一、网络结构


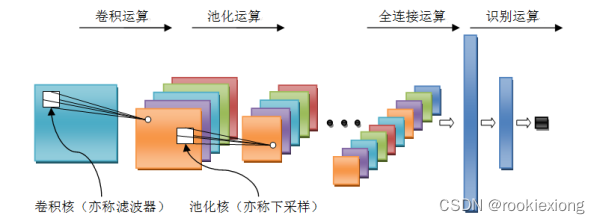
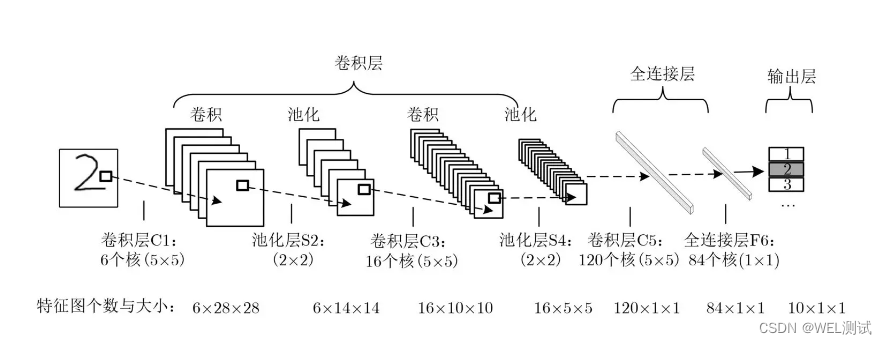
典型CNN结构
卷积神经网络是一种能够从图像、声音或其他类型的数据中学习特征的人工智能模型。你可以把它想象成一个有很多层的过滤器,每一层都能够提取出数据中的一些有用的信息,比如边缘、形状、颜色、纹理等。这些信息可以帮助卷积神经网络完成一些任务,比如识别物体、人脸、语音或文字。
卷积神经网络的名字中的“卷积”是一种数学运算,它可以把一个小的矩阵(叫做卷积核或滤波器)在一个大的矩阵(叫做输入或特征图)上滑动,每次滑动一小步,然后把卷积核和输入的对应位置的元素相乘,再把结果加起来,得到一个新的矩阵(叫做输出或特征图)。
卷积的作用是可以把输入中的某些模式或特征提取出来,比如卷积核中的元素是[[-1, -1, -1], [-1, 8, -1], [-1, -1, -1]],那么它就可以检测出输入中的边缘,因为边缘的地方,输入的元素值会有很大的变化,而卷积核的元素值会放大这种变化,从而在输出中形成一个明显的响应。
用下面的代码来比较了不同的卷积核对输入的影响:
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
from scipy.signal import convolve2d
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 定义一个函数,用来显示图像
def show_image(image, title):
plt.imshow(image, cmap='gray')
plt.title(title)
plt.axis('off')
plt.show()
# 读取一张图像,转换成灰度和数组格式
image = Image.open('shinianyimeng.png').convert('L')
image = np.array(image)
# 定义不同的卷积核
kernel_1 = np.array([[-1, -1, -1], [-1, 8, -1], [-1, -1, -1]]) # 边缘检测
kernel_2 = np.array([[1, 1, 1], [1, 1, 1], [1, 1, 1]]) / 9 # 平均滤波
kernel_3 = np.array([[0, -1, 0], [-1, 5, -1], [0, -1, 0]]) # 锐化
kernel_4 = np.array([[0, 1, 0], [1, -4, 1], [0, 1, 0]]) # 拉普拉斯
# 对图像进行卷积,得到不同的输出
output_1 = convolve2d(image, kernel_1, mode='same')
output_2 = convolve2d(image, kernel_2, mode='same')
output_3 = convolve2d(image, kernel_3, mode='same')
output_4 = convolve2d(image, kernel_4, mode='same')
# 显示原始图像和输出图像
""" show_image(image, '原始图像')
show_image(output_1, '边缘检测')
show_image(output_2, '平均滤波')
show_image(output_3, '锐化')
show_image(output_4, '拉普拉斯') """
images=[image,output_1,output_2,output_3,output_4]
titles=['原始图像','边缘检测','平均滤波','锐化','拉普拉斯']
n = 5 # 显示的图像数量
plt.figure(figsize=(15, 8))# 大小为15英寸宽,8英寸高
