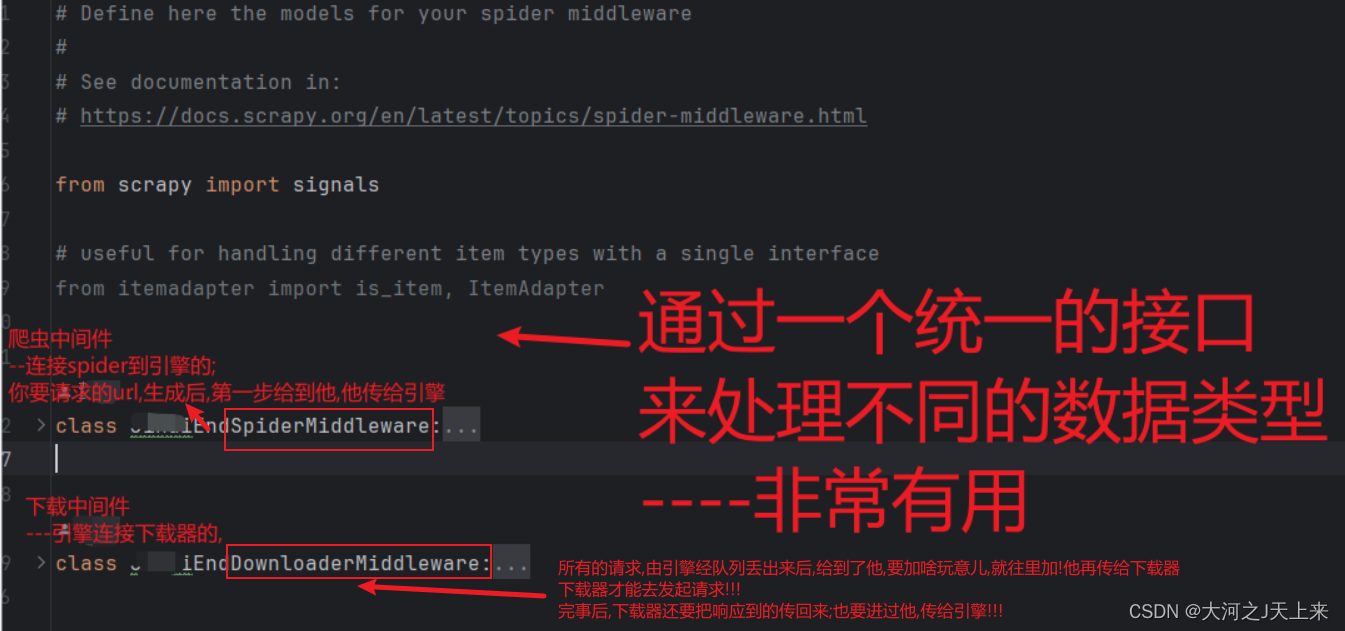
前言:
继续之前需要去深挖的中间件系列,https://hsnd-91.blog.csdn.net/article/details/136811799
,本章主要介绍爬虫中间件的HttpErrorMiddleware、OffsiteMiddleware和RefererMiddleware的用法!
正文
1. HttpErrorMiddleware
1.1 简述HttpErrorMiddleware的作用
HttpErrorMiddleware是Scrapy框架提供的Spider中间件之一,主要用于处理由于HTTP请求错误或异常导致的错误响应。它可以帮助我们更好地处理和解决各种HTTP错误情况,使爬虫能够更稳定和可靠地运行。
1.2 错误响应处理
1.2.1 处理常见的HTTP状态码
HttpErrorMiddleware可以默认处理一些常见的HTTP状态码,例如404(Not Found)和500(Internal Server Error)。当请求返回这些状态码时,HttpErrorMiddleware将生成一个相应的错误Request对象并将其发送到Spider的错误处理方法中。
1.2.2 自定义处理特定状态码
除了处理常见的HTTP状态码,我们还可以自定义处理特定的状态码。通过重写HttpErrorMiddleware的process_response方法,我们可以根据需要对其他状态码进行特定的处理,例如403(Forbidden)或429(Too Many Requests)。在自定义处理中,我们可以选择重新调度请求、记录日志、发送通知等。
1.2.3重新调度请求或执行其他操作
HttpErrorMiddleware提供了重新调度请求的机制,以便在处理错误响应时重新尝试请求。我们可以通过在Spider中的错误处理方法中,将原始的或修改后的Request对象返回,从而实现重新尝试请求。这样可以帮助我们处理临时错误,例如网络连接不稳定或目标服务器负载过高。
1.3 处理异常情况
1.3.1 异常处理的重要性
除了HTTP状态码处理外,HttpErrorMiddleware还负责处理网络连接故障、超时等异常情况。异常处理的重要性在于保护爬虫的健壮性和可靠性。一个良好的异常处理机制可以帮助我们及时捕获和处理异常,防止爬虫因异常情况而中断或崩溃。
1.3.2 如何处理网络连接故障、超时等异常情况
在处理网络连接故障、超时等异常情况时,我们可以使用HttpErrorMiddleware的process_exception方法。通过重写该方法,我们可以自定义处理异常的行为,例如记录日志、重新尝试请求、降低并发请求数等。以下是一种处理网络连接故障和超时的示例:
from scrapy.exceptions import IgnoreRequest
class HttpErrorMiddleware(object):
def process_exception(self, request, exception, spider):
if isinstance(exception, (ConnectionRefusedError, TimeoutError)):
# 自定义处理网络连接故障和超时的异常
# 例如记录日志、重新尝试请求等
spider.logger.error(f"连接错误--> {request.url}: {exception}")
return request
elif isinstance(exception, IgnoreRequest):
