大家好,我是博哥爱运维。
OK,到目前为止,我们的服务顺利容器化并上了K8s,同时也能通过外部网络进行请求访问,相关的服务数据也能进行持久化存储了,那么接下来很关键的事情,就是怎么去收集服务产生的日志进行数据分析及问题排查,下面会以生产中的经验来详细讲解这些内容。
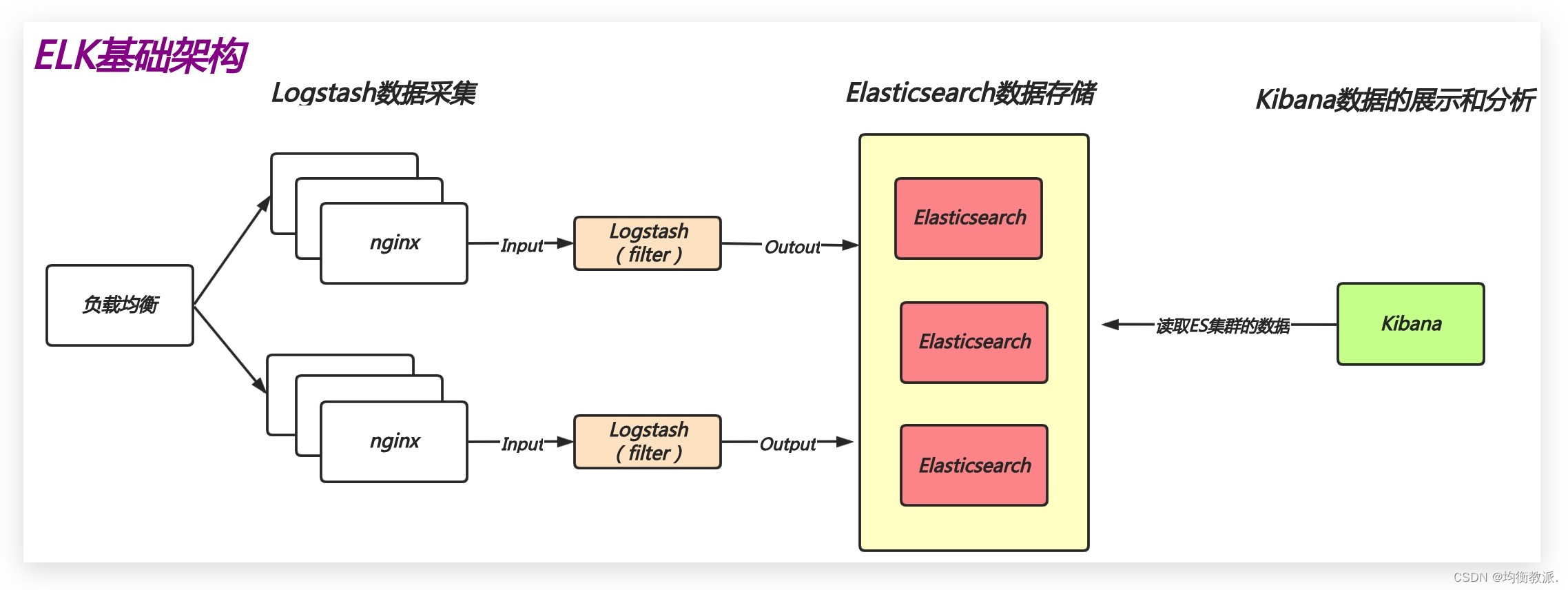
K8S日志收集体系
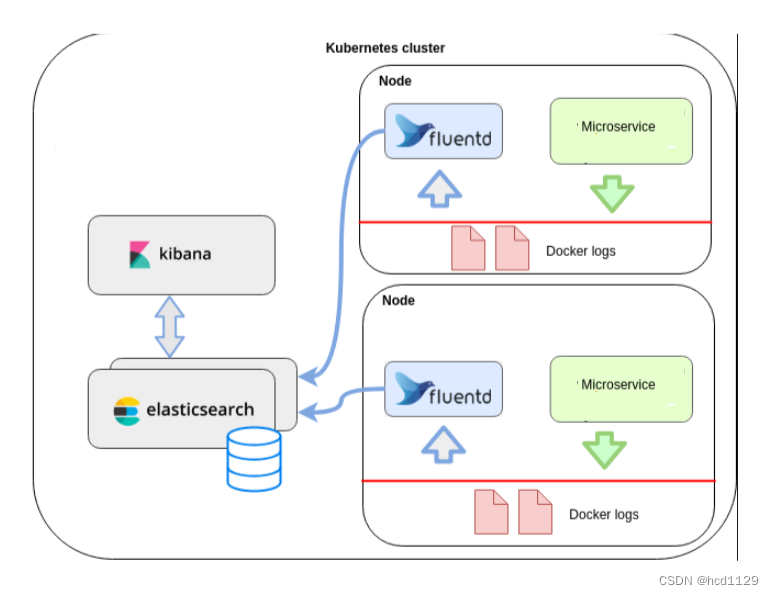
现在市面上大多数课程都是以EFK来作来K8s项目的日志解决方案,它包括三个组件:Elasticsearch, Fluentd(filebeat), Kibana;Elasticsearch 是日志存储和日志搜索引擎,Fluentd 负责把k8s集群的日志发送给 Elasticsearch, Kibana 则是可视化界面查看和检索存储在 Elasticsearch 的数据。
但根据生产中实际使用情况来看,它有以下弊端:
1、日志收集笼统
EFK是在每个kubernetes的NODE节点以daemonset的形式启动一个fluentd的pod,来收集NODE节点上的日志,如容器日志(/var/log/containers/*.log),但里面无法作细分,想要的和不想要的都收集进来了,带来的后面就是磁盘IO压力会比较大,日志过滤麻烦。
2、无法收集对应POD里面的业务日志
上面第1点只能收集pod的stdout日志,但是pod内如有需要收集的业务日志,像pod内的/tmp/datalog/*.log,那EFK是无能为力的,只能是在pod内启动多个容器(filebeat)去收集容器内日志,但这又会带来的是pod多容器性能的损耗,这个接下来会详细讲到。
3、fluentd的采集速率性能较低,只能不到filebeat的1/10的性能。
基于此,我通过调研发现了阿里开源的智能容器采集工具 Log-Pilot,github地址:https://github.com/AliyunContainerService/log-pilot
下面以sidecar 模式和log-pilot这两种方式的日志收集形式做个详细对比说明:
第一种模式是 sidecar 模式,这种需要我们在每个 Pod 中都附带一个 logging 容器来进行本 Pod 内部容器的日志采集,一般采用共享卷的方式,但是对于这一种模式来说,很明显的一个问题就是占用的资源比较多,尤其是在集群规模比较大的情况下,或者说单个节点上容器特别多的情况下,它会占用过多的系统资源,同时也对日志存储后端占用过多的连接数。当我们的集群规模越大,这种部署模式引发的潜在问题就越大。

另一种模式是 Node 模式,这种模式是我们在每个 Node 节点上仅需布署一个 logging 容器来进行本 Node 所有容器的日志采集。这样跟前面的模式相比最明显的优势就是占用资源比较少,同样在集群规模比较大的情况下表现出的优势越明显,同时这也是社区推荐的一种模式。

经过多方面测试,log-pilot对现有业务pod侵入性很小,只需要在原有pod的内传入几行env环境变量,即可对此pod相关的日志进行收集,已经测试了后端接收的工具有logstash、elasticsearch、kafka、redis、file,均OK,下面开始部署整个日志收集环境。
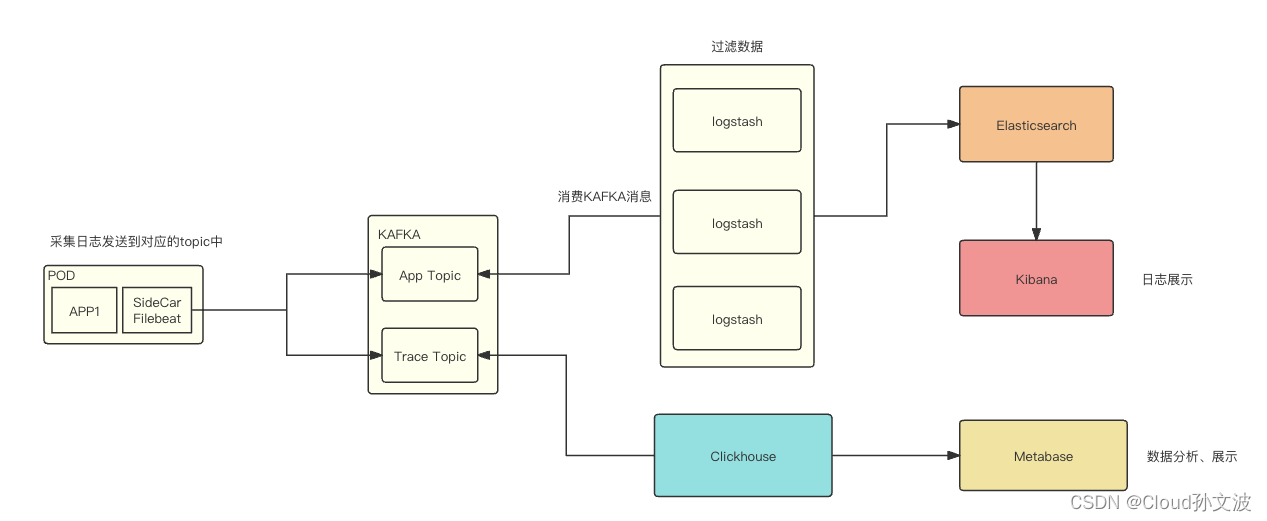
我们这里用一个tomcat服务来模拟业务服务,用log-pilot分别收集它的stdout以及容器内的业务数据日志文件到指定后端存储,2023课程会以真实生产的一个日志传输架构来做测试:
模拟业务服务 日志收集 日志存储 消费日志 消费目的服务
tomcat ---> log-pilot ---> kafka ---> filebeat ---> elasticsearch ---> kibana
1、部署测试用的kafka
Apache Kafka是一种流行的分布式消息传递系统,设计用于处理大规模的数据流。它在日志传输和流数据处理领域尤为重要。以下是Kafka的一些关键特性,以及它们如何适用于日志传输体系:
- 高吞吐量和可伸缩性:
- Kafka能够处理高速数据流,支持大量数据的读写操作。它通过分区(partitions)和分布式架构来实现高吞吐量和水平扩展。
- 在日志传输中,这意味着Kafka可以高效地收集和分发大量的日志数据,满足大型系统的需求。
- 持久性和可靠性:
- Kafka将数据存储在磁盘上,并支持数据的复制,确保信息不会因为单点故障而丢失。
- 对于日志管理来说,这确保了日志数据的安全和完整性,即使在系统故障的情况下也能保持日志的可用性。
- 实时处理:
- Kafka支持实时数据流处理,使得数据在产生后立即可用。
- 在日志系统中,这允许实时监控和分析日志数据,有助于快速故障排除和系统性能监控。
- 分布式架构:
- Kafka的分布式特性意味着它可以跨多个服务器和数据中心运行,提高了容错能力和系统的稳定性。
- 在分布式日志系统中,这有助于管理跨地域或多个服务的日志数据,提供更好的可扩展性和冗余。
- 灵活的消费模型:
- Kafka支持发布-订阅和队列两种消息模式,使消费者能够灵活地读取数据。
- 日志传输中,这使得不同的系统和应用可以根据需要订阅特定类型的日志数据。
- 低延迟:
- Kafka设计用于低延迟消息传递,这对于需要快速响应的日志分析和监控系统至关重要。
结合日志传输体系,Kafka的这些特性使其成为一个理想的中央日志聚合点。它不仅能够高效地收集来自不同源的日志数据,还能将这些数据实时分发给各种日志分析和监控工具,支持大数据分析、实时监控和快速故障检测。
在Apache Kafka中,几个核心概念包括主题(Topic)、分区(Partition)和消费组(Consumer Group)。这些概念是Kafka高效消息处理和分布式数据流管理的基石。下面是对这些概念的简要介绍:
- 主题 (Topic):
- Kafka中的主题是消息的分类或者说是一个消息通道。生产者(Producers)将消息发送到特定的主题,而消费者(Consumers)从主题中读取消息。
- 主题可以被视为消息的逻辑分类。每个主题可以有多个生产者向其发送数据,也可以有多个消费者从中读取数据。
- 分区 (Partition):
- 为了提高可伸缩性和并行处理能力,Kafka中的每个主题可以被分割成多个分区。
- 分区允许主题中的消息在多个服务器(Broker)之间分布,从而实现数据的负载均衡和并行处理。每个分区都是有序且不变的消息序列。
- 每条消息在被添加到分区时都会被赋予一个唯一的序列号,称为偏移量(Offset)。
- 生产者在发送消息时可以指定消息应该发送到哪个分区,或者让Kafka根据消息的Key自动选择分区。
- 消费组 (Consumer Group):
- 消费者可以单独工作,也可以作为消费组的一部分来消费消息。消费组允许一组消费者共同订阅一个或多个主题,并协作消费消息。
- 在一个消费组内,每个分区的消息只会被组内的一个消费者读取。这保证了消息只被消费一次,同时实现了负载均衡。
- 如果一个消费组有多个消费者,Kafka会自动将主题的分区分配给不同的消费者,以实现并行处理。
- 消费组的概念使得Kafka可以灵活地支持多种消费模式,包括发布-订阅和点对点。
结合日志传输体系,这些特性使Kafka能够有效地处理来自多个源的大量日志数据。主题和分区支持高吞吐量的数据写入和读取,而消费组则允许多个消费者协作,确保日志数据的高效处理和分析。通过这种方式,Kafka可以作为一个强大的中央日志聚合系统,支持复杂的日志处理和分析需求。
准备一个测试用的kafka服务
# 部署前准备 10.0.1.201(这台作为二进制k8s集群的部署节点,上面会是装好docker服务的状态)
# 准备好 docker-compose 命令
ln -svf /etc/kubeasz/bin/docker-compose /usr/bin/docker-compose
# 准备好文件 docker-compose.yml:
#——------------------------------
version: '2'
services:
zookeeper:
image: bogeit/zookeeper
ports:
- "2181:2181"
restart: unless-stopped
kafka:
image: bogeit/kafka:2.8.1
ports:
- "9092:9092"
environment:
DOCKER_API_VERSION: 1.22
KAFKA_ADVERTISED_HOST_NAME: 10.0.1.201
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- /mnt/kafka:/kafka
restart: unless-stopped
