视频课程地址:https://www.bilibili.com/video/BV1WY4y197g7
课程资料链接:https://pan.baidu.com/s/15KpnWeKpvExpKmOC8xjmtQ?pwd=5ay8
目录
二、在虚拟机里部署HDFS集群
下载Hadoop:https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
本次演示部署结构如下图所示:
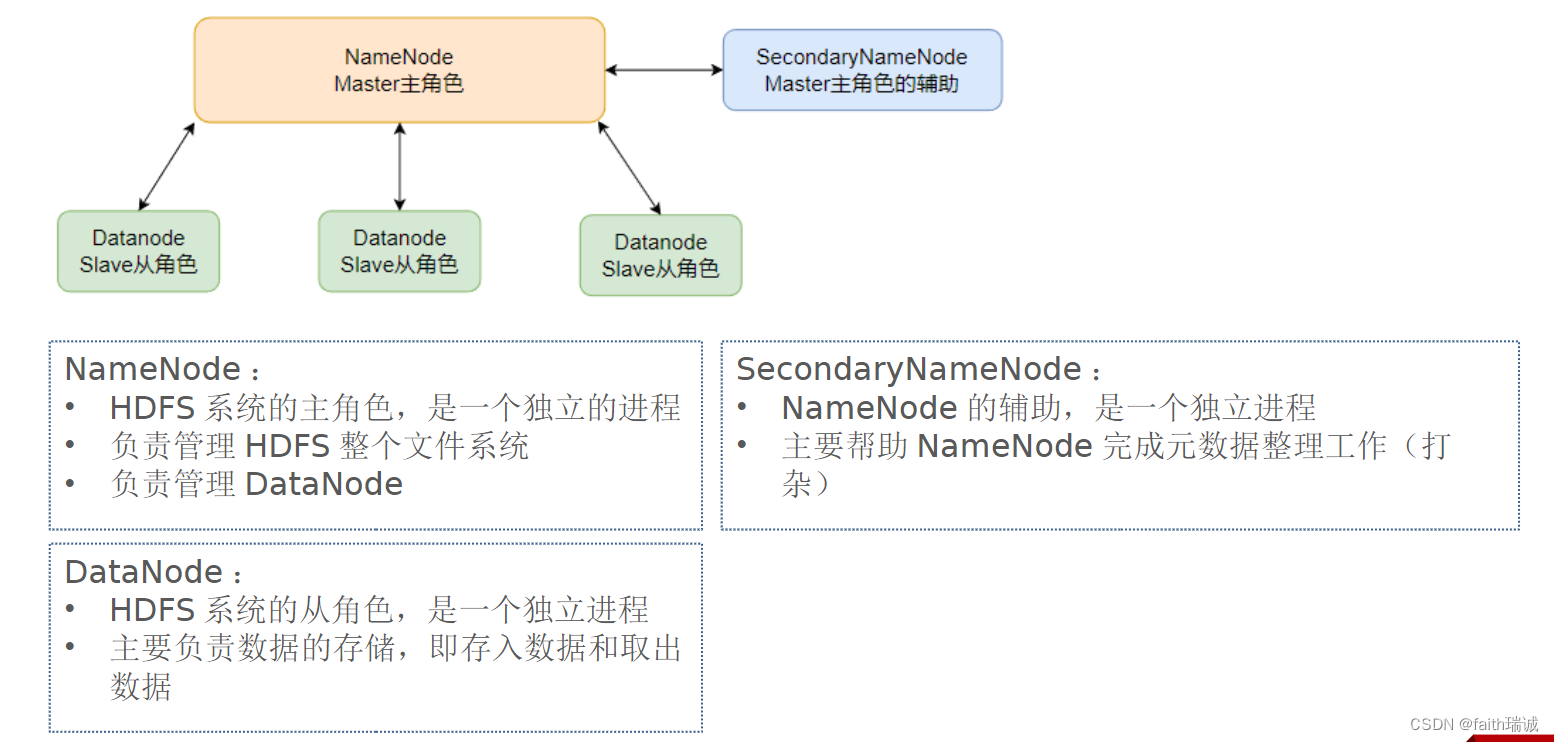
本次部署服务清单如下表所示:
| 节点 | 部署的服务 |
|---|---|
| node1 | NameNode、DataNode、SecondaryNameNode |
| node2 | DataNode |
| node3 | DataNode |
2.1. 部署node1虚拟机
1、将下载好的Hadoop压缩包上传至node1虚拟机的root目录;
2、将Hadoop压缩包解压至/export/server目录下
tar -zxvf hadoop-3.3.4.tar.gz -C /export/server/
3、创建hadoop目录的软链接
# 切换工作目录
cd /export/server/
# 创建软连接
ln -s /export/server/hadoop-3.3.4/ hadoop
4、hadoop目录结构如下

| 目录 | 存放内容 |
|---|---|
| bin | 存放Hadoop的各类程序(命令) |
| etc | 存放Hadoop的配置文件 |
| include | 存放Hadopp用到的C语言的头文件 |
| lib | 存放Linux系统的动态链接库(.so文件) |
| libexec | 存放配置Hadoop系统的脚本文件(.sh和.cmd文件) |
| licenses_binary | 存放许可证文件 |
| sbin | 管理员程序(super bin) |
| share | 存放二进制源码(jar包) |
5、配置workers文件
cd etc/hadoop/
vim workers
将workers文件原有的内容删掉,改为
node1
node2
node3
保存即可;
6、配置hadoop-env.sh文件,使用vim hadoop-env.sh打开,修改以下配置:
# 指明JDK安装目录
export JAVA_HOME=/export/server/jdk
# 指明HADOOP安装目录
export HADOOP_HOME=/export/server/hadoop
# 指明HADOOP配置文件的目录
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
#指明HADOOP运行日志文件的目录
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
7、配置core-site.xml文件,使用vim core-site.xml打开文件,修改以下配置:
<configuration>
<property>
<!--HDFS 文件系统的网络通讯路径-->
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<property>
