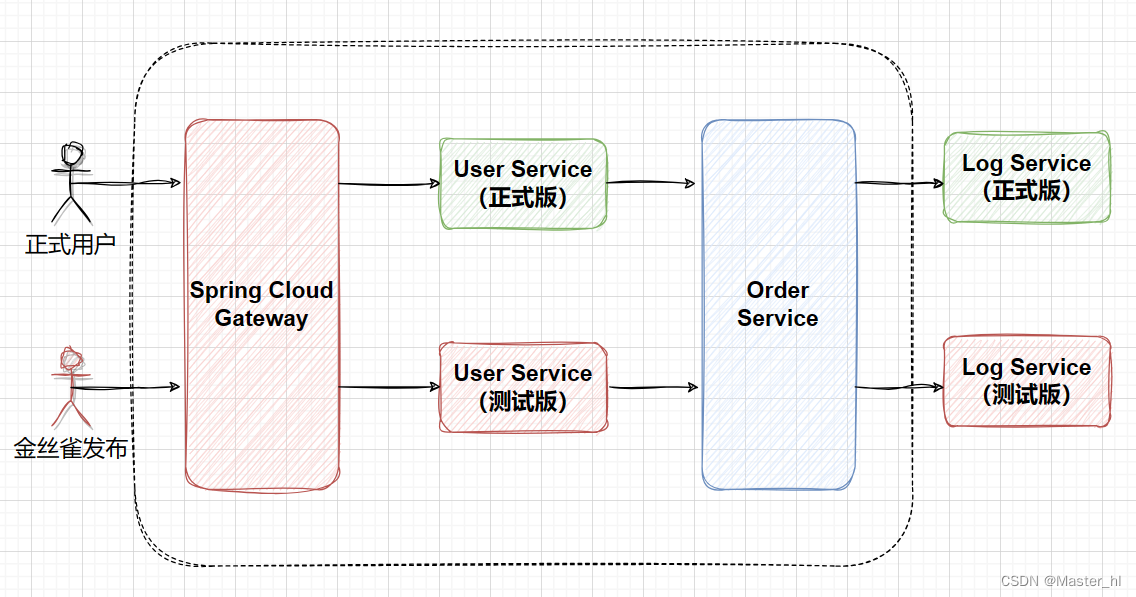
当我们深入研究大型语言模型(LLM)的运作机制时,我们不可避免地会遇到一个被频繁讨论的问题——“幻觉”现象。这个术语在LLM的领域中指的是模型产生的输出与现实世界的不符,或者是基于错误的、误导性的信息。这种情况不仅削弱了模型的可靠性,也对用户造成了明显的困扰。例如,当用户寻求准确信息时,如果模型提供了基于过时或错误数据的答案,这不仅会误导用户,也可能导致更严重的后果。
解决这个问题的关键在于理解它的根源。幻觉现象的产生通常是多因素导致的,包括但不限于训练数据的质量和代表性、模型设计的复杂性,以及在特定情境中对于语言细微差别的理解能力。例如,一个关于科学的问题可能需要模型不仅理解问题的字面意思,还要理解科学领域的历史和当前进展。如果模型的训练数据不够全面或过时,它可能就无法提供准确的答案。
进一步地,要有效地解决这个问题,我们需要从多个角度入手。这包括但不限于改进训练数据的质量、增强模型的上下文理解能力,以及开发更加高级的算法来更好地处理复杂和多变的现实世界情境。例如,通过引入更多现实世界的例子和情境到训练数据中,可以帮助模型更好地理解和适应不断变化的环境。
此外,用户教育也是解决这个问题的一个重要方面。用户需要了解LLM的局限性,并且能够识别和怀疑那些可能基于错误或过时信息的回答。通过教育和提高意识,用户可以更加有效地使用这些工具,并在必要时寻求其他信息源以验证模型的回答。
综上所述,虽然“幻觉”现象在LLM中是一个挑战,但通过多维度的努力,包括技术创新和用户教育,我们可以朝着减少这类问题的方向迈进。这需要模型开发者、数据科学家、语言专家和最终用户的共同努力,以确保这些强大的工具能够在提供帮助的同时,也保持其信息的准确性和可靠性。
产生原因
1. 训练数据的局限性
大型语言模型的效果在很大程度上依赖于其训练数据的质量和多样性。这些模型通过分析和学习大量文本数据来建立对语言的理解。如果这些训练数据存在偏见、过时或不准确的问题,模型就可能在输出时反映这些问题。例如,如果模型主要使用特定地区或时期的数据进行训练,它可能在处理全球或跨文化的主题时表现出局限性。类似地,如果数据中包含过时的科学信息或历史事实,模型可能会生成基于这些不再准确的信息的答案。
2. 模型的泛化能力
泛化是指模型应用其在训练过程中学到的知识来处理新的、未见过的情况的能力。当LLM遇到在训练数据中未曾出现的新情况时,它们可能会做出不准确或不合适的推断。这种情况通常发生在模型试图将其学到的知识应用于不熟悉或复杂的场景时。例如,面对一个新兴的科技主题或一个少见的文化参考,模型可能无法提供准确的响应,因为它在训练数据中缺乏相应的信息或例子。
3. 上下文理解的局限
虽然LLM在处理和生成自然语言方面表现出色,但它们在理解复杂上下文和隐含含义方面仍有限制。这意味着在处理需要深层次语义理解的任务时,模型可能无法完全捕捉到所有细节。这种局限性尤其明显在处理讽刺、幽默、比喻或多义性强的语言时。例如,一个充满双关的笑话或一个需要对特定文化背景有深刻理解的问题,可能会超出模型理解的范畴。
综上所述,"幻觉"现象在LLM中的产生是多方面因素共同作用的结果。从训练数据的局限性到模型的泛化能力,再到上下文理解的局限,这些因素共同定义了模型的性能和准确性。理解这些产生原因对于开发更高效、更准确的模型至关重要,同时也是确保LLM在实际应用中可靠性的关键。
解决方案
1. 改善训练数据集