for i in range(5):
ax = plt.subplot(2, 3, i + 1)#第一行第i+1列
plt.imshow(images[i], cmap='gray')
plt.title(titles[i])
#plt.axis('off')
ax.get_xaxis().set_visible(False)#隐藏子图的x轴
ax.get_yaxis().set_visible(False)
plt.show()
卷积神经网络的每一层都有很多个卷积核,它们可以同时对输入进行卷积,得到多个输出,这些输出叫做特征图,它们可以表示输入中的不同特征。卷积神经网络的卷积核的元素值是可以通过学习得到的,也就是说,卷积神经网络可以自动地从数据中学习出最合适的卷积核,从而提取出最有用的特征。

常用卷积运算
卷积神经网络除了卷积层之外,还有一些其他的层,比如池化层、激活层、全连接层等。这些层的作用是:
池化层:池化层是对特征图进行降采样的操作,也就是把特征图变小,从而减少计算量和参数数量,同时保留最重要的信息。池化层有不同的类型,比如最大池化、平均池化等,它们的原理都是把特征图分成若干个小块,然后对每个小块取最大值或平均值,得到一个新的特征图。
激活层:激活层是对特征图的每个元素进行一个非线性变换的操作,也就是把特征图变得更复杂,从而增加卷积神经网络的表达能力。激活层有不同的类型,比如ReLU、sigmoid、tanh等,它们的原理都是把特征图的每个元素用一个函数来替换,得到一个新的特征图。
全连接层:全连接层是把特征图的所有元素连接到一个或多个输出节点的操作,也就是把特征图变成一个向量,从而可以用来做分类、回归或其他任务。全连接层有不同的类型,比如softmax、线性等,它们的原理都是把特征图的所有元素乘以一个权重矩阵,然后加上一个偏置向量,得到一个输出向量。
卷积神经网络的工作原理是,它先用卷积层和池化层从输入中提取出各种各样的特征,然后用全连接层把这些特征组合起来,得到最终的输出。
卷积神经网络是一种非常强大的人工智能模型,它可以在很多领域中发挥重要的作用,比如图像识别、自然语言处理、语音识别、自动驾驶等。卷积神经网络的原理并不难理解,只要你掌握了卷积、池化、激活和全连接这几个基本的操作,你就可以构建出自己的卷积神经网络,或者使用现成的卷积神经网络框架,比如TensorFlow、PyTorch等,来实现你想要的功能。
图像卷积操作前,对图像进行扩充的方式主要有以下几种:
零填充:在图像的边缘添加一些值为零的像素,使得图像的大小增加,卷积后的图像大小不变。
复制填充:在图像的边缘添加一些与边缘像素相同的像素,使得图像的大小增加,卷积后的图像大小不变。
镜像填充:在图像的边缘添加一些与边缘像素对称的像素,使得图像的大小增加,卷积后的图像大小不变。
循环填充:在图像的边缘添加一些与图像的另一边相同的像素,使得图像的大小增加,卷积后的图像大小不变。
多通道卷积:
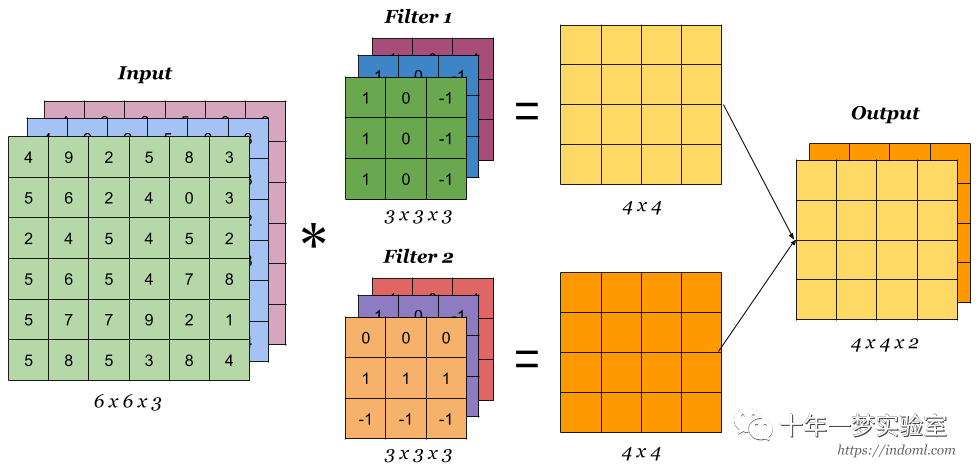
多通道卷积是一种在卷积神经网络中使用的技术,它可以处理具有多个输入和输出通道的图像或特征图。多通道卷积的目的是提取不同通道上的不同特征,增加网络的表达能力和学习能力。
多通道卷积的原理是,对于每个输出通道,使用一个形状为 c_i × k_h × k_w 的卷积核,其中 c_i 是输入通道的数目,k_h 和 k_w 是卷积核的高度和宽度。这个卷积核会对输入的每个通道进行互相关运算,然后将所有通道的结果相加,得到一个二维的输出。如果有多个输出通道,那么就需要多个这样的卷积核,形成一个形状为 c_o × c_i × k_h × k_w 的卷积核张量,其中 c_o 是输出通道的数目。这样,每个输出通道都可以从输入的所有通道中提取特征,而不是只从一个通道中提取。