<!--io 操作文件缓冲区大小-->
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
8、配置hdfs-site.xml文件,修改以下配置:
<configuration>
<property>
<!--hdfs 文件系统,默认创建的文件权限设置-->
<name>dfs.datanode.data.dir.perm</name>
<!-- 700权限即rwx------ -->
<value>700</value>
</property>
<property>
<!--NameNode 元数据的存储位置-->
<name>dfs.namenode.name.dir</name>
<!-- 在 node1 节点的 /data/nn 目录下 -->
<value>/data/nn</value>
</property>
<property>
<!--NameNode 允许哪几个节点的 DataNode 连接(即允许加入集群)-->
<name>dfs.namenode.hosts</name>
<value>node1,node2,node3</value>
</property>
<property>
<!--hdfs 默认块大小-->
<name>dfs.blocksize</name>
<!--268435456即256MB-->
<value>268435456</value>
</property>
<property>
<!--namenode 处理的并发线程数-->
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<!--从节点 DataNode 的数据存储目录,即数据存放在node1、node2、node3三台机器中的路径-->
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
</configuration>
9、根据上一步的配置项,在node1节点创建/data/nn和/data/dn目录,在node2和node3节点创建/data/dn目录;
10、将已配置好的hadoop程序从node1分发到node2和node3:
# 切换工作目录
cd /export/server/
# 将node1的hadoop-3.3.4/目录复制到node2的同样的位置
scp -r hadoop-3.3.4/ node2:`pwd`/
# 将node1的hadoop-3.3.4/目录复制到node3的同样的位置
scp -r hadoop-3.3.4/ node3:`pwd`/
11、将Hadoop加入环境变量,使用vim /etc/profile打开环境变量文件,将以下内容添加在文件末尾:
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行source /etc/profile命令使环境变量配置生效;
12、修改相关目录的权限:
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export/
2.2. 部署node2和node3虚拟机
本小节内容如无特殊说明,均需在node2和node3虚拟机分别执行!