优化训练数据集是减少模型产生误导信息可能性的关键步骤。这不仅包括增加数据的多样性,例如引入来自不同地区、文化和语言的数据,还包括提高数据的质量,确保数据的现代性和准确性。此外,重要的是要消除数据集中的偏见,确保模型不会无意中学习和复制这些偏见。例如,通过平衡不同性别、年龄和社会背景的数据,可以帮助模型更全面地理解和反映现实世界。
2. 模型的持续更新和微调
随着信息的不断更新和变化,模型也需要定期更新以反映这些变化。这可以通过周期性的重新训练或微调模型来实现。例如,对于一个基于当前新闻事件生成内容的模型,定期更新是必不可少的,以确保它提供的信息是最新的。此外,微调模型以适应特定的应用场景或用户需求也是提高其效能的有效方式。
3. 增强上下文感知能力
改进模型的结构,使其更好地处理和理解复杂的上下文和隐含的含义,是提高模型性能的另一个重要方面。这包括增强模型的能力,以理解语言的多义性、讽刺和比喻,以及改进其对复杂话题和细微差别的敏感性。例如,开发更高级的自然语言处理技术,可以帮助模型更准确地理解用户的意图和语言中的细微差异。
4. 人工审核与干预
在关键应用中结合人工审核,可以显著提高模型输出的准确性和可靠性。尤其在高风险或高影响力的领域(如医疗、法律或金融服务),人工审核是不可或缺的。这不仅可以帮助纠正模型的错误,还可以提供关于模型性能的宝贵反馈,进一步指导模型的改进。
5. 建立用户反馈机制
用户反馈是模型改进的重要资源。通过建立有效的反馈机制,开发者可以收集关于模型性能的真实用户体验和建议。这些反馈可以用于识别和解决模型在特定应用中的问题,帮助模型开发者更好地理解用户需求和预期。
6. 透明度和教育
增加对模型工作原理的透明度,以及教育用户理解模型的局限性和正确使用方式,是另一个重要的解决方案。通过提供关于模型如何工作的清晰信息,以及关于其潜在偏差和局限性的警告,可以帮助用户更加明智地使用这些工具。此外,教育用户如何识别可能的错误或误导性信息,也是提高整体系统效能的关键。
总体而言,这些解决方案的实施需要来自多个领域的协作,包括数据科学、软件工程、用户体验设计和伦理学。通过这种跨学科的努力,我们可以朝着制造更精准、更可靠且更具包容性的大型语言模型迈进。
结论
解决大型语言模型(LLM)中的“幻觉”问题确实是一个复杂且持续的过程,它不仅涉及到技术层面的挑战,还涉及到伦理和社会层面的考量。这一问题的解决需要来自数据科学家、软件工程师、语言学家、伦理学家以及用户的共同努力。通过不断的技术创新和优化,我们可以逐步提高模型的准确性和可靠性。
在技术层面上,持续的数据质量管理和模型更新是关键。这包括定期检查和更新训练数据集,以及通过最新的研究成果不断优化模型的架构和算法。同时,增加模型对上下文的理解能力和其处理复杂语言问题的灵活性,将有助于提高其在各种情境下的表现。
伦理和社会层面的考量也至关重要。随着LLM的应用范围日益扩大,确保这些模型的使用不会加剧社会不平等或传播有害的偏见变得尤为重要。这需要从模型设计的初期就考虑到伦理问题,并在整个开发过程中保持对社会影响的持续关注。
此外,用户的角色也不可忽视。提高用户对LLM潜在局限性的认识,教育他们如何有效且负责任地使用这些工具,将有助于提高模型的整体使用效果和安全性。用户反馈和参与可以为模型的持续改进提供宝贵的输入。
总之,通过跨领域专家的协作、技术的不断发展以及社会和伦理因素的综合考虑,我们可以朝着构建更加精准、可靠且负责任的大型语言模型迈进。这不仅将推动技术的进步,还将确保这些强大的工具能够在尊重和促进社会福祉的同时,更好地服务于人类。