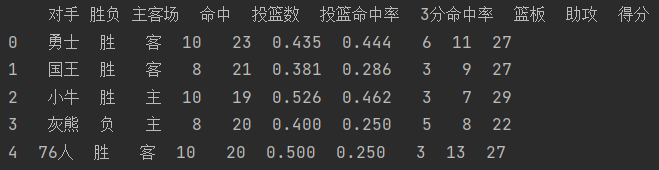
step2 需要james在主客场和不同胜负情况(index)下的得分、篮板与助攻(values)三项数据
data1 = pd.pivot_table(data, index=['对手', '主客场'],values=['得分','助攻','篮板'])
print(data1.head(5))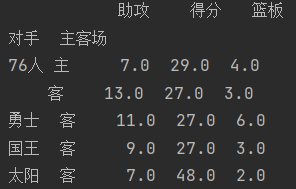
step3 我们还想获得james在主客场和不同胜负情况下的总得分、总篮板、总助攻(aggfunc)
此时应该向aggfunc中输入sum函数,按层次求和
# 这里要注意mean不是内置函数,它是numpy中的一个函数
data2 = pd.pivot_table(data, index=['对手', '主客场'],values=['得分','助攻','篮板'],
aggfunc=[sum,np.mean])
print(data2.head(5))
step4 我们也可以通过columns再设置一个列索引,并且通过margin来汇总
# fill_value填充空值,margins=True进行汇总
data3 =pd.pivot_table(data,index=['主客场'],columns=['对手'],values=['得分'],aggfunc=[np.sum],fill_value=0,margins=1)
print(data3)
2.2 实现excel的vlookup功能
- 要求:一个excel表中有两个sheet,要求将 sheet1 中的某列,插入到 sheet2 的指定位置
- step:
- 切片要合并的列
- 将它和sheet2合并
- 再在合并的数据中提取出该列,并在合并数据中删除该列
- 将提取出的该列插入指定位置
import pandas as pd
road = "E:\python 资料\孙兴华 数据分析教程\Pandas课件\课件\pandas教程\课件028-029\Vlookup.xlsx"
data1 = pd.read_excel(road,sheet_name="花名册")
data2 = pd.read_excel(road,sheet_name="成绩单")
# 将 花名册 与 成绩单中的总分、学号 合并
hebing = pd.merge(data1,data2.loc[:,["学号","总分"]],how = "left",on = "学号")
print(hebing)
print("-" * 40)
# 将总分放到第二列的位置
score = hebing.总分 # 提取出 总分 列
hebing = hebing.drop("总分",axis = 1) # 在原数据中删除该列
hebing.insert(1,"总分",score) # 在原数据第二列插入新列
print(hebing)
3.数据处理三板斧
在数据处理中,经常会对一个DataFrame进行逐行、逐列和逐元素的操作,对应这些操作,Pandas中的 map \ apply \ applymap 可以解决绝大部分这样的数据处理需求
3.1 map
map会根据提供的函数或字典对指定序列做映射,它更多地适用于简单的批量处理数据,function中的参数最好只有一个
- 语法:map(字典) 或 data.map(function)或 map(function,data)
- 案例一:对每个单元格(元素)执行指定的函数操作
一般使用匿名函数 lambda 去定义函数,进行操作
import pandas as pd
road = "E:\python 资料\孙兴华 数据分析教程\Pandas课件\课件\pandas教程\课件030-031\数据2.xlsx"
data = pd.read_excel(road)
print(data)
print("-"*40)
data2 = data.map(lambda x:"%.2f" % x) #每个元素保留两位小数
print(data2)
print("-"*40)
data3 = data.map(lambda x: x ** 2) #每个元素的平方
print(data3)
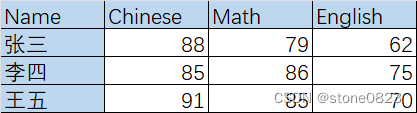
- 案例二:逐行 / 列处理数据
在原数据中新增两列, 若为男就是先生,若为女就是女士;再根据体重判断体型,若大于80kg就是魁梧,小于80kg就是瘦小
import pandas as pd
road = "E:\python 资料\孙兴华 数据分析教程\Pandas课件\课件\pandas教程\课件030-031\数据.xlsx"
data = pd.read_excel(road)
print(data)
print("-"*40)
# 一:用字典做映射
zidian = {'男':'先生','女':'女士'}
data["称呼"] = data["性别"].map(zidian) #新增一个 称呼 列,若为男就是先生,若为女就是女士
print(data)
print("-"*40)
# 二:用函数做映射
def judge(x):
result = "魁梧" if x > 80 else "瘦小"
return result
data["体型"] = data["体重"].map(judge) #根据体重判断体型
print(data)
3.2 apply
apply() 函数的自由度较高,可以直接对 DataFrame 中元素进行逐元素的遍历操作,方便且高效;与map相比,它可以在一个函数中传入多个参数来使用,适用范围较广(可传入更复杂的函数)
- 语法 :data.apply( function,axis = 0,row = False,arg = (元组))
参数说明:
axis = :沿哪个轴进行数据处理(默认为0,处理每一列)
row = :0表示把每一行或列作为 Series 传入函数中;1表示接收ndarry数组
arg = :若函数有多个参数,则传入一个元组,接收第二至最后一个参数
其余说明事项:
- 在处理多个参数时,需要用arg参数接收第二至最后一个参数
- 在处理多行时,直接在data位置传入 dataframe 或者 df切片后的多列即可
- 当axis=1对行进行操作时,会默认将每一行数据以Series的形式(Series的索引为列名)传入指定函数,返回相应的结果;axis = 0同理
- 案例一:单行或单列进行操作(map也可以完成)
要求:仍然使用map中案例二的数据,修改分数:所有人的语文成绩 +5 分
def score_change(x,y): # x为科目,y为修改值
return x + y
#arg传入一个元组,接受第二个参数
data["语文"] = data["语文"].apply(score_change,args=(5,)) - 案例二:对多行 / 多列进行操作
要求:计算每个人(逐行)三科的总成绩,并根据总成绩排序
data["总成绩"] = data[['语文','数学','英语']].apply(sum,axis=1) # 逐行相加
data = data.sort_values (by="总成绩",ascending=False) # 根据总成绩降序排序
print(data)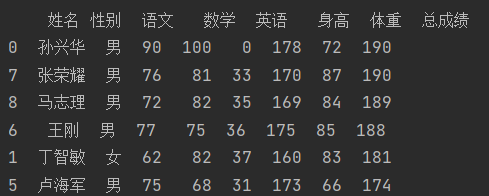
- 案例三: 综合运用
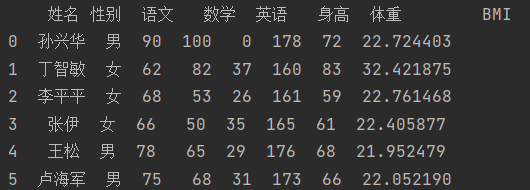
要求:计算每个人的bmi
def BMI(data):
height = data["身高"]
weight = data["体重"]
BMI =weight / height ** 2
return BMI
data["BMI"] = data.apply(BMI,axis=1)
print(data)