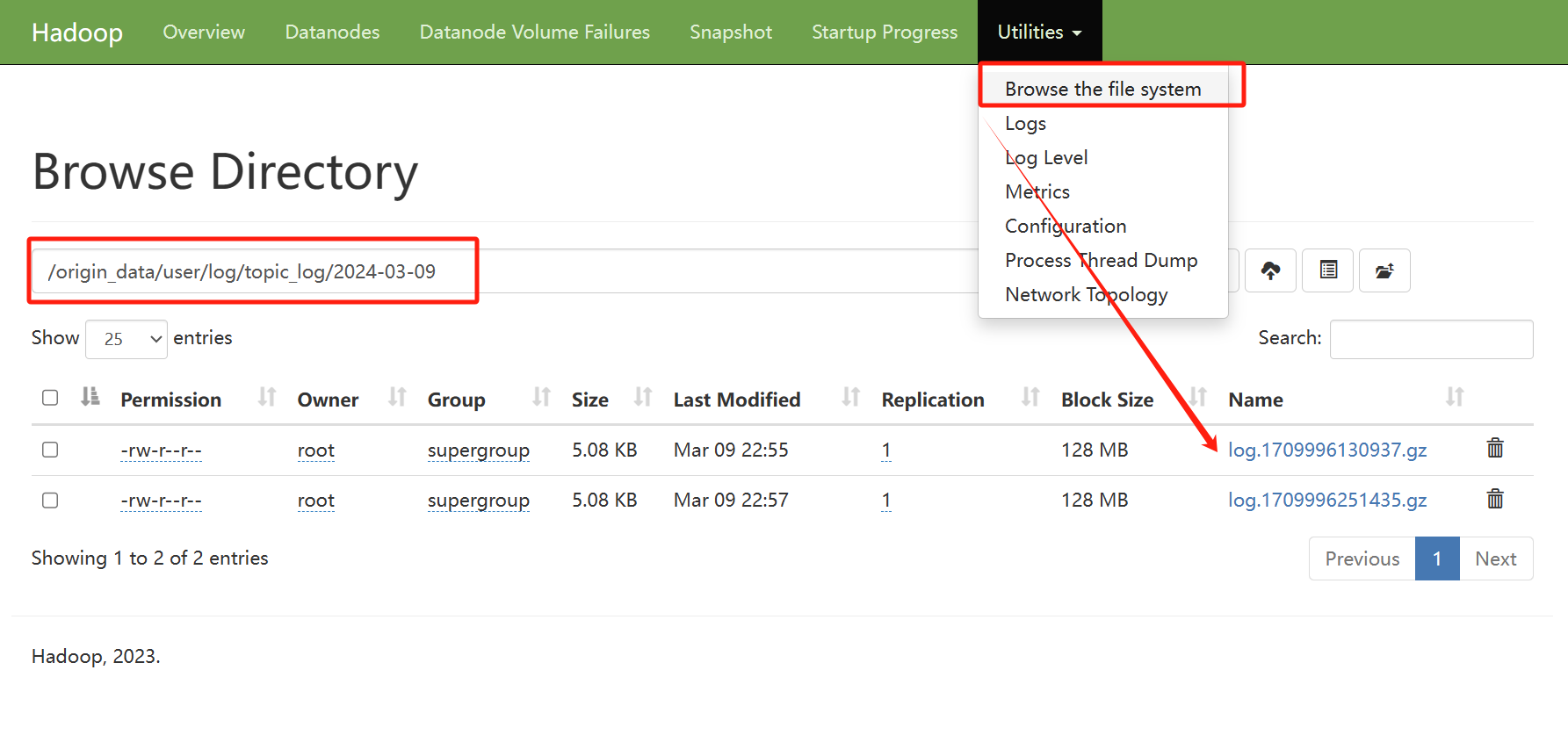
1 日志服务器上配置Flume,采集本地日志文件,发送到172.19.115.96 的flume上进行聚合,如日志服务器有多组,则在多台服务器上配置相同的配置
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
#通配符是以.*为标识的,如采集所有文件则.*,此处表示采集.log结尾的文件
a1.sources.r1.filegroups.f1 = /home/admin/app/api/logs/.*log
#a1.sources.r1.filegroups = f1 f2
#a1.sources.r1.filegroups.f2 = /usr/local/flume-1.9.0/files2/.*
a1.sources.r1.positionFile = /usr/local/flume-1.9.0/taildir_position.json
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 172.19.115.96
a1.sinks.k1.port = 4141
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c12 hdfs服务器上配置flume
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.bind = 172.19.115.96
a1.sources.r1.port = 4141
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://localhost:8020/test/%Y%m%d
#生成的hdfs文件名的前缀
a1.sinks.k1.hdfs.filePrefix = logs-
#指定滚动时间,默认是30秒,设置为0表示禁用该策略 生产调整为3600
a1.sinks.k1.hdfs.rollInterval = 10
#指定滚动大小,设置为0表示禁用该策略,128M
a1.sinks.k1.hdfs.rollSize = 134217700
#指定滚动条数
a1.sinks.k1.hdfs.rollCount = 0
#a1.sinks.k1.hdfs.batchSize = 100
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
3 在hdfs服务器上启动HDFS
start-dfs.sh4 先启动hdfs服务器上的flume
bin/flume-ng agent -c conf/ -f job/avro-flume-hdfs.conf -n a1
后台运行
nohup ./bin/flume-ng agent -c conf/ -f job/avro-flume-hdfs.conf -n a1 &5 再启动日志服务器上的flume
bin/flume-ng agent -c conf/ -f job/file-flume-avro.conf -n a1后台运行
nohup ./bin/flume-ng agent -c conf/ -f job/file-flume-avro.conf -n a1 &