import os
import zipfile
import tarfile
import gzip
import hashlib
import pandas as pd
def get_file_list(dir_path):
"""获取指定目录下的所有文件列表"""
file_list = []
for root, dirs, files in os.walk(dir_path):
for file in files:
file_path = os.path.join(root, file)
file_list.append(file_path)
return file_list
def get_file_suffix(file_path):
"""获取文件的后缀名"""
file_name, file_suffix = os.path.splitext(file_path)
return file_suffix
def get_md5(file_path):
"""获取文件的 MD5 校验值"""
md5 = hashlib.md5()
with open(file_path, "rb") as f:
for chunk in iter(lambda: f.read(4096), b""):
md5.update(chunk)
return md5.hexdigest()
def unzip(file_path, target_dir):
"""解压缩文件"""
suffix = get_file_suffix(file_path)
if suffix == ".zip":
return zipfile.ZipFile(file_path).extractall(target_dir)
elif suffix == ".tar":
return tarfile.open(file_path, "r:gz").extractall(target_dir)
elif suffix == ".7z":
return 7zfile.open(file_path, "r").extractall(target_dir)
elif suffix == ".gz":
with gzip.open(file_path, "rb") as f:
return f.read().decode("utf-8")
else:
raise Exception(f"不支持的文件格式:{suffix}")
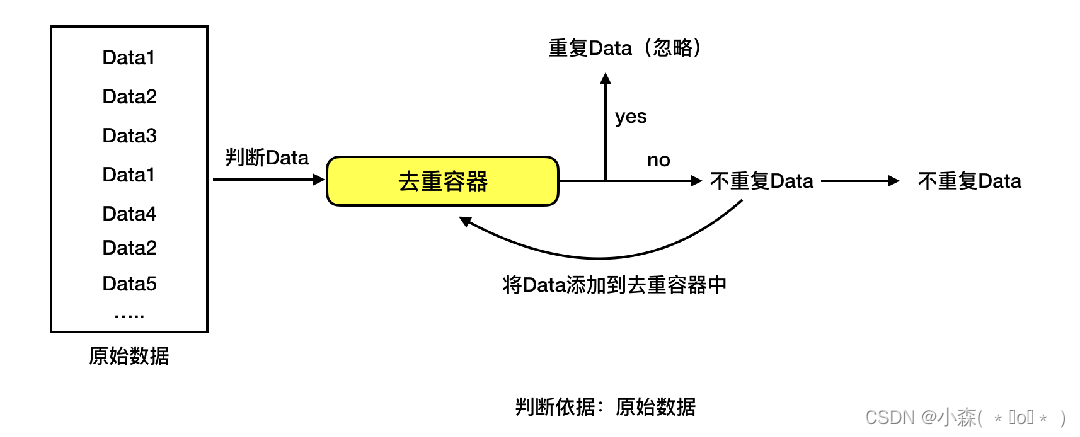
def is_duplicate(file_path, file_map):
"""判断文件是否重复"""
file_size = os.path.getsize(file_path)
file_mtime = os.path.getmtime(file_path)
if file_path in file_map:
if file_map[file_path]["size"] == file_size and file_map[file_path]["mtime"] == file_mtime:
return True
else:
file_map[file_path] = {"size": file_size, "mtime": file_mtime}
return False
def main():
"""主函数"""
# 获取输入参数
cur_dir = os.getcwd()
input_dir = input("请输入需要解压缩的文件存放目录:")
output_dir = input("请输入解压缩后的存放目录:")
# 获取文件列表
file_list = get_file_list(input_dir)
# 创建解压缩后的存放目录
if not os.path.exists(output_dir):
os.mkdir(output_dir)
# 解压缩文件
progress_bar = ProgressBar(len(file_list))
file_map = {}
for file_path in file_list:
file_path = os.path.join(input_dir, file_path)
unzip(file_path, output_dir)
progress_bar.update()
# 去重复文件
for file_path in os.listdir(output_dir):
file_path = os.path.join(output_dir, file_path)
if is_duplicate(file_path, file_map):
os.remove(file_path)
class ProgressBar:
"""进度条类"""
def __init__(self, total):
self.total = total
self.progress = 0
def update(self):
self.progress += 1
sys.stdout.write("\r%.2f%%" % (self.progress / self.total * 100))
sys.stdout.flush()
@property
def finished(self):
return self.progress >= self.total
if __name__ == "__main__":
main()
注意:在运行上述代码之前,您需要确保已经安装了所有必要的库,如pandas、zipfile、tarfile、gzip等。您可以使用以下命令来安装这些库:
pip install pandas zipfile tarfile gzip
此外,由于您的代码中使用了7zfile,但这个库在Python的标准库中不存在,您需要使用第三方库来处理.7z文件。您可以使用py7zr库,它是7z文件的一个Python实现。您可以使用以下命令来安装py7zr:
pip install py7zr