# 忽略特定异常的请求
return None
通过自定义处理网络连接故障和超时的异常,我们可以根据具体情况,选择如何应对这些异常,以避免在爬虫中断或中止的同时,增加对目标网站的压力和负荷。
ps:在处理异常时,要根据具体的爬虫需求和目标网站的特点选择适当的处理方法。这可能涉及配置适当的超时时间、使用合适的重试策略、限制并发请求数等措施。
2. OffsiteMiddleware
2.1. OffsiteMiddleware的作用和意义
OffsiteMiddleware是Scrapy框架提供的Spider中间件之一,主要用于控制爬虫的跟踪范围,确保爬虫只访问指定的域名下的链接。其作用和意义在于帮助我们限制爬虫的范围,防止无意间跟踪到其他域名的链接,同时避免爬虫的扩散和无限递归。
2.2. 控制爬虫的跟踪范围
2.2.1 跟踪同一域名内的链接
通过OffsiteMiddleware,默认情况下,爬虫只会跟踪和访问与起始URL属于同一域名的链接。这可以有效防止爬虫意外地跟踪到其他域名的链接,保证爬取在指定的范围内进行。
2.2.2 禁止跟踪其他域名的链接
如果想要完全禁止爬虫跟踪其他域名的链接,可以在Scrapy的配置文件(settings.py)中添加以下配置项:
OFFSITE_MIDDLEWARE_ENABLED = True
这样设置后,OffsiteMiddleware会拦截所有非同域名的链接,阻止其继续跟踪和访问。
2.3. 限制扩散和避免无限递归的方法
2.3.1指定ALLOWED_DOMAINS
为了更精确地控制爬虫的跟踪范围,可以在Scrapy的配置文件(settings.py)中设置ALLOWED_DOMAINS。ALLOWED_DOMAINS是一个包含允许访问的域名列表,只有属于这些域名范围内的链接才会被允许爬取。
以下是一个示例:
ALLOWED_DOMAINS = ['example.com', 'subdomain.example.com']
通过指定ALLOWED_DOMAINS,我们可以确保爬虫只在指定的域名范围内进行链接跟踪和数据抓取。
2.3.2设置DEPTH_LIMIT DEPTH_LIMIT
一个可选的配置项,用于限制爬虫的跟踪深度,避免无限递归和过深的爬取。可以在Scrapy的配置文件(settings.py)中设置DEPTH_LIMIT的值,表示允许爬虫访问的最大深度。以下是一个示例:
DEPTH_LIMIT = 3
设置DEPTH_LIMIT后,当爬虫达到指定的深度时,将停止继续跟踪该链接的子链接。这样可以避免爬虫过深地访问无限递归或无关的链接,从而限制爬虫的扩散并提高效率。
ps: 设置DEPTH_LIMIT需要根据目标网站的结构、爬虫的需求和资源消耗进行合理的配置。过小的值可能会导致爬取不完整,而过大的值可能会造成资源浪费和爬虫效率下降。
综上所述,通过OffsiteMiddleware和其他相关配置,我们可以灵活地控制爬虫的跟踪范围,限制爬取在指定的域名下进行,并避免扩散和无限递归的问题。
总结:
首先介绍了引用页面和RefererMiddleware的概念。引用页面记录了请求的来源页面,用于了解用户的行为和导航路径。在爬虫中,自动设置正确的Referer头非常重要,可以模拟正常用户行为,提高爬虫的稳定性和可靠性。Scrapy框架提供了RefererMiddleware中间件,方便我们设置Referer头。我们还学习了如何使用自定义的Referer生成逻辑,以应对特定的反爬虫机制。最后,通过处理反爬虫机制的参考页面布局,我们可以更好地理解如何应用这些概念和技术来提高爬虫的效果。