多通道卷积的作用是,它可以让卷积核同时处理输入特征图的不同通道,从而捕捉输入特征图的不同特征,比如RGB图像的不同颜色,同时,它也可以让输出特征图有多个通道,从而增加输出特征图的维度和信息量,比如输出特征图的不同通道可以表示不同的特征或概念。多通道卷积可以提高卷积神经网络的性能和效果,但是也会增加卷积神经网络的参数数量和计算量,因此需要根据具体的任务和数据来选择合适的通道数和卷积核大小。
感受野(receptive field)



感受野的大小对卷积神经网络有什么影响?

最大池化与平均池化对比
特征提取能力:最大池化可以保留最显著的特征,比如边缘、角点等,从而突出输入特征图的主要特征;平均池化可以保留最平均的特征,比如背景、纹理等,从而平滑输入特征图的细节特征。因此,最大池化和平均池化可以提取出不同层次的特征,适用于不同的任务和数据。
鲁棒性和泛化能力:最大池化可以让特征图对输入特征图的一些微小的变化或噪声不敏感,从而增强卷积神经网络的鲁棒性和泛化能力;平均池化可以让特征图对输入特征图的一些重要的变化或信息敏感,从而降低卷积神经网络的鲁棒性和泛化能力。因此,最大池化和平均池化有不同的优缺点,需要根据不同的数据质量和复杂度来选择。
计算量和参数数量:最大池化和平均池化都可以把特征图的高度和宽度变小,从而降低特征图的维度,减少后续层的计算量和参数数量,提高卷积神经网络的运行效率和存储空间。因此,最大池化和平均池化在这方面没有太大的差别,只要选择合适的池化核的大小和步长,就可以达到理想的效果。
二、训练算法
反向传播算法(Copilot):卷积层、池化层、全连接层

import numpy as np
# 输入 X 的形状为 (n, c, h, w)
# 输出 Y 的形状为 (n, k, p, q)
# 卷积核 W 的形状为 (k, c, r, s)
# 偏置项 b 的形状为 (k,)
# 输出的梯度 dY 的形状为 (n, k, p, q)
# 输入的梯度 dX 的形状为 (n, c, h, w)
# 卷积核的梯度 dW 的形状为 (k, c, r, s)
# 偏置项的梯度 db 的形状为 (k,)
# 计算输入的梯度
dX = np.zeros_like(X)
for i in range(h):
for j in range(w):
for m in range(c):
for u in range(i, i + r):
for v in range(j, j + s):
for k in range(k):
dX[i, m, u, v] += dY[i, k, u - i, v - j] * W[k, m, u - i, v - j]
# 计算卷积核的梯度
dW = np.zeros_like(W)
for k in range(k):
for m in range(c):
for a in range(r):
for b in range(s):
for i in range(h):
for j in range(w):
dW[k, m, a, b] += dY[i, k, i + a, j + b] * X[i, m, i, j]
# 计算偏置项的梯度
db = np.zeros_like(b)
for k in range(k):
for i in range(p):
for j in range(q):
for m in range(n):
db[k] += dY[m, k, i, j]
import numpy as np
# 输入 X 的形状为 (n, c, h, w)
# 输出 Y 的形状为 (n, k, p, q)
# 卷积核 W 的形状为 (k, c, r, s)
# 偏置项 b 的形状为 (k,)
# 输出的梯度 dY 的形状为 (n, k, p, q)
# 输入的梯度 dX 的形状为 (n, c, h, w)
# 卷积核的梯度 dW 的形状为 (k, c, r, s)
# 偏置项的梯度 db 的形状为 (k,)
# 计算输入的梯度
dX = np.zeros_like(X)
for i in range(h):
for j in range(w):
