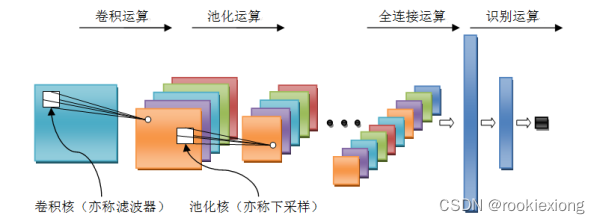
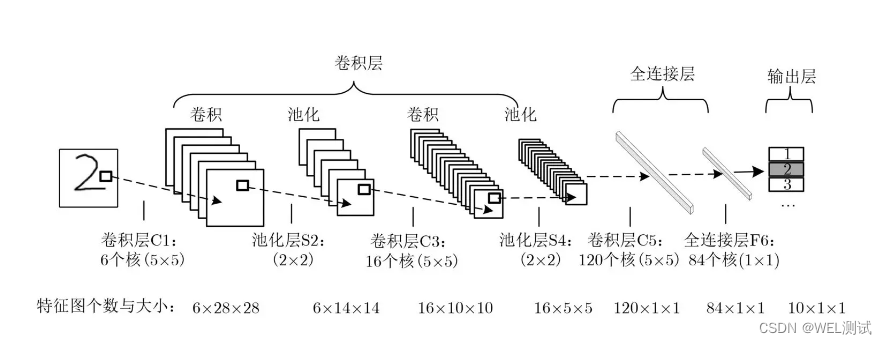
四、理论分析
4.1 反卷积运算


我们可以将过滤器转换为 Toeplitz matrix ,将图像转换为向量,然后仅通过一个矩阵乘法进行卷积,而不是使用 for-loops 对图像(或任何其他 2D 矩阵)执行 2D 卷积。 (当然还要对乘法结果进行一些后处理以获得最终结果)。
有许多高效的矩阵乘法算法,因此使用它们我们可以有效地实现卷积运算
这个过程的数学和算法解释:


