前言:
准备迈入scrapy-redis或者是scrapyd的领域进行一番吹牛~ 忽然想到,遗漏了中间件这个环节! 讲吧~太广泛了;不讲吧,又觉得有遗漏...所以,本章浅谈中间件;
(有问题,欢迎私信! 我写文告诉你解法)
正文:
当我们谈到 Scrapy 的中间件时,可以将其比作一个特殊的助手,负责在爬虫的不同阶段进行处理和干预。Scrapy 有两种类型的中间件:爬虫中间件和下载中间件。它们可以对请求、响应和爬虫的整个生命周期进行干预,以实现诸如修改请求、处理响应、处理异常等功能。
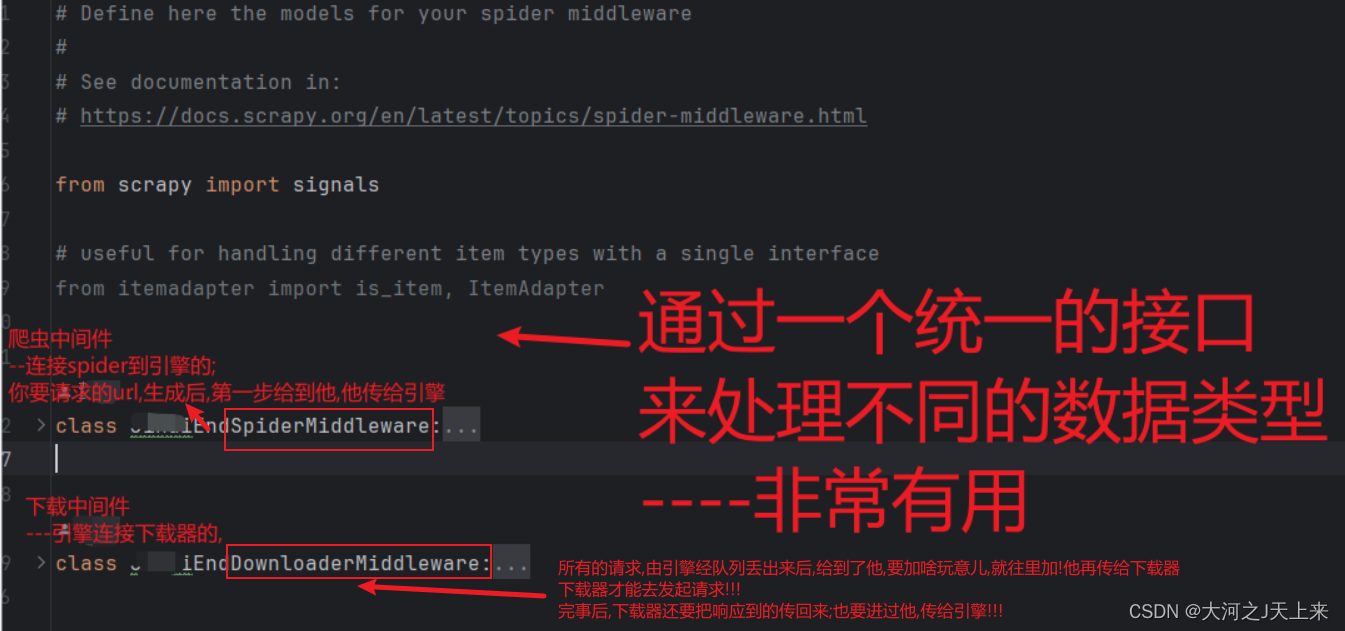
1. 爬虫中间件(Spider Middleware):
爬虫中间件负责处理爬虫和 Scrapy 引擎之间的通信。它们可以拦截并处理从引擎到爬虫、从爬虫到引擎进行的请求和响应。爬虫中间件提供了 `process_spider_input()` 和 `process_spider_output()` 方法,允许你处理请求和响应,或修改爬虫的输出结果。
案例:
我们的爬虫需要从一个电影网站上爬取电影的名称和评分。但是,该网站对于非登录用户来说,只显示了电影名称,评分信息需要通过另一个 API 请求获取。为了实现这个功能,我们可以编写一个爬虫中间件,通过拦截爬虫的输出,并发送额外的请求获取电影评分信息,并将其添加到爬虫的输出结果中。
import requests
from scrapy.exceptions import IgnoreRequest
class RatingsMiddleware:
def process_spider_output(self, response, result, spider):
for item in result:
if isinstance(item, dict) and 'movie_name' in item:
movie_name = item['movie_name']
ratings = self.get_movie_ratings(movie_name)
item['ratings'] = ratings
yield item
else:
yield item
def get_movie_ratings(self, movie_name):
# 发送评分请求,获取电影评分信息
api_url = f'https://api.example.com/ratings?movie_name={movie_name}'
response = requests.get(api_url)
if response.status_code == 200:
ratings = response.json().get('ratings')
return ratings
else:
raise IgnoreRequest(f'没抓取到这个电影: {movie_name}')
我们编写了一个自定义的爬虫中间件 RatingsMiddleware。在 process_spider_output() 方法中,我们通过检查爬虫输出的每个项,找到包含电影名称的字典项,并为每部电影发送一个额外的请求来获取评分信息。
在 get_movie_ratings() 方法中,我们使用 requests 发送评分请求,并从返回的响应中提取评分信息。如果请求成功,我们将评分信息添加到爬虫输出的对应电影项中,然后通过 yield 返回结果。如果请求失败,我们使用 raise IgnoreRequest 来忽略该项,并记录失败消息。
通过使用这个中间件,我们可以在爬虫的爬取过程中获取电影评分信息,并将其添加到输出结果中。这样,我们就可以在爬虫完成后拥有完整的电影信息,包括名称和评分。
2. 下载中间件(Downloader Middleware):
下载中间件在引擎和下载器之间进行干预和处理,管理请求和响应的传递过程。它们可以修改发送给下载器的请求和接收到的响应,还可以在发生异常或其他情况下进行处理。下载中间件提供了 `process_request()` 和 `process_response()` 方法,允许你处理请求和响应,或对其进行修改。
通过编写自定义的中间件,你可以利用这些钩子方法来实现一些自定义的功能,比如请求的动态修改、添加头部信息、处理异常、实现代理、处理重试逻辑等。使用中间件可以将这些功能模块化,提高代码可重用性,简化业务逻辑,以及进行一些全局的请求和响应处理。
Scrapy 提供了一些内置的中间件,如自动处理 Cookies、处理重试逻辑、处理 User-Agent 伪装等。此外,你还可以根据自己的需求编写和配置自定义的中间件,将其添加到 Scrapy 的中间件流程中,以实现更高级和个性化的功能。
案例1(随机请求头中间件):
import random
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
class RandomUserAgentMiddleware(UserAgentMiddleware):
def __init__(self, user_agent_list):
self.user_agent_list = user_agent_list
@classmethod
def from_crawler(cls, crawler):
settings = crawler.settings
