请大家关注我,本文章粉丝可见,我会一直更新下去。欢迎进QQ群交流:323140750,大家一起进步、学习。
人工智能(Artificial Intelligence,AI)在信用风险评估中的应用已经变得越来越重要,因为它可以提供更准确和高效的信用评估,帮助金融机构更好地管理风险。
7.2.1 传统信用评估方法的局限性
传统信用评估方法在某些情况下存在一些明显的局限性,这些局限性主要包括:
- 基于有限数据:传统信用评估主要依赖于信用报告中的信息,这些信息通常有限且基于过去的信用历史。这意味着对于没有或有有限信用历史的人,以及新兴市场或低收入地区的人们,传统方法可能无法提供准确的信用评估。
- 不包括非传统数据:传统信用评估通常不考虑非传统数据,如租赁历史、社交媒体活动、电子支付记录等。这些数据可能包含有关借款人信用风险的重要信息,但传统方法无法捕捉到这些信息。
- 滞后性:传统信用评估方法通常是滞后的,因为它们依赖于历史数据。这意味着当借款人的信用风险状况发生变化时,传统方法可能无法迅速反映这些变化。
- 不适用于新兴市场:在一些新兴市场和发展中国家,大多数人没有传统的信用历史记录,因此传统信用评估方法可能无法适用。这使得金融包容性成为一个挑战。
- 无法评估未来能力:传统信用评估主要关注借款人的过去信用表现,但无法准确评估借款人未来的还款能力。这在某些情况下可能导致误判。
- 未考虑个性化因素:传统信用评估方法通常不考虑借款人的个性化因素,如职业、教育水平、家庭状况等。这些因素可能对信用风险有重要影响,但未被充分考虑。
- 信用评分波动:信用评分可能会因信用报告中的错误或不一致性而波动。这可能导致借款人在不同时间或不同信用评估机构之间获得不一致的信用评分。
- 无法应对突发事件:传统信用评估方法通常无法应对突发事件,如自然灾害、经济危机或大流行病。这些事件可能会导致信用质量迅速下降,但传统方法无法提前预测或评估这些风险。
正是由于这些局限性,金融机构和信用评估机构越来越倾向于整合人工智能和大数据分析等新技术,以改善信用评估的准确性和全面性,同时也提高了金融包容性,使更多人能够获得贷款和信用。
7.2.2 机器学习与信用风险评估
机器学习在信用风险评估中的应用已经成为一种重要趋势,因为它可以有效地改善传统方法的准确性和效率。以下是机器学习在信用风险评估中的一些关键应用:
- 信用评分模型的改进:机器学习可以用于改进传统的信用评分模型。通过分析大量的数据和特征,机器学习算法可以识别潜在的非线性关系和模式,提高信用评分的准确性。例如,支持向量机(SVM)、决策树、随机森林和神经网络等算法可以用于建立更精确的信用评分模型。
- 非传统数据的整合:机器学习可以用于整合非传统数据,如社交媒体活动、在线购物历史、移动应用使用等,这些数据可以提供有关借款人信用风险的额外信息。通过分析这些非传统数据,机器学习可以更全面地评估借款人的信用状况。
- 实时信用决策:机器学习可以用于实时信用决策,使金融机构能够在几秒内做出贷款批准或拒绝的决策。这对于提供快速的借款决策和改善客户体验非常有价值。
- 特征选择和降维:机器学习可以帮助识别最重要的特征,从而降低了数据维度和模型复杂性,提高了模型的解释性。这有助于更好地理解为什么某个信用评分模型会给出特定的结果。
- 欺诈检测:机器学习可以用于欺诈检测,识别信用申请中的不寻常行为或可能的欺诈行为。这可以帮助金融机构减少欺诈风险。
- 风险预测和模型调整:机器学习可以用于预测借款人未来的信用表现,并根据实际表现调整信用评分模型。这有助于金融机构更好地管理信用风险。
- 个性化定价:机器学习可以帮助制定个性化的贷款定价策略,根据每个借款人的信用风险水平和特征。这可以提高贷款产品的定价准确性。
注意:尽管机器学习在信用风险评估中提供了许多潜在好处,但也需要注意数据隐私、模型解释性和公平性等问题。金融机构需要确保他们的机器学习模型符合法规要求,并采取措施来解释模型的决策过程,以确保不出现偏见或歧视性决策。此外,不断监测和更新机器学习模型也是确保其性能和准确性的关键。
请看下面的实例,功能是使用PyTorch构建和训练神经网络模型,以进行信用风险评估,并且包括了模型的保存、加载和损失可视化功能。这只是一个简单的示例,实际的信用风险评估任务可能需要更复杂的模型和更多的数据处理工作。
实例7-1:处理股票数据中的缺失值(源码路径:daima/7/fen.py)
