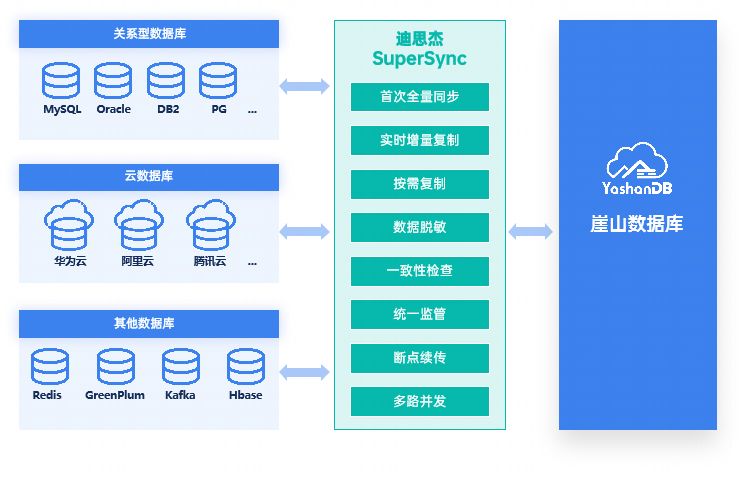
242.有效的字母异位词
数组、set、map,数组是比较高效查找的
函数功能
判断字符串 s 和 t 是否互为字母异位词。如果它们包含相同的字符且每个字符出现的次数也相同,那么它们互为字母异位词。
代码逻辑
长度检查:
if (s.length !== t.length) return false;如果
s和t的长度不相等,它们不可能是字母异位词,直接返回false。初始化计数器数组:
const resSet = new Array(26).fill(0); const base = "a".charCodeAt();resSet是一个长度为 26 的数组,用于存储每个小写字母的出现次数(假设s和t只包含小写字母)。base存储了字母 'a' 的 ASCII 码值,用于将字母转换为数组索引。
统计
s中字符出现次数:for (const i of s) { resSet[i.charCodeAt() - base]++; }遍历字符串
s,使用charCodeAt()函数获取每个字符的 ASCII 码值,然后根据base计算出索引,增加resSet中相应位置的计数。验证
t中的字符:for (const i of t) { if (!resSet[i.charCodeAt() - base]) return false; resSet[i.charCodeAt() - base]--; }- 遍历字符串
t,对于每个字符,检查resSet中对应位置的计数。如果计数为 0,则表示t中有一个在s中不存在的字符,或者字符出现次数不匹配,返回false。 - 减少
resSet中相应位置的计数。
- 遍历字符串
返回结果:
return true;果代码执行到这里,说明
s和t是字母异位词,返回true。
总结
这个函数通过计数每个字符的出现次数,来判断两个字符串是否互为字母异位词。由于只用了一个固定长度的数组,它在处理只包含小写字母的字符串时非常高效。
49字母异位词
示例 1: 输入 ["eat", "tea", "tan", "ate", "nat", "bat"]
初始化哈希表:
- 创建一个空的
Map对象map。
- 创建一个空的
遍历字符串数组:
对于每个字符串
str在数组["eat", "tea", "tan", "ate", "nat", "bat"]中,执行以下步骤:"eat":
- 分解、排序并重新组合:
"eat" -> ["e", "a", "t"] -> ["a", "e", "t"] -> "aet" map.has("aet")返回false(因为 "aet" 还不在map中),所以执行map.set("aet", [])并添加 "eat" 到 "aet" 键对应的数组中。
- 分解、排序并重新组合:
"tea":
- 同样地,
"tea"排序后变为"aet"。 map.has("aet")返回true(因为 "aet" 已存在),所以直接将 "tea" 添加到 "aet" 键对应的数组中。
- 同样地,
"tan":
"tan"排序后变为"ant"。map.has("ant")返回false,所以执行map.set("ant", [])并添加 "tan" 到 "ant" 键对应的数组中。
"ate":
"ate"排序后也是"aet"。- 再次将 "ate" 添加到 "aet" 键对应的数组中。
"nat":
"nat"排序后变为"ant"。- 将 "nat" 添加到 "ant" 键对应的数组中。
"bat":
"bat"排序后变为"abt"。map.has("abt")返回false,所以执行map.set("abt", [])并添加 "bat" 到 "abt" 键对应的数组中。
提取并返回结果:
- 使用
Array.from(map.values())将map中的所有值(即分组后的字符串数组)转换为一个数组。 - 返回的数组是:
[["eat", "tea", "ate"], ["tan", "nat"], ["bat"]]。
- 使用
结果解释
函数 groupAnagrams 将每个字符串按字母排序后,使用排序结果作为键来分组所有字母异位词。最终返回的数组包含了分组好的字母异位词数组,每个子数组包含所有字符集相同的原始字符串。在这个例子中,"eat"、"tea" 和 "ate" 互为字母异位词,因此它们被分组在一起,同理可得其他分组。
438.找到字符串中所有字母异位词
初始化两个计数器数组:
pCount和sCount分别用于存储p和窗口内字符串的字符计数。遍历
p:对p中的每个字符进行计数。滑动窗口:遍历字符串
s,同时更新sCount数组来计算窗口内各字符的出现次数。窗口大小与
p相等时:比较sCount和pCount。如果两者完全一致,将左指针的位置加入结果数组。移动窗口:右指针每向右移动一次,左指针也相应地向右移动一次,以保持窗口大小不变。
这种方法通过在 s 上滑动一个固定大小的窗口并比较字符出现次数,有效地找出了所有 p 的异位词的起始索引。