user_agent_list = settings.get('USER_AGENT_LIST', [])
return cls(user_agent_list)
def process_request(self, request, spider):
request.headers.setdefault('User-Agent', random.choice(self.user_agent_list))
在这个自定义的中间件 RandomUserAgentMiddleware 中,继承了 Scrapy 的内置 UserAgentMiddleware 类,并重写了 process_request() 方法。在这个方法中,我们使用 random.choice() 函数从给定的 User-Agent 列表中随机选择一个 User-Agent,然后将其设置为请求头的 User-Agent。
要使用这个自定义中间件,需要在 Scrapy 的设置中添加一个名为 USER_AGENT_LIST 的设置项,其中包含了待选择的 User-Agent 列表。在 Scrapy 的设置文件(例如 settings.py)中进行配置:(例如)
USER_AGENT_LIST = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36',
# 添加更多的 User-Agent
]
DOWNLOADER_MIDDLEWARES = {
'your_project_name.RandomUserAgentMiddleware': 400,
# 其他下载中间件...
}
案例2:
假设我们的爬虫需要登录到一个受保护的网站,才能获取所需的数据。我们需要模拟登录,并在登录成功后保持会话(使用 Cookie)来进行后续的请求。
为了实现这个功能,我们将结合使用 CookieMiddleware 和 UserAgentMiddleware 来处理请求的 Cookie 和 User-Agent 头部信息。
from scrapy import Request
from scrapy.downloadermiddlewares.cookies import CookiesMiddleware
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
class LoginMiddleware:
def __init__(self):
self.login_url = 'https://example.com/login'
self.username = 'your_username'
self.password = 'your_password'
self.logged_in = False
def process_request(self, request, spider):
if not self.logged_in:
return self.login(request)
return None
def login(self, request):
# 发送登录请求
login_request = Request(
url=self.login_url,
method='POST',
formdata={
'username': self.username,
'password': self.password
}
)
login_request.meta['handle_httpstatus_list'] = [302] # 处理登录重定向
return login_request
class CustomHeadersMiddleware:
def process_request(self, request, spider):
# 动态添加自定义请求头信息
request.headers['Referer'] = 'https://example.com'
return None
# 将中间件添加到下载中间件的配置中
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': 700,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 800,
'your_project_name.LoginMiddleware': 750, # 自定义登录中间件
'your_project_name.CustomHeadersMiddleware': 900 # 自定义请求头中间件
}
在上述代码中,我们定义了 LoginMiddleware 作为自定义的登录中间件,它负责在请求中检查是否需要登录并发送登录请求。如果还未登录,则创建一个登录请求,并将其返回给 Scrapy 引擎,从而触发登录过程。
与此同时,我们还有一个自定义的 CustomHeadersMiddleware,用于动态添加自定义的请求头信息。
将这些中间件添加到 Scrapy 的下载中间件配置中(DOWNLOADER_MIDDLEWARES),并按照优先级顺序进行配置。
总结:
浅谈了 Scrapy 的中间件,用几个案例为例进行了讲解。其实,中间件的最大重要,莫过于"自定义"三个字! 你的爬虫花不花哨,全在这里面了! 特别是涉及逆向登录,渗T等,那不是这里能讲的~ 不过对于爬虫开发来说,一般没什么特别的网站需要破,基本用用scrapy自带的组件都能写好!
......没啥了,其实吧~搞爬虫没啥意思.....额!