需求背景
公司的业务主要是广告数据归因的,每天的pv数据和加粉数据粗粗算一下,一天几千万上亿是有的。由于数据量大,客户在后台查询时间跨度比较大的数据时,查询效率就堪忧。因而将数据聚合后导到clickhouse进行存储,目的只有一个就是加快查询,提高用户体验感。原本以为是个简单的需求,但是在中途还是遇到一些坑。在这里做一个简单的思路分享,后面工作久一些的铁子们应该用的上。
clickhouse文档
经验小结第一点
由于清洗历史数据的前期,可能会遇到统计错误,这就涉及到重复清洗的问题。既然需要重复清洗,那么历史数据就需要先删除。在clickhouse的官方文档中,是没有delete的语句的,他的删除语句其实有点像更新语句,严谨来说删除操作其实也是更新的一种。他的SQL语句如下:
ALTER TABLE 表名 DELETE WHERE + 条件
注意: clickhouse的删除操作不是同步的,而是异步的,并且时间不确定。就是说你在发送这条指令之后,如果后面立即进行新数据的插入,那么大概率的情况下会出现数据错误或者不一致的问题,我分析了一下,当我插入相同时间段的历史数据的时候,这个删除的指令有可能在删除我后面插入的数据,这里是一个大坑,切记!切记!切记!
那么怎么解决呢,如果你的数据比较少或者一天就聚合一两次,那你可以先执行删除的操作,隔一段时间后,再去执行插入的操作,虽然官方文档解释,异步执行的时间不确定,但是只有你在流量比较小的时候去执行,一般没什么问题。
经验小结第二点
因为clickhouse的设计机制中涉及分区的概念,简单理解就是,类似按一定维度去分表,比如按月份分别这种,既然分区,那就涉及到合并数据。在我们日常业务中,由于不可控的因素,偶发性其实出现重复数据是比较常见的问题。但也是一个比较令人痛疼的问题。
考虑到clickhouse删除数据的异步性,加上广告业务,面向B端的客户,数据的实时性也是比较重要的。所以用删除语句去删除再插入,显得就有点不靠谱了,所以下面就需要了解一下clickhouse集中常见的表引擎。
clickhouse官方文档介绍的几种表引擎

下面简单带一下其中的两种,不是说其他的不好,只是这两种我这次分析过,根据自己的业务需求去选择引擎就好。
CollapsingMergeTree
该引擎继承于 MergeTree,并在数据块合并算法中添加了折叠行的逻辑。
CollapsingMergeTree 会异步的删除(折叠)这些除了特定列 Sign 有 1 和 -1 的值以外,其余所有字段的值都相等的成对的行。没有成对的行会被保留。更多的细节请看本文的折叠部分。
因此,该引擎可以显著的降低存储量并提高 SELECT 查询效率。
他的建表语句如下:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = CollapsingMergeTree(sign)
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
CollapsingMergeTree 参数
sign — 类型列的名称: 1 是«状态»行,-1 是«取消»行。列数据类型 — Int8。
解释
这是什么意思呢,我解释一下,其实我个人感觉有点鸡肋,他的意思是你每次插入数据前,都需要插入两次,除了sign字段的值不一样,其他列数据都一样,这样,他在数据合并的过程中,带有-1标识的数据会跟之前的重复的历史数据相互抵消,只保留最新的这一条数据。这就是它处理重复数据的方法,官方的案例是这个样子的:
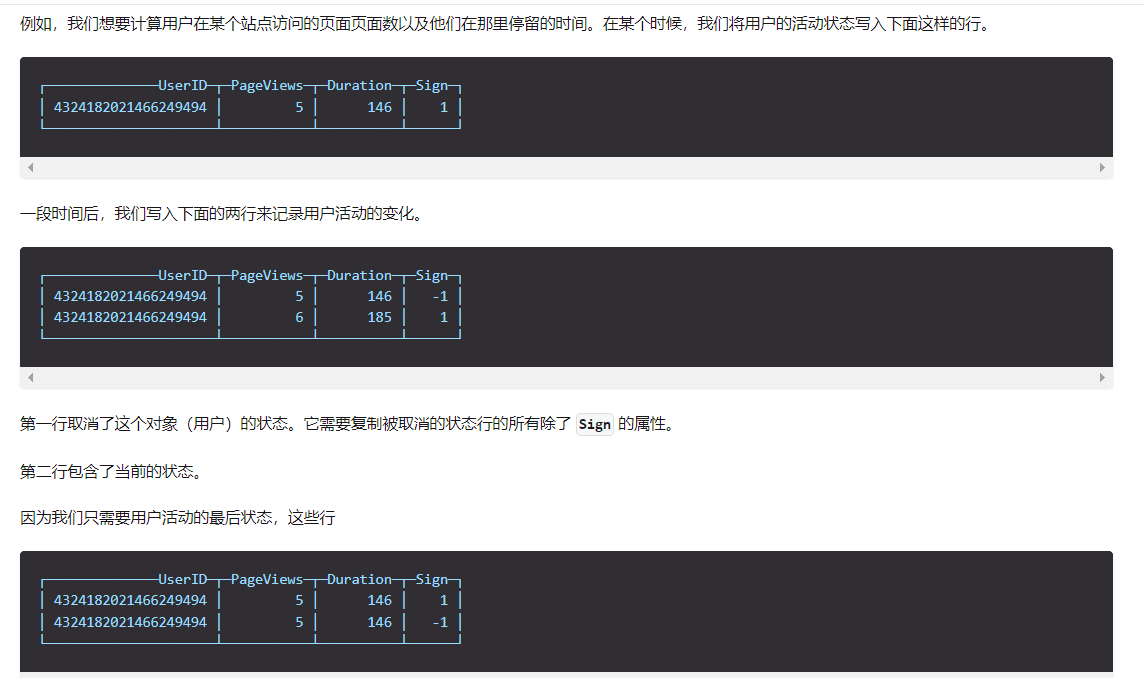
他这种在特性的场合是可以用的,比如某些数据状态需要经常性更新的时候,是可行的。
官方案例地址:案例地址
但是我没敢用,为什么?
假设我的表初始的时候,是空的,我压根就没有历史数据,那我的这两条数据是不是有可能会相互冲销掉。为此我特地查了一下,结果还真有这种可能性。OMG,算了,这个方式我还是不敢用,不然出问题直接卷铺盖走人。