以下给出这个算法的简单 Python 实现,以使其更加清晰。
import numpy as np # 导入numpy库,用于处理数组和矩阵
from scipy.linalg import toeplitz # 导入scipy库中的toeplitz函数,用于生成托普利茨矩阵
def matrix_to_vector(input): # 定义一个函数,将一个矩阵转换为一个向量
input_h, input_w = input.shape # 获取输入矩阵的行数和列数
output_vector = np.zeros(input_h*input_w, dtype=input.dtype) # 创建一个全零的向量,长度为输入矩阵的元素个数,数据类型与输入矩阵相同
# flip the input matrix up-down because last row should go first
input = np.flipud(input) # 将输入矩阵上下翻转,因为最后一行应该放在向量的最前面
for i,row in enumerate(input): # 遍历输入矩阵的每一行,i是行的索引,row是行的内容
st = i*input_w # 计算向量中对应的起始位置
nd = st + input_w # 计算向量中对应的结束位置
output_vector[st:nd] = row # 将矩阵的一行复制到向量的相应位置
return output_vector # 返回转换后的向量
def vector_to_matrix(input, output_shape): # 定义一个函数,将一个向量转换为一个矩阵
output_h, output_w = output_shape # 获取输出矩阵的行数和列数
output = np.zeros(output_shape, dtype=input.dtype) # 创建一个全零的矩阵,形状为输出矩阵的形状,数据类型与输入向量相同
for i in range(output_h): # 遍历输出矩阵的每一行
st = i*output_w # 计算向量中对应的起始位置
nd = st + output_w # 计算向量中对应的结束位置
output[i, :] = input[st:nd] # 将向量的一部分复制到矩阵的一行
# flip the output matrix up-down to get correct result
output=np.flipud(output) # 将输出矩阵上下翻转,以得到正确的结果
return output # 返回转换后的矩阵
def convolution_as_maultiplication(I, F, print_ir=False): # 定义一个函数,将卷积运算转换为矩阵乘法
# number of columns and rows of the input
I_row_num, I_col_num = I.shape # 获取输入矩阵的行数和列数
# number of columns and rows of the filter
F_row_num, F_col_num = F.shape # 获取滤波器矩阵的行数和列数
# calculate the output dimensions
output_row_num = I_row_num + F_row_num - 1 # 计算输出矩阵的行数,为输入矩阵和滤波器矩阵的行数之和减一
output_col_num = I_col_num + F_col_num - 1 # 计算输出矩阵的列数,为输入矩阵和滤波器矩阵的列数之和减一
if print_ir: print('output dimension:', output_row_num, output_col_num) # 如果print_ir为真,打印输出矩阵的维度
# zero pad the filter
F_zero_padded = np.pad(F, ((output_row_num - F_row_num, 0),
(0, output_col_num - F_col_num)),
'constant', constant_values=0) # 将滤波器矩阵用零填充,使其形状与输出矩阵相同
if print_ir: print('F_zero_padded: ', F_zero_padded) # 如果print_ir为真,打印零填充后的滤波器矩阵
# use each row of the zero-padded F to creat a toeplitz matrix.
# Number of columns in this matrices are same as numbe of columns of input signal
toeplitz_list = [] # 创建一个空列表,用于存储托普利茨矩阵