实例文件fen.py的具体实现代码如下所示。
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, classification_report
import matplotlib.pyplot as plt
# 创建虚构的数据集
np.random.seed(0)
data = np.random.rand(1000, 5) # 1000个借款人,每个有5个特征
labels = (data.sum(axis=1) > 2.5).astype(int) # 根据特征之和大于2.5进行二分类
# 数据标准化
scaler = StandardScaler()
data = scaler.fit_transform(data)
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=42)
# 创建神经网络模型
class CreditRiskClassifier(nn.Module):
def __init__(self):
super(CreditRiskClassifier, self).__init__()
self.fc1 = nn.Linear(5, 10)
self.fc2 = nn.Linear(10, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
x = self.sigmoid(x)
return x
# 初始化模型、损失函数和优化器
model = CreditRiskClassifier()
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 将数据转换为PyTorch张量
X_train = torch.FloatTensor(X_train)
y_train = torch.FloatTensor(y_train)
X_test = torch.FloatTensor(X_test)
y_test = torch.FloatTensor(y_test)
# 训练模型
epochs = 1000
train_losses = []
test_losses = []
for epoch in range(epochs):
optimizer.zero_grad()
outputs = model(X_train)
loss = criterion(outputs, y_train.view(-1, 1))
loss.backward()
optimizer.step()
# 计算并记录训练集和测试集的损失
train_losses.append(loss.item())
with torch.no_grad():
test_outputs = model(X_test)
test_loss = criterion(test_outputs, y_test.view(-1, 1))
test_losses.append(test_loss.item())
# 保存模型
torch.save(model.state_dict(), 'credit_risk_model.pth')
# 加载模型
loaded_model = CreditRiskClassifier()
loaded_model.load_state_dict(torch.load('credit_risk_model.pth'))
loaded_model.eval()
# 在测试集上评估模型
with torch.no_grad():
y_pred = loaded_model(X_test)
y_pred = (y_pred >= 0.5).float()
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
print(f'Accuracy: {accuracy}')
print(f'Classification Report:\n{report}')
# 可视化训练和测试损失
plt.figure(figsize=(10, 5))
plt.plot(range(epochs), train_losses, label='Train Loss', color='blue')
