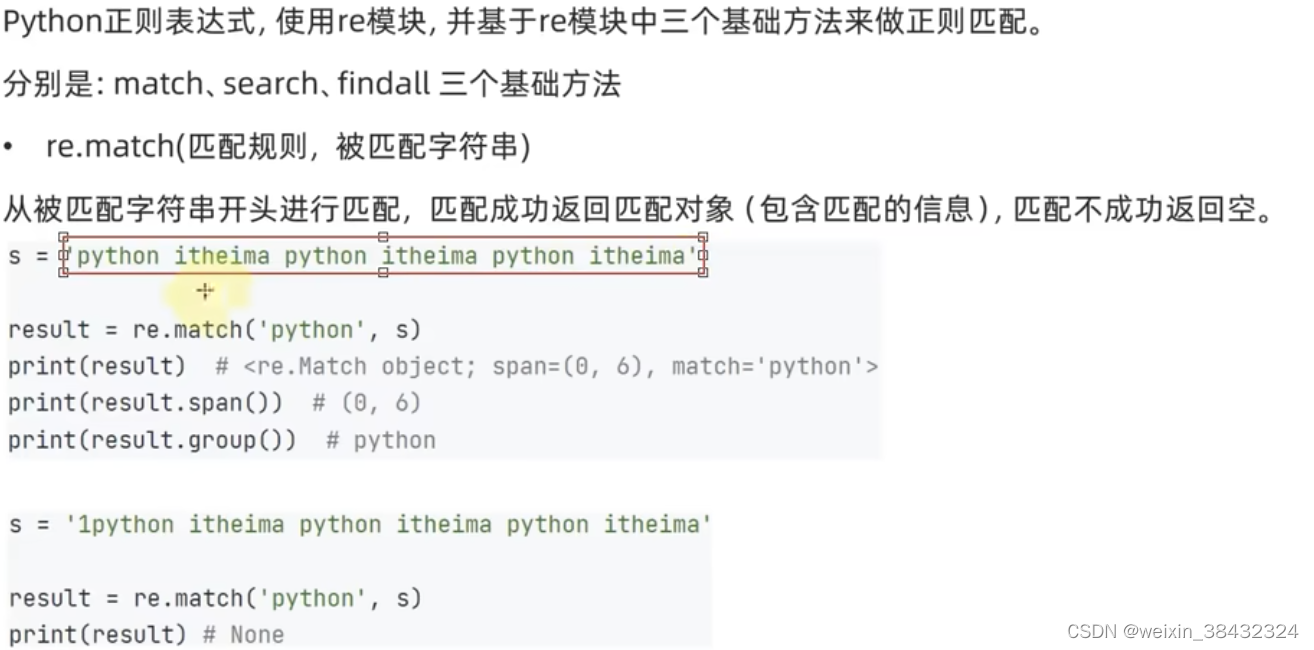
导语:逐步深入介绍Python正则表达式,从最基础的概念到更高级的应用。每个部分都建议包含实际的代码示例和解释,以帮助大家更好地理解和掌握。
目录
正则表达式基础
什么是正则表达式
定义
正则表达式(Regular Expression,简称Regex)是一种强大的文本处理工具,它使用单个字符串来描述和匹配一系列符合某个句法规则的字符串。它被广泛用于字符串搜索、替换以及复杂的数据验证等场景。
历史
正则表达式起源于20世纪50年代的神经生物学研究,后来被引入到计算机科学中用于进行模式匹配。
用途
正则表达式可以用来检查一个字符串是否符合某种格式(如邮箱、电话号码)、提取字符串中的某部分(如从日志文件中提取日期和时间)、替换文本中的字符串等。
Python中的正则表达式
re模块
Python通过内置的re模块提供对正则表达式的支持。
要使用正则表达式,首先需要导入此模块:
import re基本函数
re.match():尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回None。re.search():扫描整个字符串并返回第一个成功的匹配。re.findall():找到字符串中所有匹配的子串,并返回一个列表。re.sub():用于替换字符串中的匹配项。
简单的匹配操作
import re
text = "Python is fun"
# 使用match()检查字符串是否以'Python'开头
if re.match("Python", text):
print("Match found at the beginning of the text")
else:
print("Match not found")
# 使用search()在整个字符串中搜索'fun'
if re.search("fun", text):
print("Match found anywhere in the text")
else:
print("Match not found")
# 使用findall()找到所有'is'的匹配项
print("Occurrences of 'is':", len(re.findall("is", text)))
# 使用sub()替换文本
replaced_text = re.sub("fun", "powerful", text)
print("Replaced text:", replaced_text)
正则符号对应含义大全
| 符号 | 含义 |
|---|---|
. |
匹配除换行符之外的任意单个字符 |
^ |
匹配输入字符串的开始位置 |
$ |
匹配输入字符串的结束位置 |
* |
匹配前面的子表达式零次或多次 |
+ |
匹配前面的子表达式一次或多次 |
? |
匹配前面的子表达式零次或一次 |
{n} |
精确匹配n次 |
{n,} |
匹配n次或更多次 |
{n,m} |
匹配n到m次 |
\ |
转义特殊字符 |
[ ] |
表示一个字符集合。匹配所包含的任意一个字符 |
[^ ] |
否定的字符集合。匹配未包含的任意字符 |
| |
匹配|前或后的表达式 |
( ) |
标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用 |
\d |
匹配一个数字字符。等价于[0-9] |
\D |
匹配一个非数字字符。等价于[^0-9] |
\w |
匹配包括下划线的任何单词字符。等价于[A-Za-z0-9_] |
\W |
匹配任何非单词字符。等价于[^A-Za-z0-9_] |
\s |
匹配任何空白字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v] |
\S |
匹配任何非空白字符。等价于[^ \f\n\r\t\v] |
正则表达式语法
在了解了正则表达式的基本用途和Python中的
re模块之后,现在让我们深入探讨正则表达式的具体语法和构建块。这部分将详细解释各种特殊字符、量词、字符类等的用法。
字符匹配
- 字面字符 vs 特殊字符:正则表达式中直接匹配的字面字符和有特殊含义的特殊字符。
- 转义字符:使用
\来转义特殊字符的情况,使其表示字面意义上的符号。
import re
# 使用字面字符匹配
print(re.findall('cat', 'The cat is on the mat.'))