for m in range(c):
for u in range(i, i + r):
for v in range(j, j + s):
for k in range(k):
dX[i, m, u, v] += dY[i, k, u - i, v - j] * W[k, m, u - i, v - j]
# 计算卷积核的梯度
dW = np.zeros_like(W)
for k in range(k):
for m in range(c):
for a in range(r):
for b in range(s):
for i in range(h):
for j in range(w):
dW[k, m, a, b] += dY[i, k, i + a, j + b] * X[i, m, i, j]
# 计算偏置项的梯度
db = np.zeros_like(b)
for k in range(k):
for i in range(p):
for j in range(q):
for m in range(n):
db[k] += dY[m, k, i, j]
import numpy as np
# 输入 X 的形状为 (n, d)
# 输出 Y 的形状为 (n, k)
# 权重矩阵 W 的形状为 (d, k)
# 偏置向量 b 的形状为 (k,)
# 激活函数 f 的类型为 relu, sigmoid, tanh 或 None
# 输出的梯度 dY 的形状为 (n, k)
# 输入的梯度 dX 的形状为 (n, d)
# 权重矩阵的梯度 dW 的形状为 (d, k)
# 偏置向量的梯度 db 的形状为 (k,)
# 计算输入的梯度
if f is None:
dX = np.dot(dY, W.T)
else:
# 计算激活函数的导数
if f == 'relu':
f_prime = lambda x: np.where(x > 0, 1, 0)
elif f == 'sigmoid':
f_prime = lambda x: x * (1 - x)
elif f == 'tanh':
f_prime = lambda x: 1 - x ** 2
else:
raise ValueError('Invalid activation function')
# 计算输入的梯度
dX = np.dot(dY * f_prime(X.dot(W) + b), W.T)
# 计算权重矩阵的梯度
if f is None:
dW = np.dot(X.T, dY)
else:
# 计算激活函数的导数
if f == 'relu':
f_prime = lambda x: np.where(x > 0, 1, 0)
elif f == 'sigmoid':
f_prime = lambda x: x * (1 - x)
elif f == 'tanh':
f_prime = lambda x: 1 - x ** 2
else:
raise ValueError('Invalid activation function')
# 计算权重矩阵的梯度
dW = np.dot(X.T, dY * f_prime(X.dot(W) + b))
# 计算偏置向量的梯度
if f is None:
db = np.sum(dY, axis=0)
else:
# 计算激活函数的导数
if f == 'relu':
f_prime = lambda x: np.where(x > 0, 1, 0)
elif f == 'sigmoid':
f_prime = lambda x: x * (1 - x)
elif f == 'tanh':
f_prime = lambda x: 1 - x ** 2
else:
raise ValueError('Invalid activation function')