for i in range(F_zero_padded.shape[0]-1, -1, -1): # 从零填充后的滤波器矩阵的最后一行遍历到第一行,i是行的索引
c = F_zero_padded[i, :] # 取出第i行的内容,作为托普利茨矩阵的第一列
r = np.r_[c[0], np.zeros(I_col_num-1)] # 以第一列的第一个元素和输入矩阵列数减一个零组成一个数组,作为托普利茨矩阵的第一行
toeplitz_m = toeplitz(c,r) # 用scipy库中的toeplitz函数生成一个托普利茨矩阵
toeplitz_list.append(toeplitz_m) # 将生成的托普利茨矩阵添加到列表中
if print_ir: print('F '+ str(i)+'\n', toeplitz_m) # 如果print_ir为真,打印生成的托普利茨矩阵
# doubly blocked toeplitz indices:
# this matrix defines which toeplitz matrix from toeplitz_list goes to which part of the doubly blocked
c = range(1, F_zero_padded.shape[0]+1) # 生成一个从1到零填充后的滤波器矩阵的行数的序列,作为双重阻塞托普利茨矩阵的索引矩阵的第一列
r = np.r_[c[0], np.zeros(I_row_num-1, dtype=int)] # 以第一列的第一个元素和输入矩阵行数减一个零组成一个数组,作为双重阻塞托普利茨矩阵的索引矩阵的第一行
doubly_indices = toeplitz(c, r) # 用scipy库中的toeplitz函数生成一个双重阻塞托普利茨矩阵的索引矩阵
if print_ir: print('doubly indices \n', doubly_indices) # 如果print_ir为真,打印双重阻塞托普利茨矩阵的索引矩阵
## creat doubly blocked matrix with zero values
toeplitz_shape = toeplitz_list[0].shape # 获取列表中的一个托普利茨矩阵的形状
h = toeplitz_shape[0]*doubly_indices.shape[0] # 计算双重阻塞托普利茨矩阵的高度,为一个托普利茨矩阵的高度乘以索引矩阵的高度
w = toeplitz_shape[1]*doubly_indices.shape[1] # 计算双重阻塞托普利茨矩阵的宽度,为一个托普利茨矩阵的宽度乘以索引矩阵的宽度
doubly_blocked_shape = [h, w] # 创建一个列表,存储双重阻塞托普利茨矩阵的形状
doubly_blocked = np.zeros(doubly_blocked_shape) # 创建一个全零的矩阵,形状为双重阻塞托普利茨矩阵的形状
# tile toeplitz matrices for each row in the doubly blocked matrix
b_h, b_w = toeplitz_shape # hight and withs of each block
for i in range(doubly_indices.shape[0]):
for j in range(doubly_indices.shape[1]):
start_i = i * b_h # 计算双重阻塞托普利茨矩阵中每个块的起始行位置
start_j = j * b_w # 计算双重阻塞托普利茨矩阵中每个块的起始列位置
end_i = start_i + b_h # 计算双重阻塞托普利茨矩阵中每个块的结束行位置
end_j = start_j + b_w # 计算双重阻塞托普利茨矩阵中每个块的结束列位置
doubly_blocked[start_i: end_i, start_j:end_j] = toeplitz_list[doubly_indices[i,j]-1] # 将列表中对应的托普利茨矩阵复制到双重阻塞托普利茨矩阵中的相应位置
if print_ir: print('doubly_blocked: ', doubly_blocked) # 如果print_ir为真,打印双重阻塞托普利茨矩阵