#——------------------------------
# 1. docker-compose setup:
# docker-compose up -d
Recreating kafka-docker-compose_kafka_1 ... done
Starting kafka-docker-compose_zookeeper_1 ... done
# 2. result look:
# docker-compose ps
Name Command State Ports
--------------------------------------------------------------------------------------------------------------------
kafka-docker-compose_kafka_1 start-kafka.sh Up 0.0.0.0:9092->9092/tcp
kafka-docker-compose_zookeeper_1 /bin/sh -c /usr/sbin/sshd ... Up 0.0.0.0:2181->2181/tcp, 22/tcp,
2888/tcp, 3888/tcp
# 3. run test-docker
bash-4.4# docker run --rm -v /var/run/docker.sock:/var/run/docker.sock -e HOST_IP=10.0.1.201 -e ZK=10.0.1.201:2181 -i -t wurstmeister/kafka /bin/bash
# 4. list topic
bash-4.4# kafka-topics.sh --zookeeper 10.0.1.201:2181 --list
tomcat-access
tomcat-syslog
# 5. consumer topic data:
bash-4.4# kafka-console-consumer.sh --bootstrap-server 10.0.1.201:9092 --topic tomcat-access --from-beginning
2、部署日志收集服务 log-pilot (适配容器运行时 Containerd)
# 先创建一个namespace
kubectl create ns ns-elastic
# 部署yaml
---
apiVersion: v1
kind: ConfigMap
metadata:
name: log-pilot5-configuration
namespace: ns-elastic
data:
logging_output: "kafka"
kafka_brokers: "10.0.1.201:9092"
kafka_version: "0.10.0"
kafka_topics: "tomcat-syslog,tomcat-access"
#kafka_username: "user"
#kafka_password: "bogeit"
---
apiVersion: v1
data:
filebeat.tpl: |+
{
{
range .configList}}
- type: log
enabled: true
paths:
- {
{
.HostDir }}/{
{
.File }}
scan_frequency: 5s
fields_under_root: true
{
{
if eq .Format "json"}}
json.keys_under_root: true
{
{
end}}
fields:
{
{
range $key, $value := .Tags}}
{
{
$key }}: {
{
$value }}
{
{
end}}
{
{
range $key, $value := $.container}}
{
{
$key }}: {
{
$value }}
{
{
end}}
tail_files: false
close_inactive: 2h
close_eof: false
close_removed: true
clean_removed: true
close_renamed: false
{
{
end}}
kind: ConfigMap
metadata:
name: filebeat5-tpl
namespace: ns-elastic