# 计算偏置向量的梯度
db = np.sum(dY * f_prime(X.dot(W) + b), axis=0)随机梯度下降法(Stochastic Gradient Descent,SGD)

迁移学习:

另一版本各种层反向传播算法代码:
import numpy as np
from scipy import ndimage
# 定义卷积层的反向传播函数,输入参数为损失函数对输出的梯度dZ (m,i,j,k),输入x (m,h,w,c),过滤器w(f,f,c,k) 和填充方式padding c: 输入通道数。k:卷积核个数
def conv_backward(dZ,x,w,padding="same"):
# 获取输入的批次大小m
m = x.shape[0]
# 计算损失函数对偏置b的梯度db,为dZ在批次、高度、宽度维度上的平均值
db = (1/m)*np.sum(dZ, axis=(0,1,2), keepdims=True)
# 判断填充方式,如果是same,则计算填充的大小pad,为过滤器的一半
if padding=="same":
pad = (w.shape[0]-1)//2
else: #padding is valid - i.e no zero padding
# 如果是valid,则不进行填充,pad为0
pad =0
# 对输入x进行零填充,得到x_padded 对一个四维的数组 x 进行填充,使得它的第二维和第三维在两边各增加 pad 个元素,填充的值为 0,而其他维度不变
x_padded = np.pad(x,((0,0),(pad,pad),(pad,pad),(0,0)),'constant', constant_values = 0)
# 对x_padded增加一个维度,以便进行广播操作
x_padded_bcast = np.expand_dims(x_padded, axis=-1) # shape = (m, i, j, c, 1)
# 对dZ增加一个维度,以便进行广播操作
dZ_bcast = np.expand_dims(dZ, axis=-2) # shape = (m, i, j, 1, k) k:卷积核个数 m:批量
# 初始化损失函数对过滤器w的梯度dW,形状与w相同
dW = np.zeros_like(w)
# 获取过滤器的大小f
f=w.shape[0]
# 获取填充后的输入的宽度w_x
w_x = x_padded.shape[1]
# 对过滤器的每个元素进行遍历
for a in range(f):# a (0~f-1)
for b in range(f):# b (0~f-1)
# 计算损失函数对过滤器w的梯度dW,为dZ_bcast和x_padded_bcast的对应位置的乘积在批次、高度、宽度维度上的平均值
# 注意f-1 - a而不是f-a,因为索引从0...f-1而不是1...f
# 输出高度:w-f+1+a-a = w-(f-1) 输出宽度:w-f+1+b-b=w-(f-1)
dW[a,b,:,:] = (1/m)*np.sum(dZ_bcast*
x_padded_bcast[:,a:w_x-(f-1 -a),b:w_x-(f-1 -b),:,:],
axis=(0,1,2))
# 初始化损失函数对输入x的梯度dx,形状与x_padded相同
dx = np.zeros_like(x_padded,dtype=float)
# 计算对 dZ 进行填充的大小Z_pad,为过滤器的大小减一
Z_pad = f-1
# 对dZ进行零填充,得到dZ_padded
dZ_padded = np.pad(dZ,((0,0),(Z_pad,Z_pad),(Z_pad,Z_pad),
(0,0)),'constant', constant_values = 0)
# 对输入的每个批次、每个输出通道、每个输入通道进行遍历
for m_i in range(x.shape[0]):#批次
for k in range(w.shape[3]):# 输出通道
