@[TOC] Deep Residual Learning for Image Recognition
论文

1. 文章主要想解决什么问题,用了什么方法
深度神经网络在训练过程中的3个关键问题:
梯度消失/爆炸问题:随着网络层数的增加,梯度在反向传播过程中可能会变得非常小(梯度消失)或者非常大(梯度爆炸),这会阻碍网络的收敛。
退化问题:随着网络深度的增加,网络的准确率在达到一定深度后不再提升,反而可能会下降。这种现象称为退化问题,它表明简单地增加网络层数并不能保证性能的提升。
优化困难:深层网络可能难以优化,尤其是在网络非常深的情况下。这可能导致训练过程缓慢或者无法找到最优解。
为了解决这些问题,文章提出了以下解决方案:
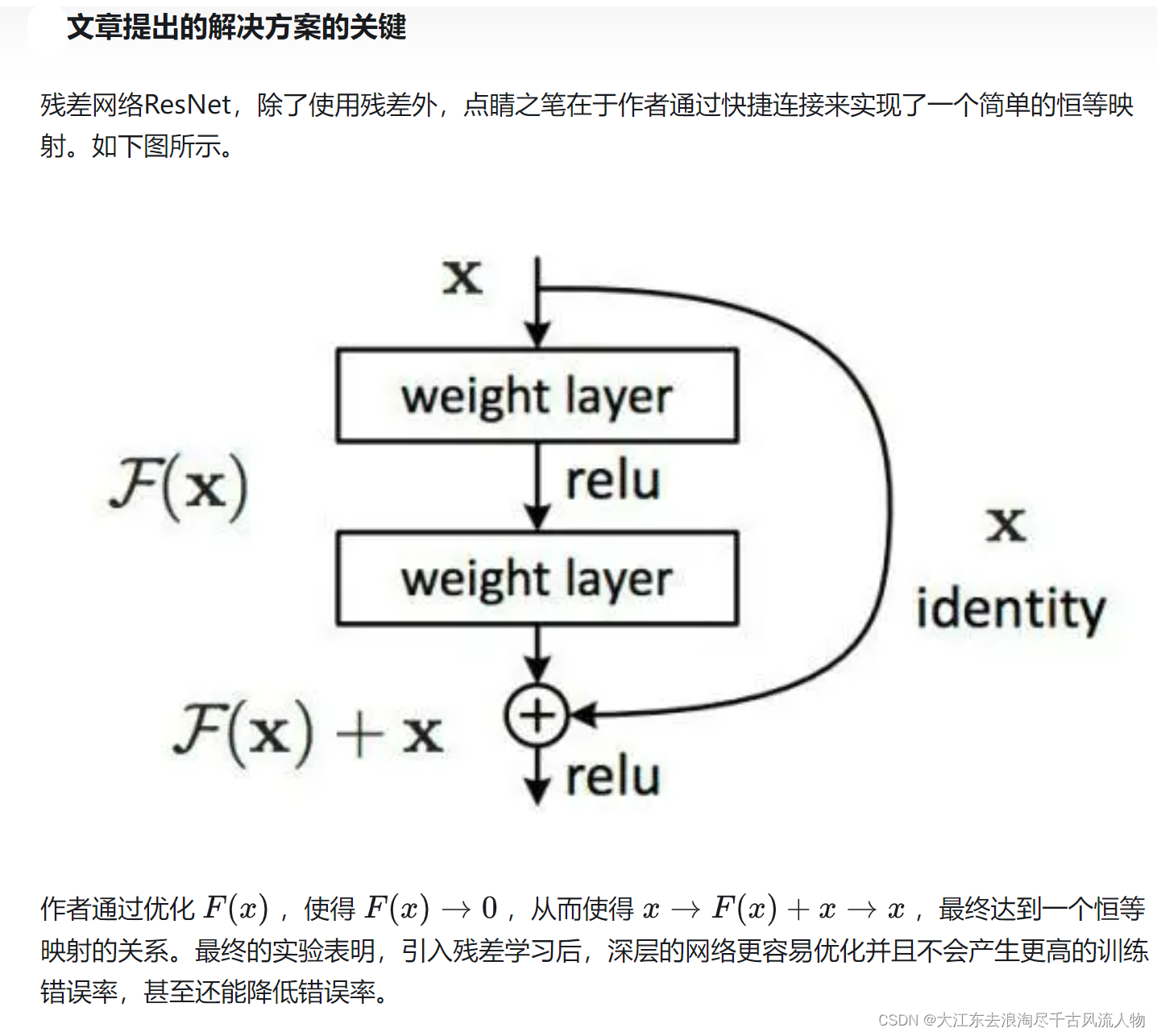
残差学习:通过将网络层设计为学习输入的残差映射(即输出是输入加上网络层的输出),而不是直接学习映射本身,可以更容易地优化网络。
快捷连接(Shortcut Connections):在网络中引入跳跃连接,这些连接允许输入直接传递到网络的后面部分,从而帮助网络学习残差映射。
瓶颈架构(Bottleneck Architecture):为了提高网络的效率和减少计算复杂度,作者提出了一种瓶颈架构,它在每个残差块中使用1×1、3×3和1×1的卷积层,其中3×3的卷积层是瓶颈部分。
这些方法共同使得网络能够在更深的层次上有效地学习复杂的映射,同时保持较低的计算成本和内存需求。通过这些技术,作者成功地训练了超过1000层的网络,并在多个视觉识别任务上取得了显著的性能提升。
2. 如何解决1种提到的问题
基于残差学习、快捷连接(Shortcut Connections)和瓶颈架构(Bottleneck Architecture)的方法为啥能够有效解决上述问题,主要原理是什么讷
残差学习:
- 梯度消失/爆炸问题:通过学习残差映射,网络的每一层不再是独立地学习整个映射,而是学习输入到输出的残差部分。这意味着即使在深层网络中,梯度也更容易通过这些残差路径传播,因为它们通常比直接映射要小得多,从而减少了梯度消失或爆炸的风险。
- 退化问题:残差学习使得网络能够学习到更复杂的功能,因为每一层都在尝试学习输入到输出的“差异”,而不是整个映射。这使得网络可以构建在更浅层网络的基础上,通过添加更多的层来学习更复杂的功能,而不会退化。
快捷连接:
啥叫快捷连接呢?

- 优化困难:快捷连接允许信息直接跳过某些层,这使得网络更容易学习到恒等映射(identity mapping),因为恒等映射是网络的默认状态。这种直接的路径为网络提供了一个稳定的参考点,有助于网络更快地收敛。
- 梯度消失/爆炸问题:快捷连接为梯度提供了一个额外的路径,这个路径不受中间层的影响,因此可以更有效地传递梯度,减少梯度消失或爆炸的可能性。
正对这一点具体网络设计如下:
- 瓶颈架构:
优化困难:瓶颈架构通过在每个残差块中使用1×1的卷积层来减少输入和输出的维度,然后再通过3×3的卷积层进行特征学习。这种设计减少了每一层的参数数量,从而降低了模型的复杂度,使得网络更容易优化。
具体表现形式如下

计算效率:瓶颈架构通过减少中间层的维度来降低计算成本,同时保持了网络的深度,这使得在有限的计算资源下可以训练更深的网络。
所以核心是这些方法通过提供更稳定的梯度流、简化网络结构、降低计算复杂度,以及允许网络更容易地学习到恒等映射,从而提高了深层网络的训练效率和性能。这些改进使得网络能够在更深的层次上有效地学习复杂的映射,同时保持较低的计算成本和内存需求。