---
apiVersion: v1
data:
config.filebeat: |+
#!/bin/sh
set -e
FILEBEAT_CONFIG=/etc/filebeat/filebeat.yml
if [ -f "$FILEBEAT_CONFIG" ]; then
echo "$FILEBEAT_CONFIG has been existed"
exit
fi
mkdir -p /etc/filebeat/prospectors.d
assert_not_empty() {
arg=$1
shift
if [ -z "$arg" ]; then
echo "$@"
exit 1
fi
}
cd $(dirname $0)
base() {
cat >> $FILEBEAT_CONFIG << EOF
path.config: /etc/filebeat
path.logs: /var/log/filebeat
path.data: /var/lib/filebeat/data
filebeat.registry_file: /var/lib/filebeat/registry
filebeat.shutdown_timeout: ${
FILEBEAT_SHUTDOWN_TIMEOUT:-0}
logging.level: ${
FILEBEAT_LOG_LEVEL:-info}
logging.metrics.enabled: ${
FILEBEAT_METRICS_ENABLED:-false}
logging.files.rotateeverybytes: ${
FILEBEAT_LOG_MAX_SIZE:-104857600}
logging.files.keepfiles: ${
FILEBEAT_LOG_MAX_FILE:-10}
logging.files.permissions: ${
FILEBEAT_LOG_PERMISSION:-0600}
${
FILEBEAT_MAX_PROCS:+max_procs: ${
FILEBEAT_MAX_PROCS}}
setup.template.name: "${FILEBEAT_INDEX:-filebeat}"
setup.template.pattern: "${FILEBEAT_INDEX:-filebeat}-*"
filebeat.config:
prospectors:
enabled: true
path: \${
path.config}/prospectors.d/*.yml
reload.enabled: true
reload.period: 10s
EOF
}
es() {
if [ -f "/run/secrets/es_credential" ]; then
ELASTICSEARCH_USER=$(cat /run/secrets/es_credential | awk -F":" '{
print $1 }')
ELASTICSEARCH_PASSWORD=$(cat /run/secrets/es_credential | awk -F":" '{
print $2 }')
fi
if [ -n "$ELASTICSEARCH_HOSTS" ]; then
ELASTICSEARCH_HOSTS=$(echo $ELASTICSEARCH_HOSTS|awk -F, '{
for(i=1;i<=NF;i++){
printf "\"%s\",", $i}}')
ELASTICSEARCH_HOSTS=${
ELASTICSEARCH_HOSTS%,}
else
assert_not_empty "$ELASTICSEARCH_HOST" "ELASTICSEARCH_HOST required"
assert_not_empty "$ELASTICSEARCH_PORT" "ELASTICSEARCH_PORT required"
ELASTICSEARCH_HOSTS="\"$ELASTICSEARCH_HOST:$ELASTICSEARCH_PORT\""
fi
cat >> $FILEBEAT_CONFIG << EOF
$(base)
output.elasticsearch:
hosts: [$ELASTICSEARCH_HOSTS]
index: ${
ELASTICSEARCH_INDEX:-filebeat}-%{