# convert I to a vector
vectorized_I = matrix_to_vector(I) # 调用之前定义的函数,将输入矩阵转换为一个向量
if print_ir: print('vectorized_I: ', vectorized_I) # 如果print_ir为真,打印转换后的向量
# get result of the convolution by matrix mupltiplication
result_vector = np.matmul(doubly_blocked, vectorized_I) # 用numpy库中的matmul函数,将双重阻塞托普利茨矩阵和向量相乘,得到卷积的结果向量
if print_ir: print('result_vector: ', result_vector) # 如果print_ir为真,打印结果向量
# reshape the raw rsult to desired matrix form
out_shape = [output_row_num, output_col_num] # 创建一个列表,存储输出矩阵的形状
output = vector_to_matrix(result_vector, out_shape) # 调用之前定义的函数,将结果向量转换为输出矩阵
if print_ir: print('Result of implemented method: \n', output) # 如果print_ir为真,打印输出矩阵
return output # 返回输出矩阵
# test on different examples
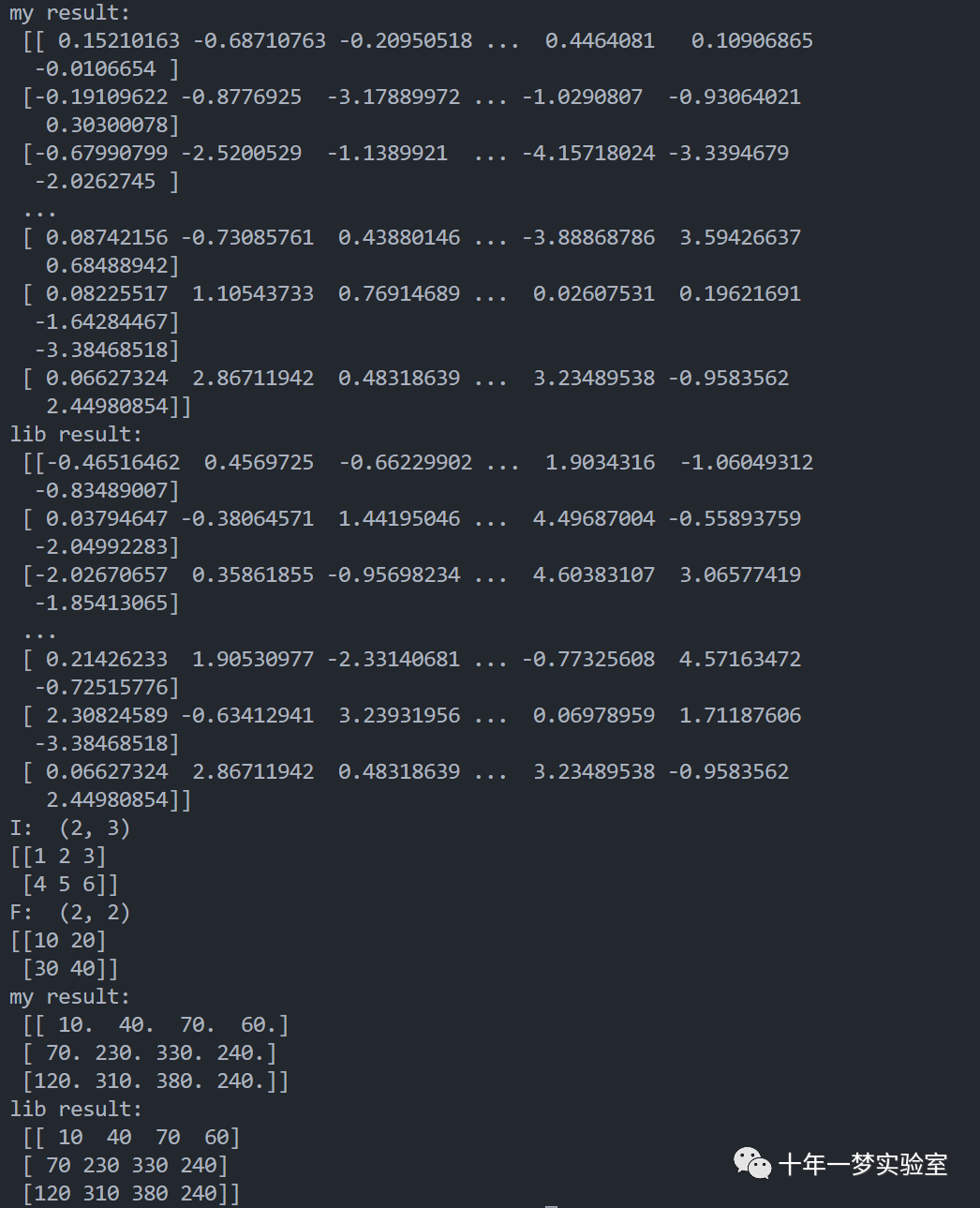
# fill I an F with random numbers
I = np.random.randn(10, 13) # 用numpy库中的random.randn函数,生成一个10行13列的矩阵,元素为服从标准正态分布的随机数,作为输入矩阵
F = np.random.randn(30, 70) # 用numpy库中的random.randn函数,生成一个30行70列的矩阵,元素为服从标准正态分布的随机数,作为滤波器矩阵
my_result = convolution_as_maultiplication(I, F) # 调用之前定义的函数,将输入矩阵和滤波器矩阵进行卷积运算,得到输出矩阵,赋值给my_result
print('my result: \n', my_result) # 打印my_result的内容
from scipy import signal # 导入scipy库中的signal模块,用于处理信号
lib_result = signal.convolve2d(I, F, "full") # 用signal模块中的convolve2d函数,将输入矩阵和滤波器矩阵进行卷积运算,得到输出矩阵,赋值给lib_result
print('lib result: \n', lib_result) # 打印lib_result的内容
assert(my_result.all() == lib_result.all()) # 用assert语句,断言my_result和lib_result的所有元素是否相等,如果不相等,抛出异常
# input signal
I = np.array([[1, 2, 3], [4, 5, 6]])
print('I: ', I.shape)
print(I)
# filter
F = np.array([[10, 20], [30, 40]])
print('F: ',F.shape)
print(F)
my_result = convolution_as_maultiplication(I, F) # 调用之前定义的函数,将输入矩阵和滤波器矩阵进行卷积运算,得到输出矩阵,赋值给my_result
print('my result: \n', my_result) # 打印my_result的内容
lib_result = signal.convolve2d(I, F, "full") # 用signal模块中的convolve2d函数,将输入矩阵和滤波器矩阵进行卷积运算,得到输出矩阵,赋值给lib_result
print('lib result: \n', lib_result) # 打印lib_result的内容
assert(my_result.all() == lib_result.all()) # 用assert语句,断言my_result和lib_result的所有元素是否相等,如果不相等,抛出异常输出结果:
4.2 卷积层可视化
如何使用反卷积技术进行特征可视化?