在数学上,残差学习和快捷连接可以通过以下公式来描述:
残差学习:
假设我们有一个深层网络,其目标是学习一个映射函数 ( H ( x ) ) ( H(x) ) (H(x)),其中 ( x ) 是输入,( H(x) ) 是期望的输出。在残差学习中,我们不是直接学习 ( H(x) ),而是学习一个残差映射 ( F(x) ),即 ( H(x) - x )。然后,我们通过将 ( F(x) ) 加到输入 ( x ) 上来重新定义 ( H(x) ),即 ( H(x) = F(x) + x )。数学上,这可以表示为:
[ y = F ( x , W i ) + x ] [ y = F(x, {W_i}) + x ] [y=F(x,Wi)+x]
其中 ( y ) 是输出,( F(x, {W_i}) ) 是残差映射,( {W_i} ) 是网络中的权重。快捷连接:
快捷连接通过在网络中添加直接连接(shortcut connections)来实现。这些连接允许网络中的信息直接从输入传递到输出,绕过中间的某些层。在残差网络中,快捷连接通常用于将输入 ( x ) 添加到残差块的输出上。数学上,快捷连接可以表示为:
[ y = F(x, {W_i}) + x ]
其中 ( y ) 是输出,( F(x, {W_i}) ) 是残差块的输出,( x ) 是输入。瓶颈架构:
瓶颈架构通过在每个残差块中使用1×1的卷积层来减少输入和输出的维度,然后再通过3×3的卷积层进行特征学习。这种设计减少了每一层的参数数量,从而降低了模型的复杂度。数学上,瓶颈架构可以表示为:
[ y = B N ( R e L U ( C o n v ( B N ( C o n v ( x , W 1 ) , W 2 ) ) ) ) ] [ y = {BN}({ReLU}({Conv}({BN}({Conv}(x, {W_1}), {W_2})))) ] [y=BN(ReLU(Conv(BN(Conv(x,W1),W2))))]
其中 ( y ) 是输出,( \text{BN} ) 是批量归一化层,( \text{ReLU} ) 是修正线性单元激活函数, ( Conv ) ( \text{Conv} ) (Conv) 是卷积层,( {W_1} ) 和 ( {W_2} ) 是卷积层的权重。
这些数学表达式描述了残差网络的基本结构和操作,它们共同作用于提高网络的深度和性能,同时减少训练过程中的优化困难。
3. 为什么这样的设计可以解决1种提到的问题
这样的设计可以解决上述问题,主要是因为它们针对性地改善了深度学习网络在训练过程中遇到的挑战:
梯度消失/爆炸问题:
- 残差学习:通过学习残差映射 ( F(x) = H(x) - x ),网络的每一层都在尝试学习一个较小的残差,而不是整个映射 ( H(x) )。这意味着即使在深层网络中,梯度也更容易通过这些残差路径传播,因为残差通常比直接映射要小得多。这有助于缓解梯度消失问题,因为较小的梯度值更容易在反向传播中保持非零值。
- 快捷连接:快捷连接为梯度提供了一个直接的路径,绕过了中间层。这使得梯度可以直接从输出传回输入,减少了中间层对梯度的影响,从而减少了梯度消失或爆炸的风险。
退化问题:
- 残差学习:残差学习允许网络在更深的层次上学习更复杂的功能,同时保持对浅层网络的依赖。这意味着网络可以通过添加更多的层来逐渐学习更复杂的特征,而不会因为层数的增加而导致性能下降。