# 使用特殊字符.匹配任意字符
print(re.findall('c.t', 'The cat is on the cut.'))
# 使用转义字符匹配.
print(re.findall('c\.t', 'The c.t is on the cut.'))
字符集
- 使用[]定义字符集:使用中括号定义字符集,以及通过字符集匹配一组字符中的任意一个。
- 特殊字符集:
\d、\w、\s及其大写形式的含义和用法。
# 匹配任意数字或字母
print(re.findall('[a-zA-Z0-9]', 'Python 3.8'))
# 使用特殊字符集
print(re.findall('\d+', 'The meeting is on 10th of June 2021.'))
量词
- 介绍量词:
*、+、?、{n}、{n,}、{n,m}的用法和它们在模式匹配中的作用。 - 贪婪与非贪婪匹配:量词的贪婪模式和非贪婪模式的区别,以及如何使用
?来实现非贪婪匹配。
# 贪婪匹配
print(re.findall('a{2,4}', 'aaaaaa'))
# 非贪婪匹配
print(re.findall('a{2,4}?', 'aaaaaa'))
分组和引用
- 分组的概念:使用
()进行分组的概念,以及利用分组来提取或引用特定部分的匹配。 - 后向引用:后向引用的概念,以及在同一正则表达式中引用前面的分组。
# 使用分组提取数据
match = re.search('(\d{4})-(\d{2})-(\d{2})', 'Today is 2021-06-10.')
year, month, day = match.groups()
print(f'Year: {year}, Month: {month}, Day: {day}')
# 使用后向引用匹配重复单词
print(re.findall(r'(\b\w+)\s+\1', 'Paris in the the spring'))
re函数使用详解
在Python中,
re模块提供了一系列强大的函数用于正则表达式的匹配和处理。以下是一些最常用的re函数,以及每个函数的详细解释和代码示例。
re.match()
- 用途: 从字符串的起始位置匹配一个模式。如果不是起始位置匹配成功的话,
match()就返回None。
import re
text = "Hello World"
match = re.match(r"Hello", text)
if match:
print("Match found:", match.group())
else:
print("No match")
re.search()
- 用途: 扫描整个字符串并返回第一个成功的匹配。
import re
text = "Hello World"
match = re.search(r"World", text)
if match:
print("Match found:", match.group())
else:
print("No match")
re.findall()
- 用途: 找到字符串中所有匹配的子串,并返回一个列表。
import re
text = "cat bat sat fat"
all_matches = re.findall(r"[cbf]at", text)
print("All matches:", all_matches)
re.finditer()
- 用途: 和
findall()类似,但返回的是一个迭代器,而不是列表。每个迭代器项目都是一个匹配的对象。
import re
text = "cat bat sat fat"
for match in re.finditer(r"[cbf]at", text):
print("Match at index:", match.start(), match.group())
re.sub()
- 用途: 替换字符串中的匹配项。
import re
text = "Hello World"
replaced_text = re.sub(r"World", "Python", text)
print("Replaced Text:", replaced_text)
re.split()
- 用途: 根据正则表达式的匹配项来分割字符串。
import re
text = "Hello, World, Python"
split_text = re.split(r",\s*", text)
print("Split text:", split_text)
re.compile()
- 用途: 编译正则表达式模式,返回一个正则表达式对象,可以用于
match、search等操作,这在你需要重复使用某个正则表达式时非常有用。
import re
pattern = re.compile(r"\d+")
result = pattern.findall("12 drummers drumming, 11 pipers piping, 10 lords a-leaping")
print("Numbers found:", result)
结语
Python正则表达式提供强大的文本处理能力,涵盖字符匹配、量词、分组等核心语法。通过re模块,用户能够执行复杂的搜索、验证和文本操作,但还需要大家反复练习,熟能生巧。
----------------------
觉得不错 点个赞吧~





























![[渗透测试学习] Manager - HackTheBox](https://img-blog.csdnimg.cn/direct/8381fa864b1342909749e6057783f123.png)