for d in range(x.shape[3]):#输入通道
# 计算损失函数对输入x的梯度dx,为dZ_padded和w的对应位置的卷积,去掉边缘部分
# 计算输入的第 m_i 个样本,所有高度,所有宽度,第 d 个输入通道的元素的梯度
# [f//2:-(f//2),f//2:-(f//2)] 表示从一个二维矩阵中选取从第 f//2 行到倒数第 f//2 行,从第 f//2 列到倒数第 f//2 列的部分,其中 f 是过滤器的大小,// 表示整除运算
dx[m_i,:,:,d]+=ndimage.convolve(dZ_padded[m_i,:,:,k],
w[:,:,d,k])[f//2:-(f//2),f//2:-(f//2)]
# 去掉dx的填充部分,得到最终的dx
dx = dx[:,pad:dx.shape[1]-pad,pad:dx.shape[2]-pad,:]
# 返回dx,dW,db
return dx,dW,db该代码定义了一个卷积层的反向传播函数,用于根据损失函数对卷积层输出的梯度,计算损失函数对卷积层输入、过滤器和偏置项的梯度。
该函数的输入参数包括损失函数对输出的梯度 dZ,输入 x,过滤器 w,和填充方式 padding。
该函数的输出为损失函数对输入、过滤器和偏置项的梯度,分别为 dx, dW, db。
该函数的主要步骤如下:
首先,计算损失函数对偏置项的梯度 db,为 dZ 在批次、高度、宽度维度上的平均值。
然后,根据填充方式确定填充的大小 pad,并对输入 x 进行零填充,得到 x_padded。
接着,对 x_padded 和 dZ 增加一个维度,以便进行广播操作,得到 x_padded_bcast 和 dZ_bcast。
然后,用双重循环遍历过滤器的每个元素,计算损失函数对过滤器的梯度 dW,为 dZ_bcast 和 x_padded_bcast 的对应位置的乘积在批次、高度、宽度维度上的平均值。
接着,初始化损失函数对输入的梯度 dx,并对 dZ 进行零填充,得到 dZ_padded。
然后,用三重循环遍历输入的每个批次、每个输出通道、每个输入通道,计算损失函数对输入的梯度 dx,为 dZ_padded 和 w 的对应位置的卷积,去掉边缘部分。
最后,去掉 dx 的填充部分,得到最终的 dx,并返回 dx, dW, db。
# 定义激活层的反向传播函数
def relu(z, deriv = False):
# z 是激活层的输入,deriv 是一个布尔值,表示是否求导数
# 返回激活层的输出或者激活函数的导数
if(deriv): #this is for the partial derivatives (discussed in next blog post)
# 如果求导数,返回一个布尔矩阵,表示 z 中的元素是否大于零
return z>0 #Note that True=1 and False=0 when converted to float
else:
# 如果不求导数,返回 z 的 relu 激活函数的值,即 z 和 0 的较大值
return np.multiply(z, z>0)这段代码的目的是定义一个激活层的反向传播函数,使用了 relu 激活函数。relu 激活函数的公式是 f(z)=max(0,z),它的导数是 f′(z)=1 如果 z>0,否则是 0。这个函数的参数有两个,一个是 z,表示激活层的输入,一个是 deriv,表示是否求导数。这个函数的返回值根据 deriv 的值而不同,如果 deriv 为 False,那么返回激活层的输出,即 z 的 relu 激活函数的值,如果 deriv 为 True,那么返回激活函数的导数,即 z 中的元素是否大于零的布尔矩阵。这个函数使用了 numpy 库的一些函数,例如 np.multiply 和 z>0,来实现矩阵的逐元素运算。这个函数可以用于卷积神经网络的反向传播过程中,计算激活层的误差项和梯度.