最终采用的表引擎——ReplacingMergeTree表引擎
借用官方的解释:
该引擎和 MergeTree 的不同之处在于它会删除排序键值相同的重复项。
数据的去重只会在数据合并期间进行。合并会在后台一个不确定的时间进行,因此你无法预先作出计划。有一些数据可能仍未被处理。尽管你可以调用 OPTIMIZE 语句发起计划外的合并,但请不要依靠它,因为 OPTIMIZE 语句会引发对数据的大量读写。
因此,ReplacingMergeTree 适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现。(这个后续有解决的方式)
这里说的出现重复的数据,其实也是因为它的合并时间是不确定的,不一定马上就合并,所以你查询的时候可能会看到一些重复数据,不过它又提供了一道生门,这个很重要,你可以使用FINAL这个关键字进行查询,SQL语句如下:
slecct * from 表名 [WHERE ...] final
这样查询的时候就是查询最后插入的这条数据。建表语句如下:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = ReplacingMergeTree([ver])
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
expr:这个可以理解成mysql的唯一索引,后面合并数据的时候,它也是以此为依据判断是否是重复数据
举个例子
CREATE TABLE IF NOT EXISTS landing_page_day_statistics
(
advertiser_account_group_id bigint comment '项目ID',
landing_page_id bigint comment '落地页ID',
statistic_date timestamp comment '统计日期',
landing_page_channel_id bigint comment '渠道ID',
page_view_num bigint default 0 comment '浏览数',
created_at timestamp
)
ENGINE = ReplacingMergeTree() PARTITION BY toYYYYMM(statistic_date)
PRIMARY KEY (advertiser_account_group_id, landing_page_id, landing_page_channel_id, statistic_date)
ORDER BY (advertiser_account_group_id, landing_page_id, landing_page_channel_id, statistic_date)
COMMENT '测试表';
那么在这个引擎下,它就以advertiser_account_group_id, landing_page_id, landing_page_channel_id, statistic_date为唯一键进行判断是否是重复数据,是重复的数据,后续合并的时候就会合并成一条数据。
总结
clickhouse是一个高性能的查询数据库,它的强项在于缩短查询时间,其实严格来说就是用空间换时间。他很强大,但是也需要注意使用的姿势。对于官方文档,一定要多看几遍,看懂了,其实坑就踩平了,当然还有很多其他需要注意的点,后续继续整理给大伙分享一下。
好了,今天的内容就分享到这里,更多内容整理在公众号”安前码后“,一个专注分享使用干货的号,另外最近团队在做"韭盾专栏"号,对财经感兴趣的可以先关注,文章也都是干货,一篇推文一般需要成员花一周的时间去整理和分析。题外话,觉得文章有点小作用,实用的话,帮忙给个三连,感激不尽。
加油,铁子们!!