- 快捷连接:快捷连接确保了输入信息可以直接到达网络的深层,这有助于网络学习到更复杂的特征,同时保持了输入信息的完整性,从而避免了信息丢失导致的性能退化。
优化困难:
- 残差学习:残差学习使得网络更容易学习到恒等映射,因为网络的每一层都在尝试学习输入到输出的微小变化。这使得网络更容易找到一个良好的起点,从而加速了训练过程。
- 快捷连接:快捷连接提供了一个稳定的参考点,使得网络更容易优化。由于信息可以直接从输入传递到输出,网络可以更容易地找到一个好的解决方案,而不是被卡在局部最优解。
- 瓶颈架构:瓶颈架构通过减少中间层的维度来降低计算复杂度,这使得网络更容易训练。同时,1×1的卷积层可以看作是一种维度变换,它在不增加计算量的情况下,允许网络学习更复杂的特征映射。
总而言之 这些设计通过提供更稳定的梯度流、简化网络结构、降低计算复杂度,以及允许网络更容易地学习到恒等映射,从而提高了深层网络的训练效率和性能。这些改进使得网络能够在更深的层次上有效地学习复杂的映射,同时保持较低的计算成本和内存需求。
4. 经典网络对比
4.1 普通网络设计(参考VGG)
对于相同的尺寸的输出特征图谱,每层必须含有相同数量的过滤器。
如果特征图谱的尺寸减半,则过滤器的数量必须翻倍,以保持每层的时间复杂度。
卷积层(stride=2)进行下采样,网络末端以全局的均值池化层结束,1000的全连接层(Softmax激活)。共34层。
这样构建出的34层网络计算量远小于VGG-19
4.2 残差网络设计
基于普通网络,其中插入快捷连接(shortcut)来实现残差学习。快捷连接不引入额外的参数和复杂度。不仅在实践中很有吸引力,而且方便比较普通网络和残差网络,具有相同数量的参数、深度、宽度和计算成本。
详细见 【Pytorch】学习记录分享5——PyTorch卷积神经网络 中第2章节第4部分 4. 经典网络架构
5. 实验部分 当年刷爆各个数据库
基于ImageNet,图片被根据短边等比缩放,按照[256,480]区间的尺寸随机采样进行尺度增强。裁切224x224随机抽样的图像或其水平翻转,并将裁剪结果减去它的平均像素值,标准颜色的增强。批量正则化用在了每个卷积层和激活层之间,初始化权重为0。
使用SGD算法,mini-batch=256,
,(当到达迭代要求时把学习速率除以10),权重衰减,衰减率=0.0001,动量=0.9,无dropout。
1000个类的ImageNet 2012分类数据集。训练集:128万。测试集:50k。
一个字牛!
同时网络泛化能力也得到充分验证,凯神走向圣坛
![[论文精读] 自条件图像生成 - 【<span style='color:red;'>恺</span>明大<span style='color:red;'>神</span>新作,AIGC 新基准】](https://img-blog.csdnimg.cn/direct/879e8243f08d404a9a1e0c77ffa319d3.png#pic_center)
![[机器<span style='color:red;'>学习</span>-02] 数据可视化<span style='color:red;'>神</span>器:Matplotlib和Seaborn工具包实战图形<span style='color:red;'>大全</span>](https://img-blog.csdnimg.cn/direct/c1b47828028642e59cb81b6df5f83aab.png)