+yyyy.MM.dd}
${
ELASTICSEARCH_SCHEME:+protocol: ${
ELASTICSEARCH_SCHEME}}
${
ELASTICSEARCH_USER:+username: ${
ELASTICSEARCH_USER}}
${
ELASTICSEARCH_PASSWORD:+password: ${
ELASTICSEARCH_PASSWORD}}
${
ELASTICSEARCH_WORKER:+worker: ${
ELASTICSEARCH_WORKER}}
${
ELASTICSEARCH_PATH:+path: ${
ELASTICSEARCH_PATH}}
${
ELASTICSEARCH_BULK_MAX_SIZE:+bulk_max_size: ${
ELASTICSEARCH_BULK_MAX_SIZE}}
EOF
}
default() {
echo "use default output"
cat >> $FILEBEAT_CONFIG << EOF
$(base)
output.console:
pretty: ${
CONSOLE_PRETTY:-false}
EOF
}
file() {
assert_not_empty "$FILE_PATH" "FILE_PATH required"
cat >> $FILEBEAT_CONFIG << EOF
$(base)
output.file:
path: $FILE_PATH
${
FILE_NAME:+filename: ${
FILE_NAME}}
${
FILE_ROTATE_SIZE:+rotate_every_kb: ${
FILE_ROTATE_SIZE}}
${
FILE_NUMBER_OF_FILES:+number_of_files: ${
FILE_NUMBER_OF_FILES}}
${
FILE_PERMISSIONS:+permissions: ${
FILE_PERMISSIONS}}
EOF
}
logstash() {
assert_not_empty "$LOGSTASH_HOST" "LOGSTASH_HOST required"
assert_not_empty "$LOGSTASH_PORT" "LOGSTASH_PORT required"
cat >> $FILEBEAT_CONFIG << EOF
$(base)
output.logstash:
hosts: ["$LOGSTASH_HOST:$LOGSTASH_PORT"]
index: ${
FILEBEAT_INDEX:-filebeat}-%{
+yyyy.MM.dd}
${
LOGSTASH_WORKER:+worker: ${
LOGSTASH_WORKER}}
${
LOGSTASH_LOADBALANCE:+loadbalance: ${
LOGSTASH_LOADBALANCE}}
${
LOGSTASH_BULK_MAX_SIZE:+bulk_max_size: ${
LOGSTASH_BULK_MAX_SIZE}}
${
LOGSTASH_SLOW_START:+slow_start: ${
LOGSTASH_SLOW_START}}
EOF
}
redis() {
assert_not_empty "$REDIS_HOST" "REDIS_HOST required"
assert_not_empty "$REDIS_PORT" "REDIS_PORT required"
cat >> $FILEBEAT_CONFIG << EOF
$(base)
output.redis:
hosts: ["$REDIS_HOST:$REDIS_PORT"]
key: "%{[fields.topic]:filebeat}"
${
REDIS_WORKER:+worker: ${
REDIS_WORKER}}
${
REDIS_PASSWORD:+password: ${
REDIS_PASSWORD}}
${
REDIS_DATATYPE:+datatype: ${
REDIS_DATATYPE}}
${
REDIS_LOADBALANCE:+loadbalance: ${
REDIS_LOADBALANCE}}
${
REDIS_TIMEOUT:+timeout: ${
REDIS_TIMEOUT}}
${
REDIS_BULK_MAX_SIZE:+bulk_max_size: ${