1、为hadoop创建软链接,命令都是一样的,如下所示:
cd /export/server/
ln -s /export/server/hadoop-3.3.4/ hadoop
2、将Hadoop加入环境变量,使用vim /etc/profile打开环境变量文件,将以下内容添加在文件末尾:
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行source /etc/profile命令使环境变量配置生效;
3、修改相关目录的权限:
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export/
2.3. 初始化并启动Hadoop集群(格式化文件系统)
1、在node1虚拟机上执行以下命令:
# 切换为hadoop用户
su - hadoop
# 格式化namenode
hadoop namenode -format
2、启动集群,在node1虚拟机上执行以下命令:
# 一键启动整个集群,包括namenode、secondarynamenode和所有的datanode
start-dfs.sh
# 查看当前系统中正在运行的Java进程,可以看到每台虚拟机上hadoop的运行情况
jps
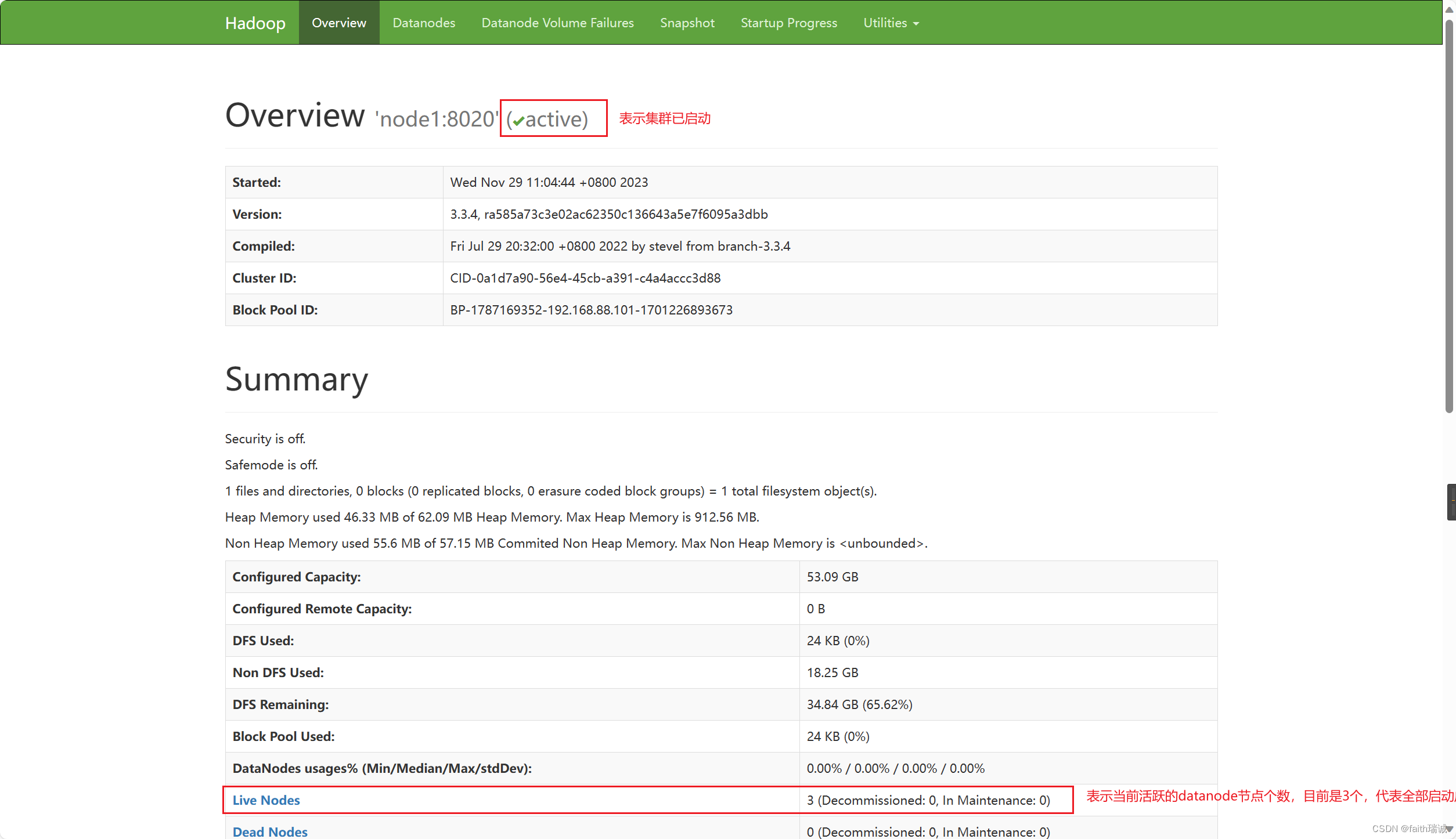
3、执行上述步骤之后,我们可以在我们自己的电脑(非虚拟机)上查看 HDFS WEBUI(即HADOOP管理页面),可以通过访问namenode所在服务器的9870端口查看,在本案例中因为namenode处于node1虚拟机上,所以可以访问http://node1:9870/打开。PS:因为之前我们已经配置了本机的hosts文件,所以这里可以使用node1访问,其实这个地址对应的就是http://192.168.88.101:9870/。
4、如果看到以下界面,代表Hadoop集群启动成功了。
2.4. 快照部署好的集群
为了保存刚部署好的集群,在后续如果出现无法解决的问题,不至于重新部署一遍,使用虚拟机快照的方式进行备份。
1、一键关闭集群,在node1虚拟机执行以下命令:
# 切换为hadoop用户
su - hadoop
# 一键关闭整个集群
stop-dfs.sh
关闭完成后,可以在node1、node2、node3虚拟机中使用jps命令查看相应Java进程是否已消失。
2、关闭三台虚拟机;
3、在VMware中,分别在三台虚拟机上右键,“快照”-“拍摄快照”功能创建快照。
2.5. 部署过程中可能会遇到的问题
- 在以Hadoop用户身份执行
start-dfs.sh命令时,提示Permission denied。此时需要检查三台虚拟机上相关路径(/data、/export/server及其子路径)上hadoop用户是否具有读、写、执行的权限。 - 在执行