plt.plot(range(epochs), test_losses, label='Test Loss', color='red')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.title('Training and Test Loss Over Epochs')
plt.show()上述代码的实现流程如下:
- 创建了一个虚构的数据集,包含了1000个借款人的特征和标签(违约或非违约)。然后对数据进行标准化处理,以确保特征具有相同的尺度。
- 定义了一个简单的前馈神经网络模型,包括一个输入层、一个隐藏层和一个输出层。然后使用Sigmoid激活函数进行二分类。
- 开始训练模型,首先初始化了模型、损失函数(二进制交叉熵损失)和优化器(Adam)。然后使用训练数据对模型进行了训练,通过反向传播和梯度下降来最小化损失函数。
- 将模型的状态字典保存到名为'credit_risk_model.pth'的文件中。通过加载状态字典,可以重新加载已训练的模型。
- 模型评估:在测试数据集上评估了模型的性能,计算了准确度和生成了分类报告,以了解模型的精度和召回率等性能指标。
- 损失可视化:使用Matplotlib绘制了训练和测试损失的曲线图,以帮助可视化模型的训练进展。
执行后会输出下面的内容:
Accuracy: 0.995
Classification Report:
precision recall f1-score support
0.0 0.99 1.00 1.00 104
1.0 1.00 0.99 0.99 96
accuracy 0.99 200
macro avg 1.00 0.99 0.99 200
weighted avg 1.00 0.99 0.99 200对上述输出结果的具体说明如下:
(1)输出的准确度(Accuracy)为0.995,这表示模型在测试数据集上的预测准确率非常高,达到了99.5%。这意味着模型成功地学习并预测了大多数借款人的信用风险。
(2)Classification Report 提供了更详细的性能指标,包括精确度(Precision)、召回率(Recall)和F1分数(F1-score)。这些指标提供了有关模型在不同类别(违约和非违约)上的性能的信息。
(3)对于类别0(非违约):
- 精确度为0.99,表示预测为非违约的大多数情况下是正确的。
- 召回率为1.00,表示在实际非违约案例中,模型成功地捕捉到了所有案例。
- F1分数为1.00,是精确度和召回率的调和平均值。
(4)对于类别1(违约):
- 精确度为1.00,表示预测为违约的情况下几乎都是正确的。
- 召回率为0.99,表示在实际违约案例中,模型成功地捕捉到了大多数案例。
- F1分数为0.99,是精确度和召回率的调和平均值。
综合来看,模型在两个类别上表现都非常出色,F1分数也接近1,说明模型在信用风险评估任务上的性能非常好。
另外,在代码的最后部分,使用Matplotlib库绘制了一个损失曲线图,该图显示了训练过程中训练损失和测试损失的变化情况。如图7-1所示。这是一个折线图,它的x轴表示训练的轮数(epochs),y轴表示损失值。具体来说,这张图展示了以下信息:
- 蓝色曲线代表训练损失(Train Loss),显示了模型在每个训练轮次中的损失值。
- 红色曲线代表测试损失(Test Loss),显示了模型在每个训练轮次后,在测试数据集上的损失值。
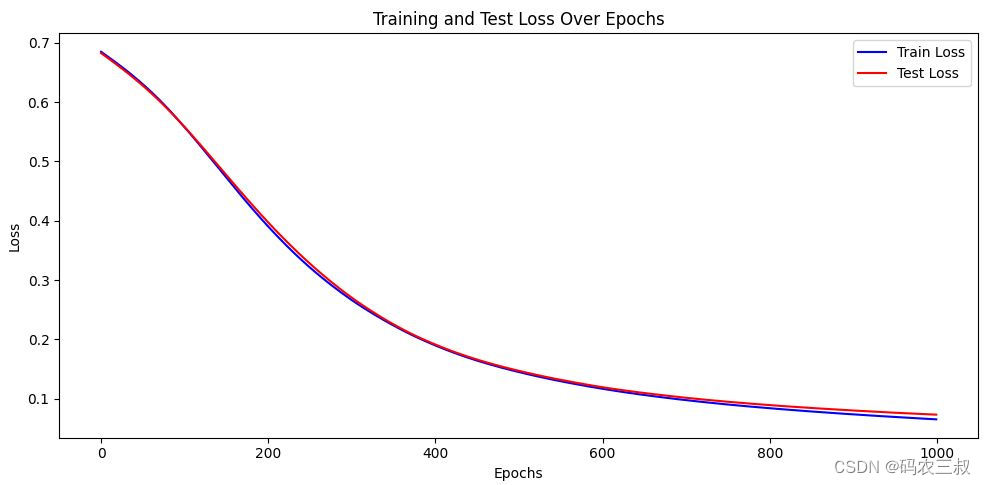
图7-1 模型的损失曲线图
7.2.3 风险模型的解释性与可解释性
风险模型的解释性(interpretability)和可解释性(explainability)是指模型的输出和决策是否能够被清晰、直观地理解和解释的程度。这两个概念在金融领域,特别是在信用风险评估中非常重要。
1. 解释性(Interpretability)
解释性指的是模型的输出和决策是否容易被人类理解。具有高解释性的模型通常具有以下特征:
- 直观性:模型的工作原理和决策过程应该易于理解,不涉及复杂的数学或统计概念。
- 可视化:模型的关键特征、权重和重要性应该能够通过可视化工具直观地展示出来,以便用户能够看到哪些因素影响了模型的决策。