# 定义池化层的前向传播函数
def pool_forward(x,mode="max"):
# x 是池化层的输入,mode 是池化方式,可以是最大池化或平均池化
# 返回池化层的输出和一个掩码矩阵,用于反向传播
# 将输入重塑为一个六维矩阵,每个池化窗口对应一个子矩阵
x_patches = x.reshape(x.shape[0],x.shape[1]//2, 2,x.shape[2]//2, 2,x.shape[3])
if mode=="max":
# 如果是最大池化,对每个子矩阵求最大值,得到输出
out = x_patches.max(axis=2).max(axis=3)
# 生成一个掩码矩阵,表示输入中的元素是否等于输出中的元素
mask =np.isclose(x,np.repeat(np.repeat(out,2,axis=1),2,axis=2)).astype(int)
elif mode=="average":
# 如果是平均池化,对每个子矩阵求平均值,得到输出
out = x_patches.mean(axis=3).mean(axis=4)
# 生成一个掩码矩阵,表示输入中的元素的权重,即 1/4
mask = np.ones_like(x)*0.25
# 返回输出和掩码矩阵
return out,mask
# 定义池化层的反向传播函数
def pool_backward(dx, mask):
# dx 是损失函数对池化层输出的梯度,mask 是前向传播时生成的掩码矩阵
# 返回损失函数对池化层输入的梯度
# 将 dx 沿着宽度和高度方向复制两次,得到和输入相同大小的矩阵
return mask*(np.repeat(np.repeat(dx,2,axis=1),2,axis=2))这段代码的目的是定义一个池化层的前向传播和反向传播函数,使用了最大池化或平均池化的方式。池化层的作用是对输入的特征图进行降采样,减少参数和计算量,增加模型的鲁棒性。这个函数的参数和返回值如下:
前向传播函数的参数有两个,一个是 x,表示池化层的输入,一个是 mode,表示池化方式,可以是最大池化或平均池化。前向传播函数的返回值有两个,一个是 out,表示池化层的输出,一个是 mask,表示一个掩码矩阵,用于反向传播。
反向传播函数的参数有两个,一个是 dx,表示损失函数对池化层输出的梯度,一个是 mask,表示前向传播时生成的掩码矩阵。反向传播函数的返回值有一个,就是损失函数对池化层输入的梯度。
具体的计算过程如下:
在前向传播函数中,首先将输入重塑为一个六维矩阵,每个池化窗口对应一个子矩阵,然后根据 mode 的值,对每个子矩阵求最大值或平均值,得到输出。同时,生成一个掩码矩阵,表示输入中的元素是否等于输出中的元素(最大池化)或者输入中的元素的权重(平均池化),用于反向传播。
在反向传播函数中,首先将 dx 沿着宽度和高度方向复制两次,得到和输入相同大小的矩阵,然后用 mask 乘以这个矩阵,得到损失函数对池化层输入的梯度。这个过程可以看作是将 dx 的梯度分配到输入的相应位置上。
这段代码使用了 numpy 库的一些函数,例如 np.reshape, np.max, np.mean, np.isclose, np.repeat, np.ones_like 等,来实现矩阵的重塑,求最大值,求平均值,比较相等,复制,生成全一矩阵等操作。这个函数可以用于卷积神经网络的前向传播和反向传播过程中,实现池化层的功能。
# 定义全连接层的反向传播函数
def fc_backward(dA,a,x,w,b):
# dA 是损失函数对全连接层输出的梯度,a 是全连接层的输入,x 是全连接层的前一层的输出,w 是全连接层的权重矩阵,b 是全连接层的偏置向量
# 返回损失函数对全连接层输入、权重矩阵和偏置向量的梯度,分别为 dx, dW, db
# 获取输入的样本数
m = dA.shape[1]
# 计算全连接层的输入的梯度,即对输出的梯度乘以 relu 激活函数的导数
dZ = dA*relu(a,deriv=True)
# 计算权重矩阵的梯度,即对输入的梯度和前一层的输出的矩阵乘法的平均值
dW = (1/m)*dZ.dot(x.T)
# 计算偏置向量的梯度,即对输入的梯度求和
db = (1/m)*np.sum(dZ,axis=1,keepdims=True)
# 计算前一层的输出的梯度,即对权重矩阵的转置和输入的梯度的矩阵乘法
dx = np.dot(w.T,dZ)
# 返回输入、权重矩阵和偏置向量的梯度
return dx, dW,db这段代码的目的是定义一个全连接层的反向传播函数,使用了 relu 激活函数。全连接层的作用是对输入的特征进行线性变换和非线性激活,实现分类或回归的功能。这个函数的参数和返回值如下:
反向传播函数的参数有五个,一个是 dA,表示损失函数对全连接层输出的梯度,一个是 a,表示全连接层的输入,一个是 x,表示全连接层的前一层的输出,一个是 w,表示全连接层的权重矩阵,一个是 b,表示全连接层的偏置向量。反向传播函数的返回值有三个,分别是损失函数对全连接层输入、权重矩阵和偏置向量的梯度,分别为 dx, dW, db。
具体的计算过程如下:
在反向传播函数中,首先获取输入的样本数,然后计算全连接层的输入的梯度,即对输出的梯度乘以 relu 激活函数的导数。然后计算权重矩阵的梯度,即对输入的梯度和前一层的输出的矩阵乘法的平均值。然后计算偏置向量的梯度,即对输入的梯度求和。最后计算前一层的输出的梯度,即对权重矩阵的转置和输入的梯度的矩阵乘法。
这段代码使用了 numpy 库的一些函数,例如 np.sum, np.dot, np.multiply 等,来实现矩阵的求和,矩阵乘法,逐元素相乘等操作。这个函数可以用于卷积神经网络的反向传播过程中,计算全连接层的误差项和梯度。
# 定义 softmax 层的反向传播函数
def softmax_backward(y_pred, y, w, b, x):
# y_pred 是 softmax 层的输出,y 是真实的标签,w 是 softmax 层的权重矩阵,b 是 softmax 层的偏置向量,x 是 softmax 层的输入
# 返回损失函数对 softmax 层输入、权重矩阵和偏置向量的梯度,分别为 dx, dW, db
# 获取输入的样本数
m = y.shape[1]
# 计算 softmax 层的输入的梯度,即对输出和真实标签的差值
dZ = y_pred - y
# 计算权重矩阵的梯度,即对输入的梯度和输入的矩阵乘法的平均值
dW = (1/m)*dZ.dot(x.T)
# 计算偏置向量的梯度,即对输入的梯度求和
db = (1/m)*np.sum(dZ,axis=1,keepdims=True)
# 计算输入的梯度,即对权重矩阵的转置和输入的梯度的矩阵乘法
dx = np.dot(w.T,dZ)
# 返回输入、权重矩阵和偏置向量的梯度
return dx, dW,db这段代码的目的是定义一个 softmax 层的反向传播函数,使用了 softmax 激活函数和交叉熵损失函数。softmax 层的作用是对输入的特征进行归一化和分类,实现多分类的功能。这个函数的参数和返回值如下:
反向传播函数的参数有五个,一个是 y_pred,表示 softmax 层的输出,一个是 y,表示真实的标签,一个是 w,表示 softmax 层的权重矩阵,一个是 b,表示 softmax 层的偏置向量,一个是 x,表示 softmax 层的输入。反向传播函数的返回值有三个,分别是损失函数对 softmax 层输入、权重矩阵和偏置向量的梯度,分别为 dx, dW, db。
具体的计算过程如下:
在反向传播函数中,首先获取输入的样本数,然后计算 softmax 层的输入的梯度,即对输出和真实标签的差值。然后计算权重矩阵的梯度,即对输入的梯度和输入的矩阵乘法的平均值。然后计算偏置向量的梯度,即对输入的梯度求和。最后计算输入的梯度,即对权重矩阵的转置和输入的梯度的矩阵乘法。
这段代码使用了 numpy 库的一些函数,例如 np.sum, np.dot 等,来实现矩阵的求和,矩阵乘法等操作。这个函数可以用于卷积神经网络的反向传播过程中,计算 softmax 层的误差项和梯度。
参考网址:
https://www.analyticsvidhya.com/blog/2022/01/convolutional-neural-network-an-overview/ Convolutional Neural Network: An Overview (analyticsvidhya.com)
https://mukulrathi.com/demystifying-deep-learning/conv-net-backpropagation-maths-intuition-derivation/ 卷积神经网络中的反向传播 (mukulrathi.com)
https://medium.com/@ngocson2vn/a-gentle-explanation-of-backpropagation-in-convolutional-neural-network-cnn-1a70abff508b A gentle explanation of Backpropagation in Convolutional Neural Network (CNN) | by Son Nguyen | Medium
https://zhuanlan.zhihu.com/p/61898234 卷积神经网络(CNN)反向传播算法推导 - 知乎 (zhihu.com)