start-dfs.sh命令后,使用jps命令可以查看已启动的服务,若发现有服务未启动成功的,可以查看/export/server/hadoop/logs目录下的日志文件,若在日志文件中看到类似于无权限、不可访问等报错信息,同样需要检查对应机器的相关路径权限。 - 执行
hadoop namenode -format、start-dfs.sh、stop-dfs.sh等Hadoop相关命令时,若提示command not found,则代表着环境变量没配置好,需要检查三台机器的/etc/profile文件的内容(需要使用source命令使环境变量生效)以及hadoop的软连接是否正确。 - 执行
start-dfs.sh命令后,node1的相关进程启动成功,但node2和node3没有启动的,需要检查workers文件的配置是否有node2和node3。 - 若在日志文件中看到WstxEOFException或Unexpected EOF等信息,大概率是xml配置文件有问题,需要仔细检查core-site.xml和hdfs-site.xml文件里面的内容(少了某个字母或字符、写错了某个字母或字符),尤其是符号。
综上,常见出错点总结为:
- 权限未正确配置;
- 配置文件错误;
- 未格式化
2.5. Hadoop HDFS集群启停脚本
注意:在使用以下命令前,一定要确保当前是hadoop用户,否则将报错或没有效果!!!
Hadoop HDFS 组件内置了HDFS集群的一键启停脚本。
$HADOOP_HOME/sbin/start-dfs.sh,一键启动HDFS集群
执行流程:- 在执行此脚本的机器上,启动SecondaryNameNode;
- 读取
core-site.xml内容(fs.defaultFS项),确定NameNode所在机器,启动NameNode; - 读取
workers内容,确定DataNode所在机器,启动全部DataNode。
$HADOOP_HOME/sbin/stop-dfs.sh,一键关闭HDFS集群
执行流程:- 在执行此脚本的机器上,关闭SecondaryNameNode;
- 读取
core-site.xml内容(fs.defaultFS项),确定NameNode所在机器,关闭NameNode; - 读取
workers内容,确认DataNode所在机器,关闭全部NameNode。
除了一键启停外,也可以单独控制某个进程的启停。
$HADOOP_HOME/sbin/hadoop-daemon.sh,此脚本可以单独控制所在机器的进程启停
用法:hadoop-daemon.sh (start|status|stop) (namenode|secondarynamenode|datanode)$HADOOP_HOME/sbin/hdfs,此程序也可以单独控制所在机器的进程启停
用法:hdfs --daemon (start|status|stop) (namenode|secondarynamenode|datanode)