- 简单性:具有较低复杂性的模型通常更容易解释。例如,逻辑回归和决策树等模型通常比神经网络具有更高的解释性。
高解释性的模型对于金融机构和监管机构来说通常更受欢迎,因为它们能够提供透明和可理解的决策过程,有助于满足法规和监管要求。
2. 可解释性(Explainability)
可解释性强调的是模型的决策是否能够被解释并解释给借款人或相关利益相关者。具有高可解释性的模型通常具有以下特征:
- 因果关系:模型的决策应该能够清楚地解释为什么某个决策被做出,即因果关系应该可追踪。
- 特征重要性:模型应该能够明确指出哪些特征对于决策的影响最大,以帮助借款人理解他们的信用申请被接受或拒绝的原因。
- 人类友好的解释:模型的解释应该以人类可理解的方式呈现,而不是仅仅是数学公式或黑盒子的输出。
在金融领域,可解释性非常重要,因为借款人需要了解他们的信用申请被接受或拒绝的原因,以及如何改善他们的信用状况。此外,监管机构也要求金融机构能够解释他们的信用决策过程,以确保公平和合规。
在实际应用中,选择模型的解释性和可解释性取决于任务需求和模型的复杂性。有时,为了获得更高的准确性,可能需要使用更复杂的模型,但同时需要采取措施来提高解释性和可解释性,例如使用解释性的特征重要性分析工具或生成决策解释报告。请看下面的实例,展示了风险模型的解释性和可解释性的用法,以及如何提高模型的可解释性。假设我们正在建立一个信用评估模型,用于判断借款人是否具有违约的风险。
实例7-2:使用逻辑回归模型预测借款人是否具有违约风险(源码路径:daima/7/luo.py)
本实例将使用逻辑回归作为模型,并使用一个虚拟的数据集。实例文件luo.py的具体实现代码如下所示。
# 创建虚拟数据集
np.random.seed(0)
data = pd.DataFrame({
'年龄': np.random.randint(20, 60, 8000),
'收入': np.random.randint(20000, 80000, 8000),
'信用分数': np.random.randint(300, 850, 8000),
'负债率': np.random.uniform(0, 1, 8000),
'是否违约': np.random.randint(0, 2, 8000)
})
# 划分数据集
X = data.drop('是否违约', axis=1)
y = data['是否违约']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练逻辑回归模型
model = LogisticRegression()
model.fit(X_train, y_train)
# 评估模型
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
print(f'Accuracy: {accuracy}')
print(f'Classification Report:\n{report}')在这个例子中,使用逻辑回归模型来预测借款人是否具有违约的风险。现在让我们重点看解释性和可解释性:
- 解释性:逻辑回归是一种高度解释性的模型。模型的输出是基于线性组合特征的结果,可以理解为对不同特征的权重加权和。例如,信用分数可能对决策的影响比年龄或负债率更重要。
- 可解释性:为了提高模型的可解释性,我们可以使用特征重要性分析。逻辑回归的特征权重可以用来解释哪些特征对于模型的决策最重要。例如,如果发现信用分数对决策的影响最大,那么可以告诉借款人提高信用分数可能会改善他们的信用风险。
执行后会输出:
Accuracy: 0.490625
Classification Report:
precision recall f1-score support
0 0.48 0.83 0.61 771
1 0.52 0.18 0.27 829
accuracy 0.49 1600
macro avg 0.50 0.50 0.44 1600
weighted avg 0.50 0.49 0.43 1600在实际应用中,还可以使用可视化工具来呈现模型的解释结果,例如绘制特征重要性的柱状图或展示每个特征对决策的影响。总之,逻辑回归作为一个简单且解释性强的模型,可以用于信用风险评估,并且通过特征重要性分析可以提高模型的可解释性,让借款人更好地理解信用评估的依据。