REDIS_BULK_MAX_SIZE}}
EOF
}
kafka() {
assert_not_empty "$KAFKA_BROKERS" "KAFKA_BROKERS required"
KAFKA_BROKERS=$(echo $KAFKA_BROKERS|awk -F, '{
for(i=1;i<=NF;i++){
printf "\"%s\",", $i}}')
KAFKA_BROKERS=${
KAFKA_BROKERS%,}
cat >> $FILEBEAT_CONFIG << EOF
$(base)
output.kafka:
hosts: [$KAFKA_BROKERS]
topic: '%{[topic]}'
codec.format:
string: '%{[message]}'
${
KAFKA_VERSION:+version: ${
KAFKA_VERSION}}
${
KAFKA_USERNAME:+username: ${
KAFKA_USERNAME}}
${
KAFKA_PASSWORD:+password: ${
KAFKA_PASSWORD}}
${
KAFKA_WORKER:+worker: ${
KAFKA_WORKER}}
${
KAFKA_PARTITION_KEY:+key: ${
KAFKA_PARTITION_KEY}}
${
KAFKA_PARTITION:+partition: ${
KAFKA_PARTITION}}
${
KAFKA_CLIENT_ID:+client_id: ${
KAFKA_CLIENT_ID}}
${
KAFKA_METADATA:+metadata: ${
KAFKA_METADATA}}
${
KAFKA_BULK_MAX_SIZE:+bulk_max_size: ${
KAFKA_BULK_MAX_SIZE}}
${
KAFKA_BROKER_TIMEOUT:+broker_timeout: ${
KAFKA_BROKER_TIMEOUT}}
${
KAFKA_CHANNEL_BUFFER_SIZE:+channel_buffer_size: ${
KAFKA_CHANNEL_BUFFER_SIZE}}
${
KAFKA_KEEP_ALIVE:+keep_alive ${
KAFKA_KEEP_ALIVE}}
${
KAFKA_MAX_MESSAGE_BYTES:+max_message_bytes: ${
KAFKA_MAX_MESSAGE_BYTES}}
${
KAFKA_REQUIRE_ACKS:+required_acks: ${
KAFKA_REQUIRE_ACKS}}
EOF
}
count(){
cat >> $FILEBEAT_CONFIG << EOF
$(base)
output.count:
EOF
}
if [ -n "$FILEBEAT_OUTPUT" ]; then
LOGGING_OUTPUT=$FILEBEAT_OUTPUT
fi
case "$LOGGING_OUTPUT" in
elasticsearch)
es;;
logstash)
logstash;;
file)
file;;
redis)
redis;;
kafka)
kafka;;
count)
count;;
*)
default
esac
kind: ConfigMap
metadata:
name: config5.filebeat
namespace: ns-elastic
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: log-pilot5
namespace: ns-elastic
labels:
k8s-app: log-pilot5
spec:
updateStrategy:
type: RollingUpdate
selector:
matchLabels:
k8s-app: log-pilot5
template:
metadata:
labels:
k8s-app: log-pilot5
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
- effect: NoSchedule
key: ToBeDeletedByClusterAutoscaler
operator: Exists
containers:
- name: log-pilot5
image: williamguozi/log-pilot-filebeat:containerd
imagePullPolicy: IfNotPresent
env:
- name: "LOGGING_OUTPUT"
valueFrom:
configMapKeyRef:
name: log-pilot5-configuration
key: logging_output
- name: "KAFKA_BROKERS"
valueFrom:
configMapKeyRef:
name: log-pilot5-configuration
key: kafka_brokers
- name: "KAFKA_VERSION"
valueFrom:
configMapKeyRef:
name: log-pilot5-configuration
key: kafka_version
- name: "KAFKA_USERNAME"
valueFrom:
configMapKeyRef:
name: log-pilot5-configuration
key: kafka_username
- name: "KAFKA_PASSWORD"
valueFrom:
configMapKeyRef:
name: log-pilot5-configuration
key: kafka_password
- name: "NODE_NAME"
valueFrom:
fieldRef:
fieldPath: spec.nodeName
volumeMounts:
- name: sock
mountPath: /var/run/containerd/containerd.sock
- name: logs
mountPath: /var/log/filebeat
- name: state
mountPath: /var/lib/filebeat
- name: root
mountPath: /host
readOnly: true
- name: localtime
mountPath: /etc/localtime
- name: config-volume
mountPath: /etc/filebeat/config
- name: filebeat-tpl
mountPath: /pilot/filebeat.tpl
subPath: filebeat.tpl
- name: config-filebeat
mountPath: /pilot/config.filebeat
subPath: config.filebeat
securityContext:
capabilities:
add:
- SYS_ADMIN
terminationGracePeriodSeconds: 30
volumes:
- name: sock
hostPath:
path: /var/run/containerd/containerd.sock
type: Socket
- name: logs
hostPath:
path: /var/log/filebeat
type: DirectoryOrCreate
- name: state
hostPath:
path: /var/lib/filebeat
type: DirectoryOrCreate
- name: root
hostPath:
path: /
type: Directory
- name: localtime
hostPath:
path: /etc/localtime
type: File
- name: config-volume
configMap:
name: log-pilot5-configuration
items:
- key: kafka_topics
path: kafka_topics
- name: filebeat-tpl
configMap:
name: filebeat5-tpl
- name: config-filebeat
configMap:
name: config5.filebeat
defaultMode: 0777
3、部署测试用的tomcat服务
vim tomcat-test.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: tomcat
name: tomcat
spec:
replicas: 1
selector:
matchLabels:
app: tomcat
template:
metadata:
labels:
app: tomcat
spec:
tolerations:
- key: "node-role.kubernetes.io/master"
effect: "NoSchedule"
containers:
- name: tomcat
image: "tomcat:7.0"
env: # 注意点一,添加相应的环境变量(下面收集了两块日志1、stdout 2、/usr/local/tomcat/logs/catalina.*.log)
- name: aliyun_logs_tomcat-syslog # 如日志发送到es,那index名称为 tomcat-syslog
value: "stdout"
- name: aliyun_logs_tomcat-access # 如日志发送到es,那index名称为 tomcat-access
value: "/usr/local/tomcat/logs/catalina.*.log"
volumeMounts: # 注意点二,对pod内要收集的业务日志目录需要进行共享,可以收集多个目录下的日志文件
- name: tomcat-log
mountPath: /usr/local/tomcat/logs
volumes:
- name: tomcat-log
emptyDir: {
}
4、部署es 和 kibana
这里的elasticsearch和kibana服务我们就用上节课部署的服务接着使用即可
第25关 利用operator部署生产级别的Elasticserach集群和kibana
5、部署 filebeat 服务
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config-test
data:
filebeat.yml: |
filebeat.inputs:
- type: kafka
hosts: ["10.0.1.201:9092"]
topics: ["tomcat-syslog"]
group_id: "filebeat"
#username: "$ConnectionString"
#password: "<your connection string>"
ssl.enabled: false
filebeat.shutdown_timeout: 30s
output:
elasticsearch:
enabled: true
hosts: ['quickstart-es-http.es:9200']
username: elastic
password: 5e84VTJBPO3H84Ec5xt43fc3
indices:
- index: "test-%{+yyyy.MM.dd}"
logging.level: info
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app-name: filebeat
name: filebeat-test
spec:
replicas: 1
selector:
matchLabels:
app-name: filebeat
template:
metadata:
labels:
app-name: filebeat
spec:
containers:
- command:
- filebeat
- -e
- -c
- /etc/filebeat.yml
env:
- name: TZ
value: Asia/Shanghai
image: docker.io/elastic/filebeat:8.11.3
imagePullPolicy: IfNotPresent
name: filebeat
resources:
limits:
cpu: 100m
memory: 200M
requests:
cpu: 100m
memory: 200M
volumeMounts:
- mountPath: /etc/filebeat.yml
name: filebeat-config
subPath: filebeat.yml
volumes:
- configMap:
defaultMode: 420
name: filebeat-config-test
name: filebeat-config