卷积层可视化

4.3 理论解释
对卷积网络的表示能力、映射函数特性的数学分析

将卷积网络看作是用一组级联的线性加权滤波器和非线性函数对数据进行散射

多层卷积网络与人脑视觉系统的关系

分层卷积神经网络

胶囊网络

五、 挑战与改进措施
从哪几个方面对卷积网络的改进

针对深层网络难以训练的问题,有哪些典型网络

5.1 卷积层
就卷积层而言,有哪些改进的方案

network in network机制介绍

如何选择合适的卷积核大小和数量?

1x1卷积核

如何使用1x1卷积核进行降维或升维操作?

5.2 池化层
针对池化层的改进措施有哪些

池化策略 L-P、SPP原理介绍

5.3 激活函数
激活函数的左饱和与右饱和,左硬饱和与右硬饱和

饱和性与梯度消失问题

ReLU ELU PReLU 激活函数与梯度消失问题

5.4 损失函数
全连接神经网络一般使用哪些损失函数

多任务损失函数

5.5 网络结构
高速公路网络



残差网络

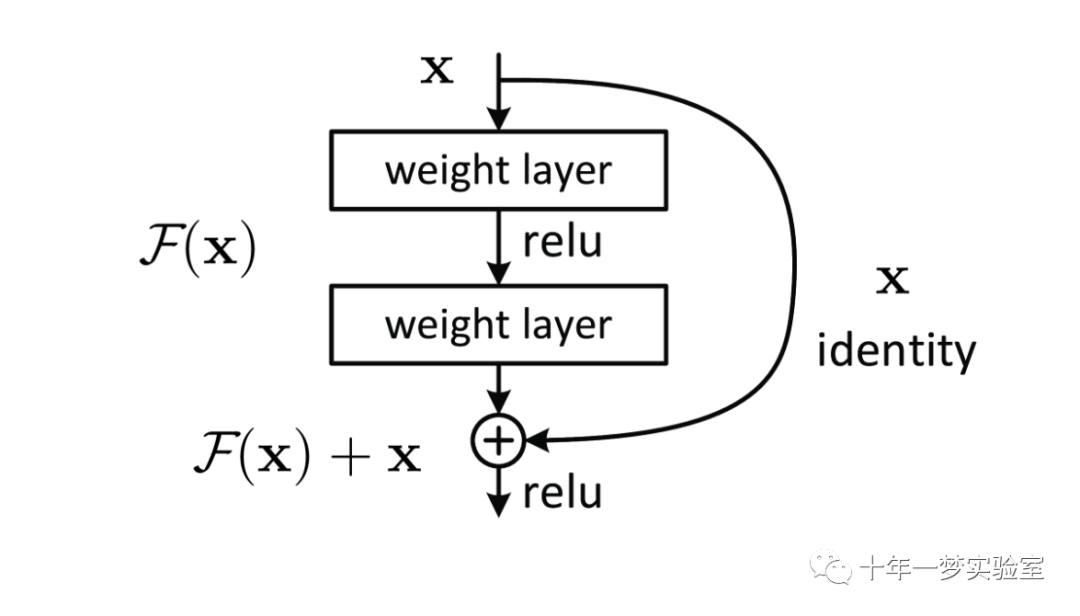
残差F(x)的形式

全卷积网络:
全卷积网络(Fully Convolutional Network,简称FCN)是一种深度学习模型,主要用于图像分割任务。与传统的卷积神经网络(CNN)不同,全卷积网络没有全连接层,而是将所有的全连接层替换为卷积层。
全卷积网络的基本结构如下:
输入图像
|
V
卷积层 - 激活函数 - 池化层
|
V
卷积层 - 激活函数 - 池化层
|
V
...
|
V
卷积层 - 激活函数 - 池化层
|
V
卷积层 - 激活函数
|
V
输出图像(分割结果)全卷积网络的一个重要特点是它可以接受任意大小的输入图像,并且输出图像的大小与输入图像的大小相同。这是因为全卷积网络没有全连接层,所以不需要固定输入图像的大小。此外,全卷积网络在每个像素上都进行了预测,因此输出图像的每个像素都对应了一个分割结果。
全卷积网络在图像分割任务中取得了非常好的效果,它的这种设计思想也影响了许多后续的深度学习模型的设计。例如,U-Net就是在全卷积网络的基础上,引入了跳跃连接,从而进一步提高了图像分割的精度。
全卷积网络有哪些变种?

卷积网络的多尺度处理

5.6 批量归一化

内部协变量漂移

在训练阶段,批量归一化(Batch Normalization,简称BN)会计算每个批次的均值和方差,然后用这些统计量来归一化数据。这是因为在训练阶段,我们一次处理一个批次的样本,所以可以直接计算出这个批次的均值和方差。
然而,在测试阶段,我们通常一次只对一个样本进行预测,因此无法计算出批次的均值和方差。为了解决这个问题,我们通常会在训练阶段计算出每一层的移动平均均值和方差,然后在测试阶段使用这些移动平均统计量来归一化数据。这样,即使在测试阶段一次只处理一个样本,我们也可以利用训练阶段的统计信息来进行归一化,从而保证模型的性能。这种方法被称为“推断模式”(Inference Mode)或“测试模式”(Test Mode)的批量归一化。
高速公路网络、残差网络、不使用全连接层的全卷积网络适用于哪些场景

参考网址:
https://github.com/alisaaalehi/convolution_as_multiplication/blob/main/Convolution_as_multiplication.ipynb
https://www.telesens.co/2018/04/09/initializing-weights-for-the-convolutional-and-fully-connected-layers/
https://ai.stackexchange.com/questions/11172/how-can-the-convolution-operation-be-implemented-as-a-matrix-multiplication
https://arxiv.org/abs/1512.03385 Deep Residual Learning for Image Recognition
The End